






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童
 MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
论文:https://arxiv.org/abs/2110.02178
MobileviT是一个用于移动设备的轻量级通用可视化Transformer,据作者介绍,这是第一次基于轻量级CNN网络性能的轻量级ViT工作,性能SOTA!。性能优于MobileNetV3、CrossviT等网络。
作者单位:Apple
1简介
轻量级卷积神经网络(CNN)是移动视觉任务的实际应用。他们的空间归纳偏差允许他们在不同的视觉任务中以较少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表征,采用了基于自注意力的Vision Transformer(ViTs)。与CNN不同,ViT是heavy-weight。
在本文中,本文提出了以下问题:是否有可能结合CNN和ViT的优势,构建一个轻量级、低延迟的移动视觉任务网络?
为此提出了MobileViT,一种轻量级的、通用的移动设备Vision Transformer。MobileViT提出了一个不同的视角,以Transformer作为卷积处理信息。
实验结果表明,在不同的任务和数据集上,MobileViT显著优于基于CNN和ViT的网络。
在ImageNet-1k数据集上,MobileViT在大约600万个参数的情况下达到了78.4%的Top-1准确率,对于相同数量的参数,比MobileNetv3和DeiT的准确率分别高出3.2%和6.2%。
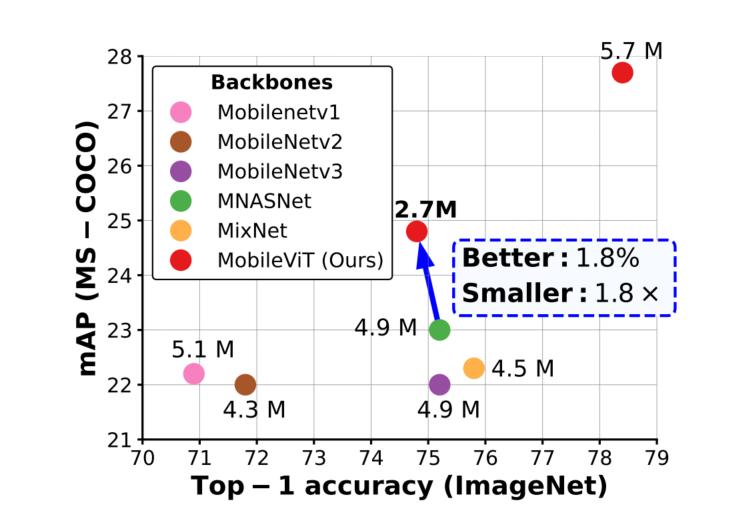
在MS-COCO目标检测任务中,在参数数量相近的情况下,MobileViT比MobileNetv3的准确率高5.7%。
2相关工作
2.1 轻量化CNN模型
CNN的基本构建层是标准的卷积层。由于这一层的计算成本很高,人们提出了几种基于因子分解的方法,使其变得轻量化以方便移动设备的部署。
其中,深度可分离卷积引起了人们的兴趣,并被广泛应用于最先进的轻量级CNN移动视觉任务,包括MobileNets、ShuffleNetv2、ESPNetv2、MixNet和MNASNet。这些轻量级CNN是多功能的,易于训练。
例如,这些网络可以很容易地取代现有特定任务模型(如DeepLabv3)中的heavyweight backbones(如ResNet),以减少网络规模并降低延迟。尽管有这些好处,但这些方法的一个主要缺点是它们在空间上是局部的。
这项工作将Transformer视为卷积;允许利用卷积和Transformer(例如,全局处理)的优点来构建轻量级和通用ViT模型。
2.2 Vision Transformer
Vision Transformer应用于大尺度图像识别,结果表明,在超大尺度数据集(如JFT-300M)下,ViTs可以实现CNN级的精度,而不存在图像特异性的归纳偏差。
通过广泛的数据增强、大量的L2正则化和蒸馏,可以在ImageNet数据集上训练ViT,以实现CNN级别的性能。然而,与CNN不同的是ViT的优化性能不佳,而且很难训练。
后续研究表明,这种较差的优化性是由于ViT缺乏空间归纳偏差所导致的。在ViT中使用卷积来合并这种偏差可以提高其稳定性和性能。人们探索了不同的设计来获得卷积和Transformer的好处。
例如,ViT-C为ViT前阶段增加了一个卷积Backbone。
CvT改进了Transformer的Multi-Head Attention,并使用深度可分离卷积代替线性投影。
BoTNet用Multi-Head Attention取代了ResNet Bottleneck unit的标准卷积。
ConViT采用gated positional Self-Attention的soft convolutional归纳偏差。
PiT使用基于深度卷积的池化层扩展了ViT。
虽然这些模型使用data augmentation可以达到与CNN差不多的性能,但是这些模型大多数是heavy-weight。例如,PiT和CvT比EfficientNet多学习6.1倍和1.7倍的参数,在ImageNet-1k数据集上取得了相似的性能(top-1的准确率约为81.6%)。
此外,当这些模型被缩小以构建轻量级ViT模型时,它们的性能明显比轻量级CNN性能差。对于大约600万的参数预算,PiT的ImageNet-1k精度比MobileNetv3低2.2%。
2.3 讨论
与普通的ViT相比,将卷积和Transformer相结合可以得到鲁棒的高性能ViT。然而,一个开放的问题是:如何结合卷积和变压器的力量来构建轻量级网络的移动视觉任务?
这篇文章的重点是设计轻量的ViT模型,通过简单的训练胜过最先进的模型。为此,作者设计了MobileViT,它结合了CNN和ViT的优势构建了一个轻量级、通用和移动设备友好的网络模型。
MobileViT带来了一些新的观察结果:
更好的性能:在相同参数情况下,与现有的轻量级CNN相比,MobileViT模型在不同的移动视觉任务中实现了更好的性能;
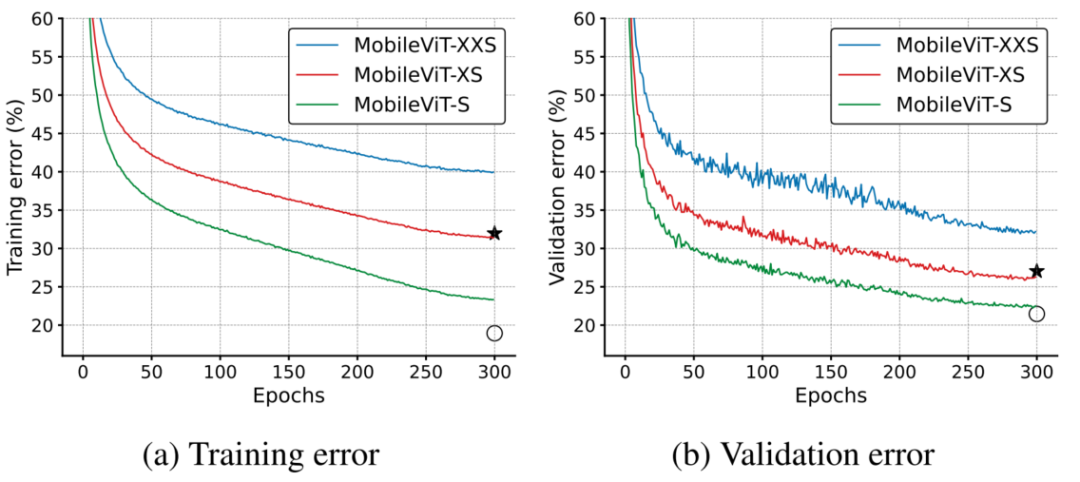
更好的泛化能力:泛化能力是指训练和评价指标之间的差距。对于具有相似训练指标的2个模型,具有更好评价指标的模型更具有通用性,因为它可以更好地预测未见数据集。与CNN相比,即使有广泛的数据增强,其泛化能力也很差,MobileViT显示出更好的泛化能力(下图)。
更好的鲁棒性:一个好的模型应该对超参数具有鲁棒性,因为调优这些超参数会消耗时间和资源。与大多数基于ViT的模型不同,MobileViT模型使用基本增强训练,对L2正则化不太敏感。
3Mobile-ViT
3.1 问题阐述
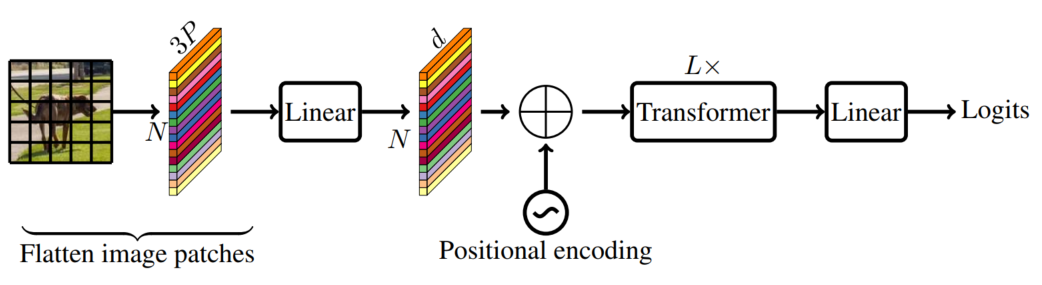
如下图所示,一个标准的ViT模型将输入 Reshape为patches ,将其投影到固定的d维空间,然后使用L个Transformer Block学习Patches之间的表征。
vision transformers中的Self-Attention的计算成本是。其中,C、H、W分别表示张量的通道、高度和宽度,为高度H、宽度W的patch中的像素数,N为patch的数量。
由于这些模型忽略了CNN模型固有的空间归纳偏差,所以它们需要更多的参数来学习视觉表征。例如,与基于CNN的网络DeepLabv3相比,基于ViT的网络DPT多学习了6倍的参数才可以提供相似的分割性能(DPT vs DeepLabv3:345 M vs. 59 M)。此外,与CNN相比,这些模型的优化性能不佳。这些模型对L2正则化很敏感,需要大量的数据增强以防止过拟合。
3.2 Mobile-Block
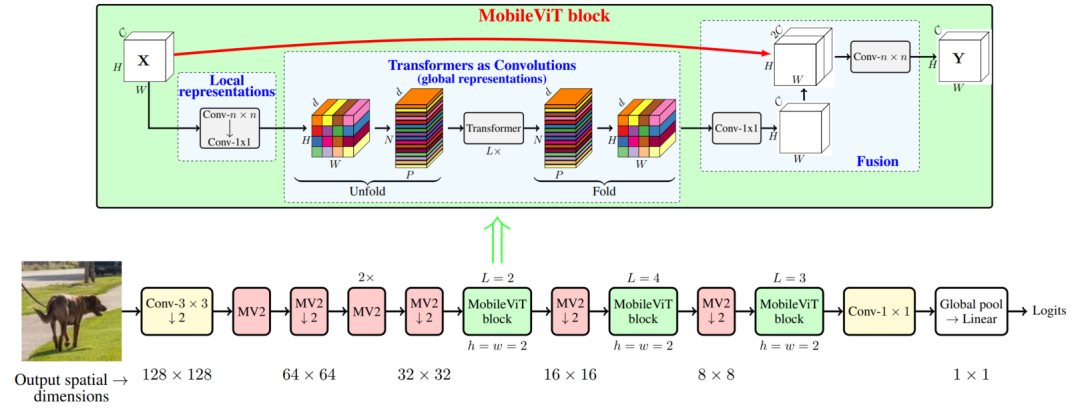
MobileViT Block如下图所示,其目的是用较少的参数对输入张量中的局部和全局信息进行建模。
形式上,对于一个给定的输入张量, MobileViT首先应用一个n×n标准卷积层,然后用一个一个点(或1×1)卷积层产生特征。n×n卷积层编码局部空间信息,而点卷积通过学习输入通道的线性组合将张量投影到高维空间(d维,其中d>c)。
通过MobileViT,希望在拥有有效感受野的同时,对远距离非局部依赖进行建模。一种被广泛研究的建模远程依赖关系的方法是扩张卷积。然而,这种方法需要谨慎选择膨胀率。否则,权重将应用于填充的零而不是有效的空间区域。
另一个有希望的解决方案是Self-Attention。在Self-Attention方法中,具有multi-head self-attention的vision transformers(ViTs)在视觉识别任务中是有效的。然而,vit是heavy-weight,并由于vit缺乏空间归纳偏差,表现出较差的可优化性。
为了使MobileViT能够学习具有空间归纳偏差的全局表示,作者将展开为N个non-overlapping flattened patches 。其中P=wh,N=HW/P为patch的个数,h≤N, w≤N分别为patch的高度和宽度。,通过应用Transformer来编码patch间的关系:
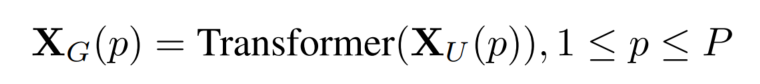
与丢失像素空间顺序的vit不同,MobileViT既不丢失patch顺序,也不丢失每个patch内像素的空间顺序(上图)。因此,可以将折叠得到。然后,通过逐点卷积投影到低维空间(C维),并通过cat操作与X结合。
然后使用另一个n×n卷积层来融合级联张量中的局部和全局特征。注意,因为使用卷积对n×n区域的局部信息进行编码,而对于第P个位置的P个patch对全局信息进行编码, 中的每个像素可以对X中所有像素的信息进行编码,如下图所示。因此,MobileViT的整体有效接受域为H×W。

在图中中,红色像素通过Transformer处理蓝色像素(其他patch中相应位置的像素)。因为蓝色像素已经使用卷积对邻近像素的信息进行了编码,这就允许红色像素对图像中所有像素的信息进行编码。在这里,黑色和灰色网格中的每个单元分别表示一个patch和一个像素。
1、与CNN的关系
标准卷积可以看作是3个顺序操作的堆叠:
展开,
矩阵乘法(学习局部表示)
折叠。
MobileViT Block与卷积相似,因为它也利用了相同的构建块。MobileViT Block将卷积中的局部处理(矩阵乘法)替换为更深层次的全局处理(一个Transformer层堆栈)。因此,MobileViT具有类似于卷积的属性(例如,空间偏差)。因此,MobileViT Block可以看作是Transformer的卷积。
这么设计的简单的一个优势是,卷积和Transformer的低层次高效实现可以开箱即用;允许在不同的设备上使用MobileViT而不需要任何额外的负担。
2、为什么是Light-Weight?
MobileViT Block使用标准卷积和Transformer分别学习局部和全局表示。因为之前的工作表明,使用这些层设计的网络是heavy-weight,一个自然的问题出现了:为什么MobileViT是轻量级的?
作者认为问题主要在于通过Transformer学习全局表示。对于给定的patch,之前的工作是通过学习像素的线性组合将空间信息转化为潜在信息(图1a)。然后,通过使用Transformer对全局信息进行编码学习patches之间信息。因此,这些模型失去了图像特定的归纳偏差(CNN模型固有的特点)。
因此,需要更多的参数来学习视觉表征。所以那些模型又深又宽。与这些模型不同的是,MobileViT使用卷积和Transformer的方式是,生成的MobileViT Block具有类似卷积的属性,同时允许全局处理。这种建模能力能够设计出浅而窄的MobileViT模型,从而使其weight更轻。
与基于ViT的DeiT模型(L=12和d=192)相比,MobileViT模型在空间层面分别使用了32×32、16×16和8×8的和。由此产生的MobileViT网络比DeiT网络更快(1.85×),更小(2×),更好(+1.8%)。
3、计算复杂度
MobileViT和vit中multi-head self-attention的计算成本分别为和。理论上,与vit相比,MobileViT效率较低。然而,在实践中,MobileViT比vit更有效率。
4、MobileViT架构
受到轻量级CNN的启发。作者用3种不同的网络规模(S:小,XS:特别小,XXS:特别小)训练MobileViT模型,这3种网络规模通常用于移动视觉任务(图3c)。
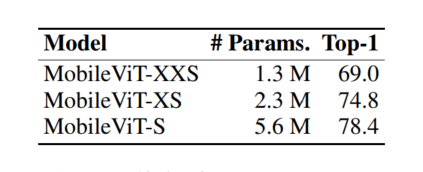
MobileViT的初始层是一个stride=3×3的标准卷积,其次是MobileNetv2(或MV2) Block和MobileViT Block。使用Swish作为激活函数。跟随CNN模型,在MobileViT块中使用n=3。
特征图的空间维数通常是2和h的倍数。因此,在所有空间层面设h=w=2。MobileViT网络中的MV2块主要负责降采样。因此,这些块在MobileViT网络中是浅而窄的。下图中MobileViT的Spatiallevel-wise参数分布进一步说明了在不同的网络配置中,MV2块对总网络参数的影响非常小。

3.3 多尺度采样训练
在基于ViT的模型中,学习多尺度表示的标准方法是微调。例如,在不同尺寸上对经过224×224空间分辨率训练的DeiT模型进行了独立微调。由于位置嵌入需要根据输入大小进行插值,而网络的性能受插值方法的影响,因此这种学习多尺度表示的方法对vit更有利。与CNN类似,MobileViT不需要任何位置嵌入,它可以从训练期间的多尺度输入中受益。
先前基于CNN的研究表明,多尺度训练是有效的。然而,大多数都是经过固定次数的迭代后获得新的空间分辨率。
例如,YOLOv2在每10次迭代时从预定义的集合中采样一个新的空间分辨率,并在训练期间在不同的gpu上使用相同的分辨率。这导致GPU利用率不足和训练速度变慢,因为在所有分辨率中使用相同的批大小(使用预定义集中的最大空间分辨率确定)。
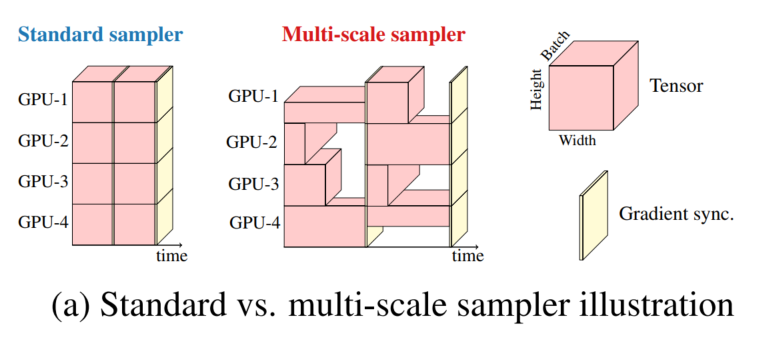
为了便于MobileViT在不进行微调的情况下学习多尺度表示,并进一步提高训练效率(即更少的优化更新),作者将多尺度训练方法扩展到可变大小的Batch-Size。给定一组排序的空间分辨率和Batch-Size b,最大空间分辨率为,在每个GPU上随机采样空间分辨率,并计算第t次迭代的Batch-Size为:。因此,更大的Batch-Size用于更小的空间分辨率。这减少了优化器每个epoch的更新,有助于更快的训练。
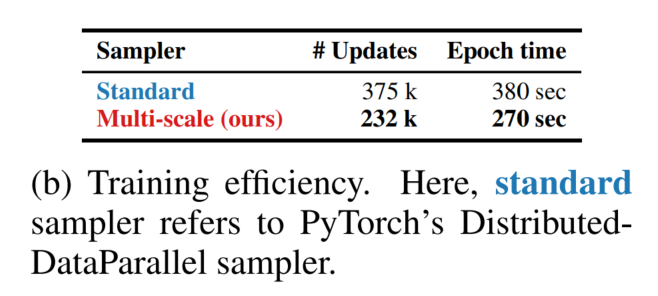
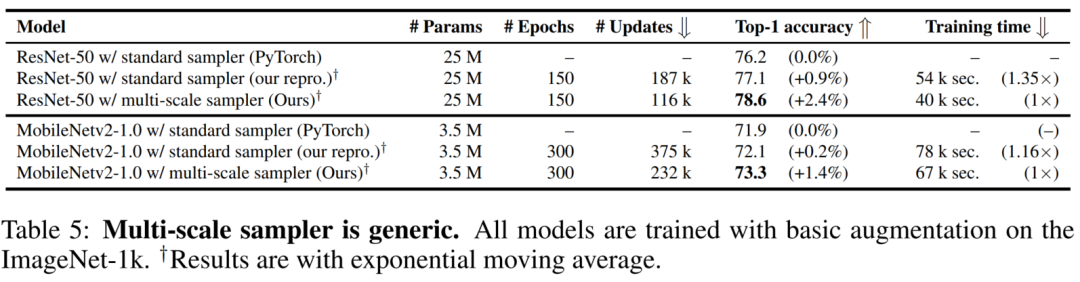
上图比较了标准采样器和多尺度采样器。在这里,将PyTorch中的distributed-dataparelles称为标准采样器。总体而言,多尺度采样器:
减少了训练时间,因为它需要更少的优化器更新不同大小的Batch-size;
提高了约0.5%的性能(下图);

促使网络学习更好的多尺度表征,即在不同的空间分辨率下评估相同的网络,与使用标准采样器训练的网络相比,具有更好的性能。
Pytorch复现如下:

作者还进行了通用化实验说明了多尺度采样器是通用的,并改善了CNN如MobileNetv2)的性能。
4实验结果
4.1 ImageNet-1K
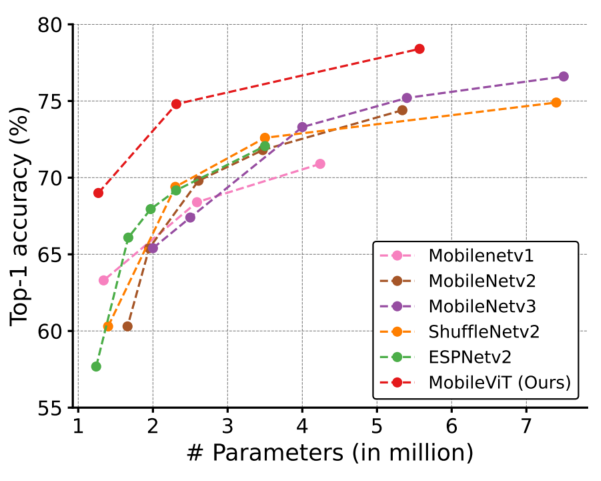
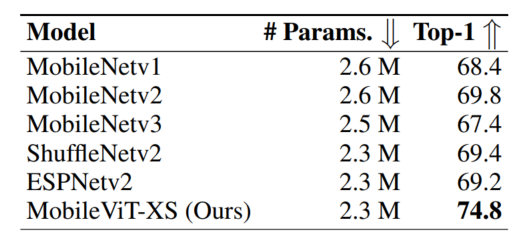

图4.1显示了MobileViT在不同网络规模(MobileNetv1、MobileNetv2、ShuffleNetv2、ESPNetv2和MobileNetv3)上的性能优于轻量级CNN。例如,对于一个大约有250万个参数的模型(图4.2),在ImageNet-1k验证集上,MobileViT比MobileNetv2、ShuffleNetv2和MobileNetv3的性能分别高出5.0%、5.4%和7.4%。
图4.3进一步显示,MobileViT提供了比Heavy-weight CNN(ResNet, DenseNet, ResNet-se和EfficientNet)更好的性能。例如,对于相同数量的参数,MobileViT比effentnet的准确率高出2.1%。
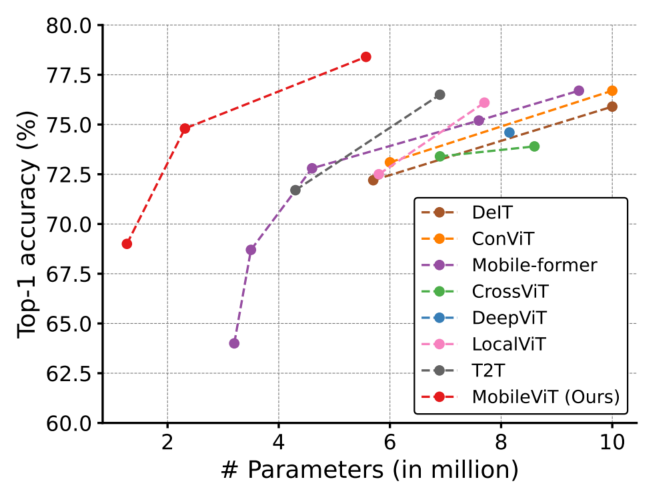
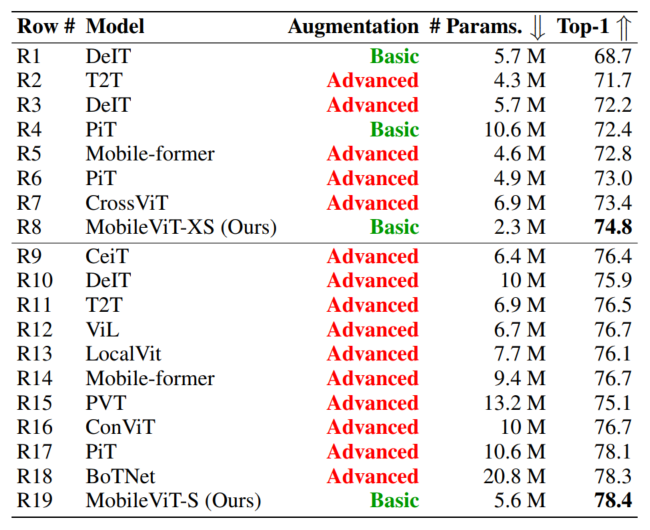
图4.4比较了MobileViT和在ImageNet-1k数据集上从头开始训练的ViT变体(DeIT、T2T、PVT、CAIT、DeepViT、CeiT、CrossViT、LocalViT、PiT、ConViT、ViL、BoTNet和Mobile-former)。
不像ViT变体,显著受益于高级的数据增强(例如,PiT w/ basic vs. advanced: 72.4%(R4) vs. 78.1%(R17);图4.5), MobileViT通过更少的参数和基本的增强实现了更好的性能。例如,MobileViT比DeiT小2.5,好2.6%。
总的来说,这些结果表明,与CNN相似,MobileViTs易于优化和鲁棒性强。因此,它们可以很容易地应用于新的任务和数据集。
4.2 目标检测任务
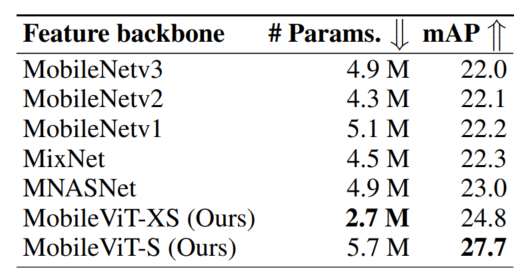
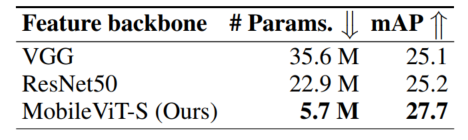
图4.6显示,在320×320的相同输入分辨率下,基于MobileViT的SSDLite与其他轻型CNN模型(MobileNetv1、MobileNetv2、MobileNetv3、MNASNet和MixNet)相比,性能更好。
例如,当使用MobileViT而不是MNASNet作为Backbone时,SSDLite的性能提高了1.8%,其模型尺寸减少了1.8×。此外,基于MobileViT的SSDLite性能优于Heavy-CNN Backbone的标准SSD-300,同时学习的参数明显更少。
4.3 语义分割任务
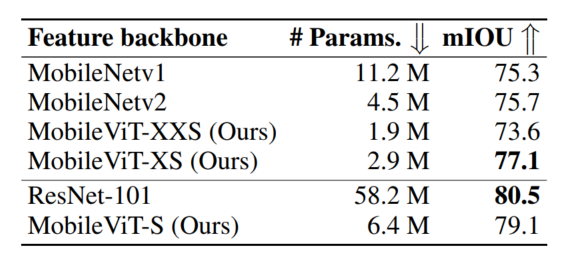
图4.8显示了带有MobileViT的DeepLabv3更小更好。使用MobileViT代替MobileNetv2作为Backbone时,DeepLabv3的性能提高了1.4%,体积减少了1.6×。此外,MobileViT提供了具有竞争力的性能与模型renet-101相比,所需参数减少了9倍。
上述论文PDF下载
后台回复:MobileViT,即可下载上述论文
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()














 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









