






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:集智书童

单位:悉尼大学(欧阳万里团队), 百度, 商汤, 牛津大学
论文:https://arxiv.org/abs/2108.03428
1简介
在本文中,作者观察到在应用ViT进行图像识别时存在两级冗余。首先,固定整个网络的Token数量会在空间层面产生冗余特征;其次,不同Transformer之间的注意力图是冗余的。
基于上述观察,作者提出了一种PSViT:一种带有Token pooling和Atention共享的ViT以减少冗余的同时有效增强特征表示能力,实现更好的速度-精度权衡。
具体来说,在PSViT中,Token pooling可以定义为在空间级别上减少token数量的操作。并在相邻的Transformer层之间建立Atention共享,以重用相邻层之间相关性较强的Attention Map。然后,为不同的Token pooling和Atention共享机制构建一个紧凑的可能性组合集。基于所提出的compact set可以将每一层的token数量和Atention共享层的选择视为从数据中自动学习的超参数。
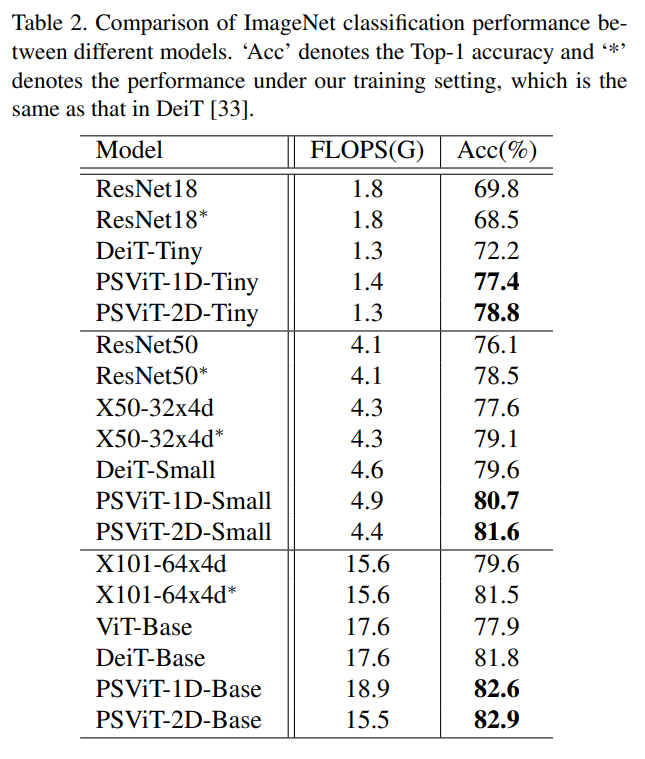
实验结果表明,与DeiT方法相比,该方法在ImageNet分类中准确率提高了6.6%
主要贡献
提出了一种基于Token pooling和Share Attention的PSViT方案,设计更好的视觉Transformer可以有效地增强特征表示;
为Token pooling和Share Attention提出了一组紧凑的设计选择,并在此基础上利用现成的AutoML方法学习最佳设计选择;
综合实验结果表明,与DeiT相比,该算法在ImageNet分类中的准确率提高了6.6%。
2Token Pooling and Sharing for Transformer
2.1 Token Pooling
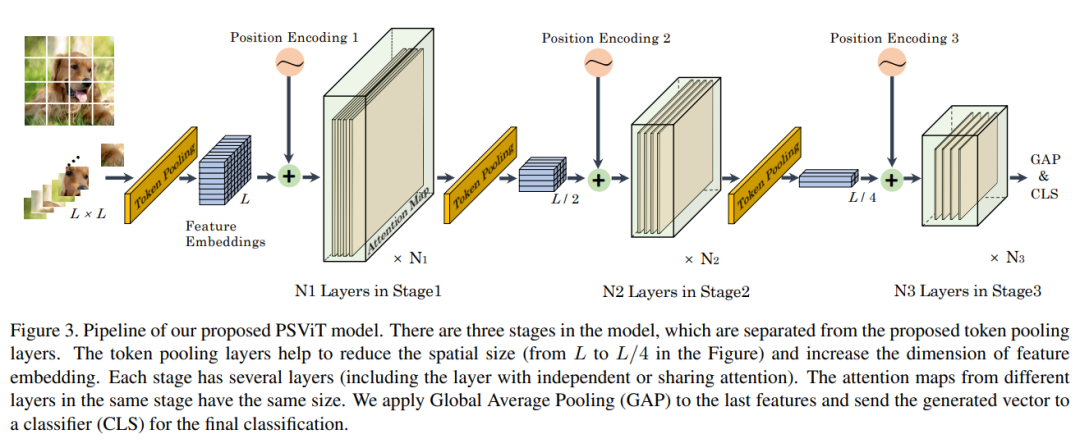
Token Pooling机制调整每个阶段的token数量,如图3所示。当网络深度增加时,本文减少token数量以消除空间冗余,增加特征维数以容纳更多不同的高级特征。
Token Pooling有2种设计选项:
第1种方法:是将图像patch视为1D token,利用额外的CLS token进行分类任务。
第2种方法:是去除CLS token,将图像patch保持在一个2D数组中,这与ResNet中的池化策略相同。
对于第1个策略,通过卷积和Max-Pooling来实现Token Pooling。与只减少token数量不同,本文目标是增强特性表示能力。这里首先利用一维卷积来改变特征维数(即每个token的维数),然后通过一维最大池化来减少token的数量。
作者将采用上述池化策略的网络命名为PSViT-1D。
在第2种策略中,采用stride=2的二维卷积层进行Token Pooling,这在许多卷积网络中得到了广泛的应用。
这里将具有第2种池策略的网络命名为PSViT-2D。
简单地在每一层之后添加一个Token Pooling层会迅速降低模型的表示能力。受到简历深层网络原则的影响,例如VGGNet, ResNet和MobileNet,作者在几层之后添加了一个Pooling层,并用相同的token number作为一个阶段来命名这些层。
Token 维度研究
为了增加ViT的表示能力同时保持其计算开销的FLOPs,可以有两种选择来修改网络结构:
增加token尺寸而减少token数量或保持token 维度,
增加变压器层数。
基于这2种选择对表1中的1D策略进行了一些初步实验,结果表明增加特征维数同时减少token数量是更好的选择。
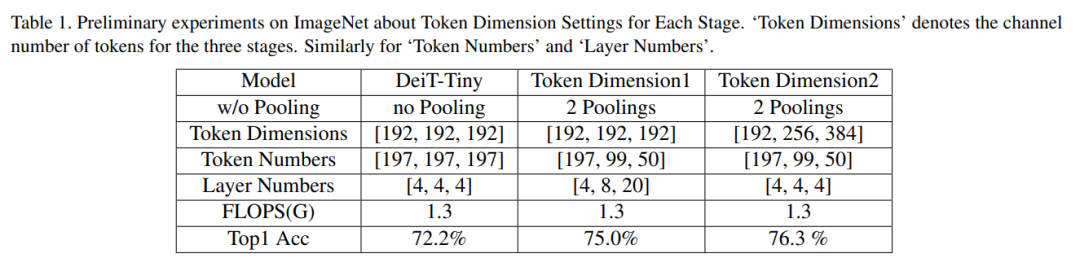
具体来说,在实验中,baseline模型固定特征尺寸,而表1中的Dimension1方案固定token维数,并在各个阶段减少token数量。为了平衡总计算量,增加了几个编码器层。表1中的Dimension2方案增加了token的维数,同时减少了token数量。
这2种方案设计的体系结构遵循计算均匀分布在阶段的原则。从表1中可以看出,这2种token维设计的性能要比通过整个网络固定特征尺寸的DeiT-Tiny模型好得多。在增加特征维数(维数2)的同时减少token数的方法性能最好。
设计选择分析
在CV任务中有2个特点。首先,正如第1节所讨论的,High-level特征在空间层面上具有冗余。因此,通过Token Pooling在空间层面上降低冗余是合理的。表1中的结果支持这一点,其中2个Token Pooling设计比没有Token Pooling的DeiT-Tiny模型性能要好得多。
深层网络中的不同层对不同层次的信息进行编码。低层次的特征,例如边缘和纹理,在浅层可以很少,可以共享来代表高级特征。相反,高层次的特征,例如不同视角的属性或对象,在更深层次上更难以共享。因此,大多数CNN的设计,如VGGNet、ResNet和MobileNet遵循的规则是越深层特征维度越高。表1中的结果也验证了这一点,其中在维度2中增加更深层次的特征维比在维度1中固定特征维表现得更好。
2.2 Attention Sharing
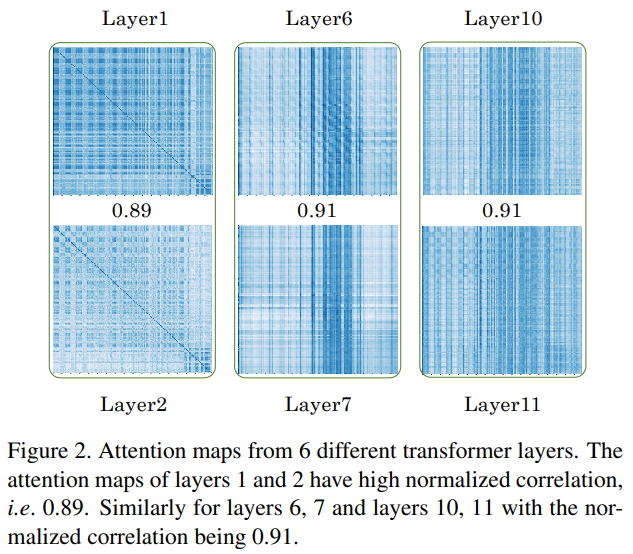
如图所示,连续多注意层次中的attention map是相似的。其中一个原因是,在transformer中使用了标识映射,并使用残差。在这种情况下,主要特征虽然被残差改变了,但不会有很大的变化。因此,相邻层的特征会彼此相似,从而产生相似特征之间的attention map。这种相似性导致了冗余。因此,采用一些共享机制来减少冗余,同时减少计算量。
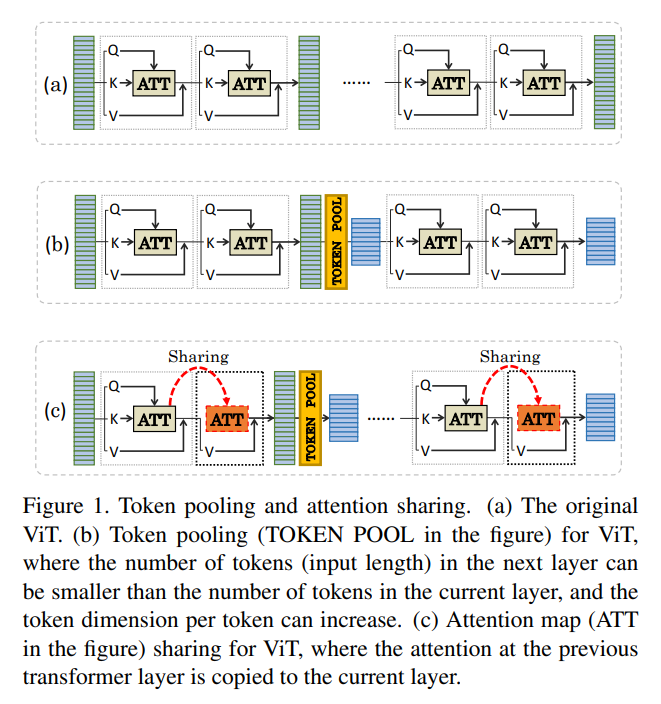
具体来说,通过图(c)所示的相邻层之间的注意力计算过程来实现注意力共享的目的。如果一层重用了前一层的注意力分数,那么就不计算注意力分数以及Q和K。前面一层计算出的attention作为这一层的输入attention计算的整个过程。self-attention被简化为V与输入注意力分数的点积。
Attention Sharing可以帮助消除相邻transformer层之间attention map冗余。另一方面,一些相邻的图层可能具有非常不同的功能,共享它们的注意力图就不那么有效了。考虑到这一点,应该提供灵活性,使整个ViT仍然可以选择使用原来的多头注意力模块,而不sharing attention map。因此,在设计transformer整体架构时将Attention Sharing模块作为对原有独立多头注意力模块的可选方案。
3AutoML Enhanced Transformer
3.1 Search Space for PSViT
如前所述,token pooling是指在空间层面上减少token数量,增加每个token的特征通道数量的操作,这种操作可能会极大地影响特征的表示能力。因此,在ViT中特别考虑它的不同形式。
每个阶段的设计选择主要包括3个因素:
token数量 ,
token维数 ,
每个阶段的层数 。
为了得到这3个因素的最优选择构建了一个对它们有多个选择的搜索空间。搜索空间中的每个元素都将产生一个新的transformer候选网络体系结构。
在每一层中,token数量有 种可能的选择,token维度有 种可能的选择,每个map使用attention map有 种可能的选择。对于L层,仅考虑token pooling的搜索空间将包含 候选设计。例如,当 = 4, = 4, = 4, L= 36时,大约有 个选项,约 倍的SPOS方法的大小。相比之下,SPOS每层有4个选择,而这个搜索空间每层有64个。这个搜索空间太大,每一层都有太多的选择。使用搜索算法从这个搜索空间中获得最好的架构花费了太多的时间。此外,每一层的选择过多可能会使现有的快速搜索算法失效。因此,需要缩小搜索空间。
设计搜索空间的原因如下:
根据3.2.1节的分析,随着深度的增加,token维数增加,token数减少。这有助于通过删除不符合此规则的网络架构来减少搜索空间;
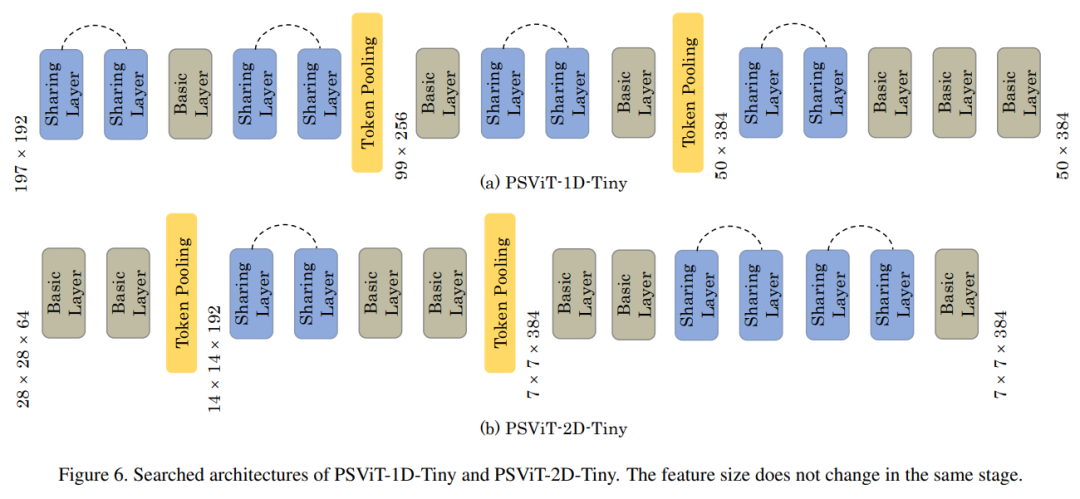
遵循成熟的CNN设计,限制一个阶段中的多个层具有相同数量的token和相同的token维度。为了减少搜索算法所需的搜索空间和计算量,只使用了token pooling的3个阶段;
对于每个阶段的层数,只考虑有限的层数,进一步减少搜索空间和计算量;
为不同的层次提供了应用注意力共享或不共享的灵活性。
网络设计搜索空间
如果将每个阶段的层次数量和注意力图共享设置作为网络的超参数,那么学习它们的自然选择就是基于RL或EA的方法,这在搜索过程中非常缓慢。
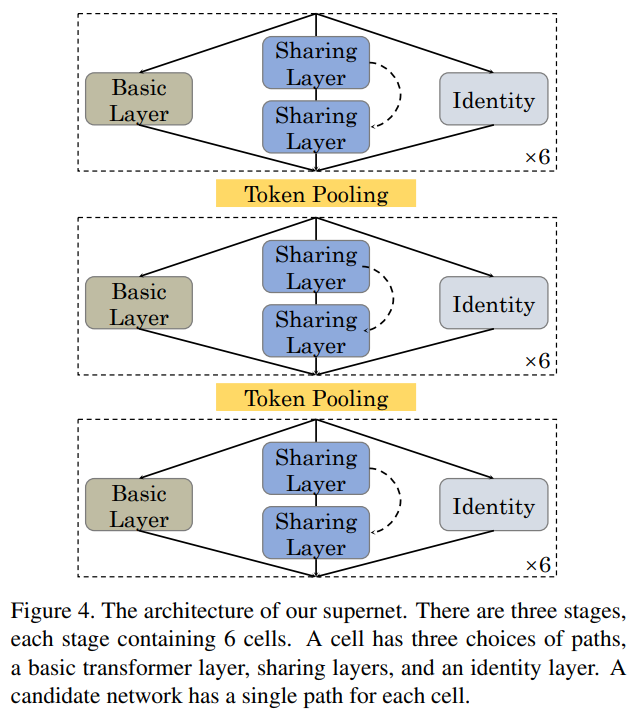
因此,作者采用基于权值共享的方法作为本文的搜索算法,这需要定义一个supernet来囊括搜索空间中的所有候选架构。一种可能的supernet设计如图所示。supernet有3个阶段。在阶段之间放置一个token pooling层,以更改token number和特性维度。
每个阶段有6个单元,其中一个单元有3个路径选择,1个基本的transformer层,2个共享层(第1个transformer层的注意力映射被复制到第2层)和identity映射。
候选体系结构可以为每个单元独立地从3个选择中选择一条路径。通过包含identity映射,候选网络可以有0到36(所有单元选择共享层)transformer层。这种supernet设计为transformer架构提供了更大的可行性。
例如,候选对象只能为所有层选择基本层,这相当于2个token pooling层增强的transformer。作为另一个例子,一个候选架构可以在第一阶段为所有的前6个单元选择共享层路径,并为其余单元选择token,它有12个transformer层,每2层共享注意力图,但没有token pooling。
3.2 AutoML for the Searching
Training the supernet
前面构建的supernet包含了所有候选网络。对于supernet的每个单元都有多种选择。通过激活每个细胞中的一个选择,就可以构建一个候选网络。在训练过程中,SPOS对每次训练迭代进行统一采样,只选择一个候选网络,并在supernet中更新所选候选网络的参数。候选网络将继承supernet的训练参数,并不断更新这些参数。一旦supernet被训练,所有的候选网络都可以继承它的权值,而不需要从头开始进行搜索训练。
Searching from the trained supernet
对supernet进行训练后,将进化方法进一步应用于supernet中的所有候选网络,得到最佳的候选网络结构。
4实验
4.1 Classification实验
4.2 Object Detection & Instance Segmentation

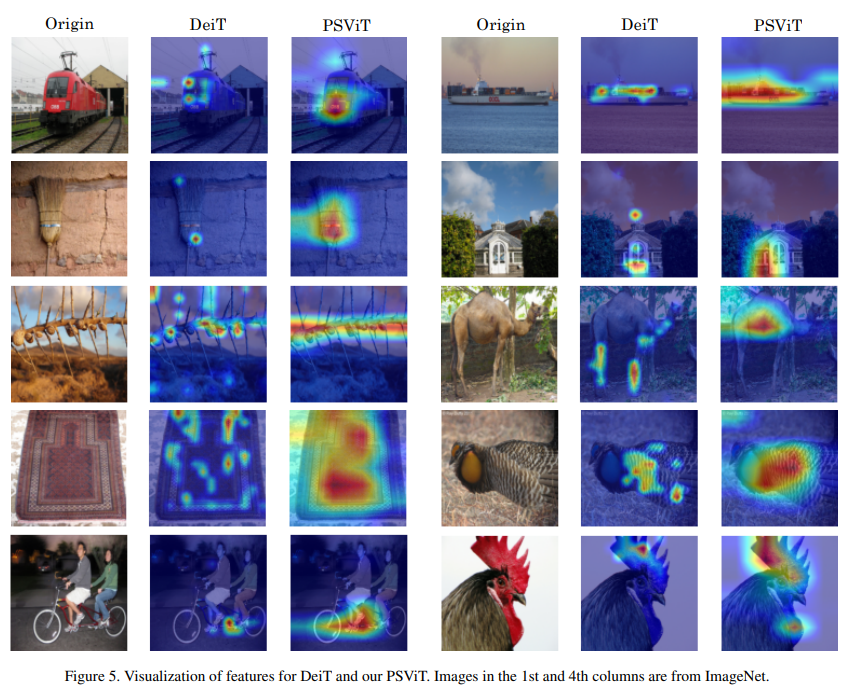
4.3 可视化
5参考
[1].PSViT: Better Vision Transformer via Token Pooling and Attention Sharing
论文PDF下载
后台回复:PSViT,即可下载上述论文PDF
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看















 2152
2152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









