






 本文提出SCConv模块,通过空间重构和通道重构单元减少CNN的冗余特征,实验证明其在保持高精度的同时降低计算成本。实验结果显示SCConv在ImageNet上优于SOTA方法。
本文提出SCConv模块,通过空间重构和通道重构单元减少CNN的冗余特征,实验证明其在保持高精度的同时降低计算成本。实验结果显示SCConv在ImageNet上优于SOTA方法。
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:玉米爆米花(源:知乎)| 编辑:CVer公众号
https://zhuanlan.zhihu.com/p/655851980

在CVer微信公众号后台回复:SCConv,可以下载本论文pdf和代码
论文地址:
https://openaccess.thecvf.com/content/CVPR2023/papers/Li_SCConv_Spatial_and_Channel_Reconstruction_Convolution_for_Feature_Redundancy_CVPR_2023_paper.pdf
代码:https://github.com/cheng-haha/ScConv
文章发布:
https://linkyou.top/archives/123
介绍
本文作者提出了一种名为 SCConv(Spatial and Channel reconstruction Convolution, 空间和通道重建卷积)的卷积模块,目的是减少卷积神经网络中特征之间的空间和通道冗余,从而压缩CNN模型并提高其性能。
作者设计的 SCConv 模块,包含两个单元。一个名为 SRU (Spatial Reconstruction Unit, 空间重构单元) ,一个名为 CRU (Channel Reconstruction Unit, 通道重构单元) 。其中 SRU 通过 分离-重构方法 来减少空间冗余,CRU 则使用 分割-转换-融合方法 来减少通道冗余。这两个单元协同工作,以减少CNN中特征的冗余信息。
作者指出,SCConv 是一种可以直接替代标准卷积操作的插件式卷积模块 ,可以应用于各种卷积神经网络中,从而降低冗余特征并减少计算复杂性。
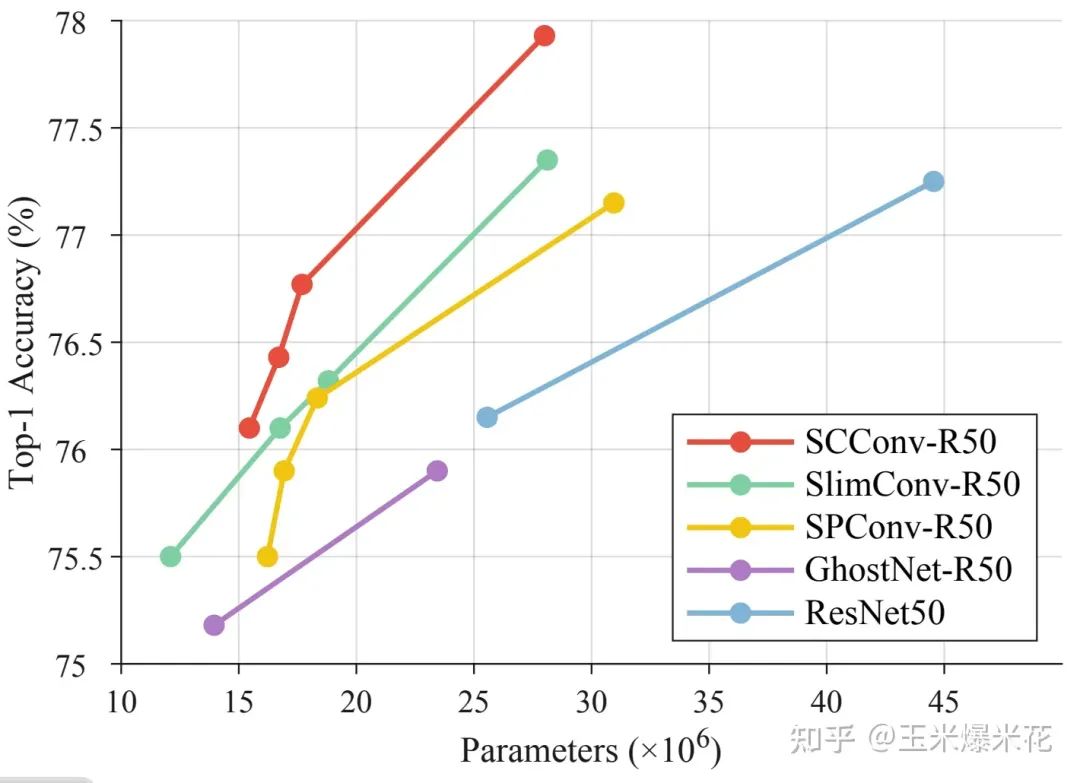
在后续的实验中,文章作者认为相对于其他流行的 SOTA 方法,他们提出的 SCConv 可以以更低的计算成本获得更高的准确率。下图是 ResNet50 在 ImageNet 上的 Top1 准确性测试结果。
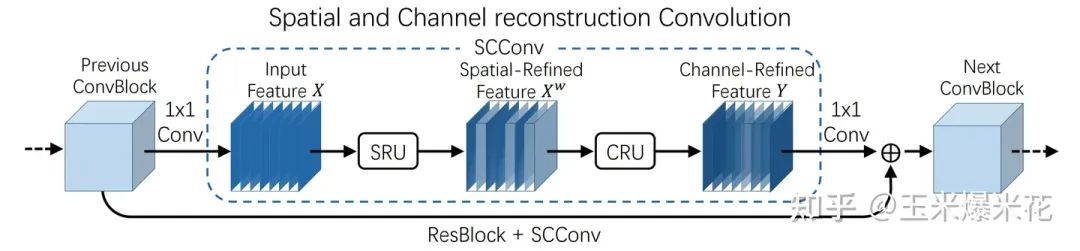
 模块设计
模块设计
SCConv
如下图,SCConv 由两个单元组成,即空间重构单元 (SRU) 和信道重构单元 (CRU) ,两个单元按顺序排列。输入的特征 X 先经过 空间重构单元 ,得到空间细化的特征Xw 。再经过 通道重构单元 ,得到通道提炼的特征 Y 作为输出。
SCConv 模块利用了特征之间的空间冗余和信道冗余,模块可以无缝集成到任何 CNN 框架中,减少特征之间的冗余,提高 CNN 特征的代表性。
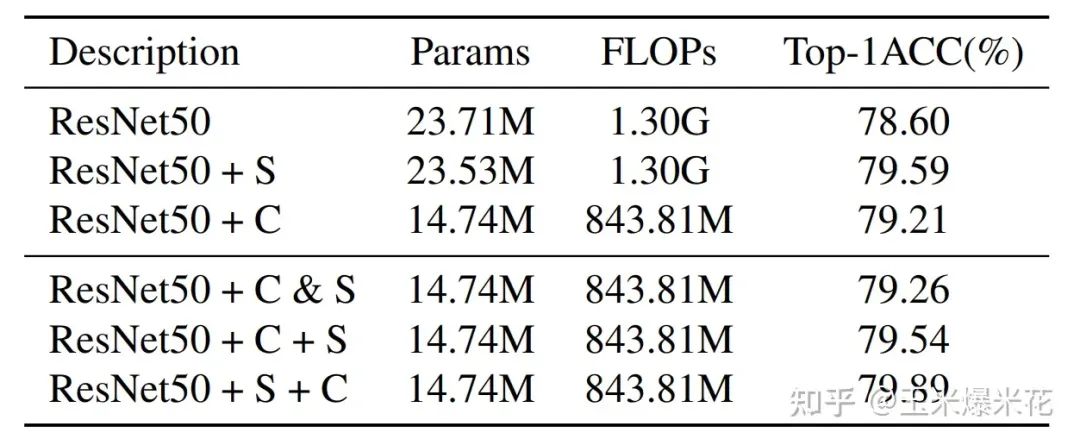
作者对 SRU 和 CRU 进行不同的组合,包括:
不使用 SRU 和 CRU
单独使用 SRU
单独使用 CRU
并行使用 SRU 和 CRU
先使用 CRU 再使用 SRU
先使用 SRU 在使用 CRU
最终发现先使用 SRU 再使用 CRU 的效果最好。
下面详细介绍 SRU 和 CRU 这两个单元。
SRU 空间重建单元
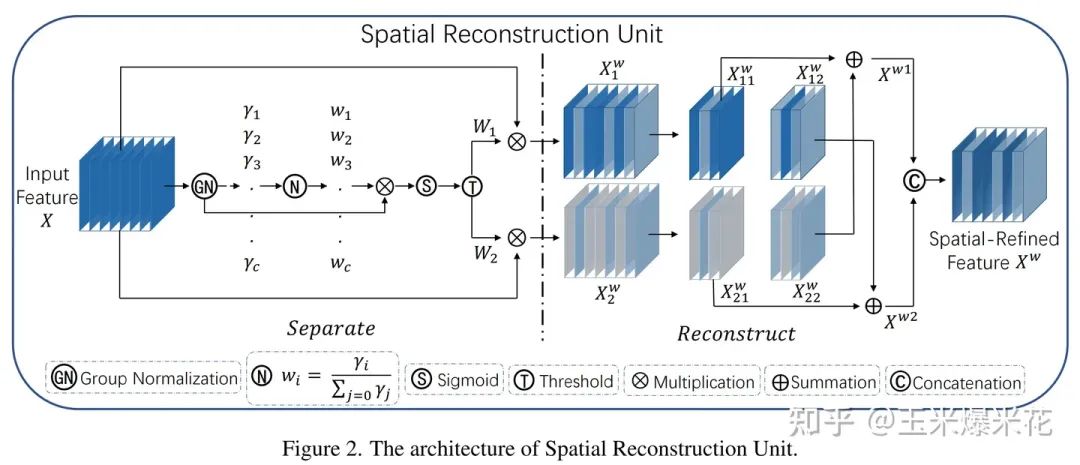
在作者的设计中,该单元采用 分离-重构 的方法。
分离 操作的目的是将信息量大的特征图从信息量小的特征图中分离出来,与空间内容相对应。作者使用组归一化 (Group Normalization) 里的缩放因子来评估不同特征图中的信息含量。
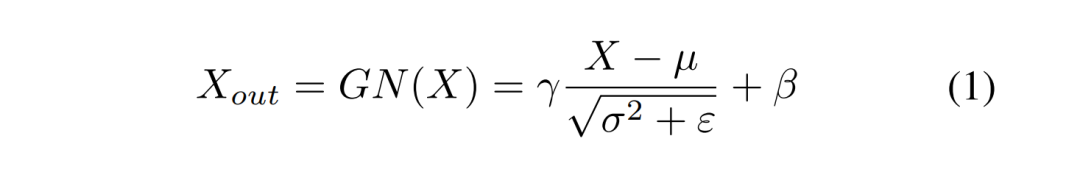
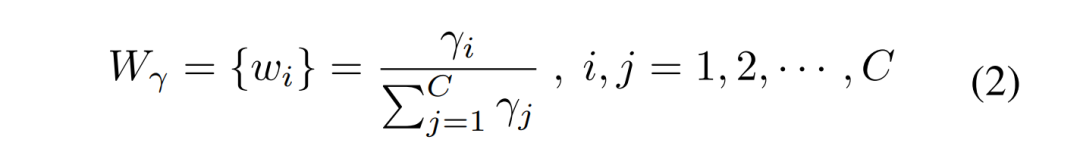
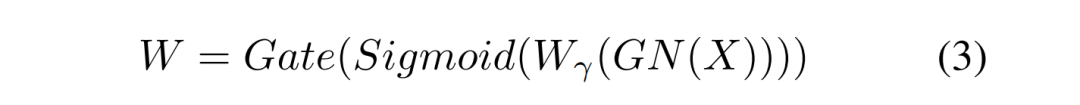

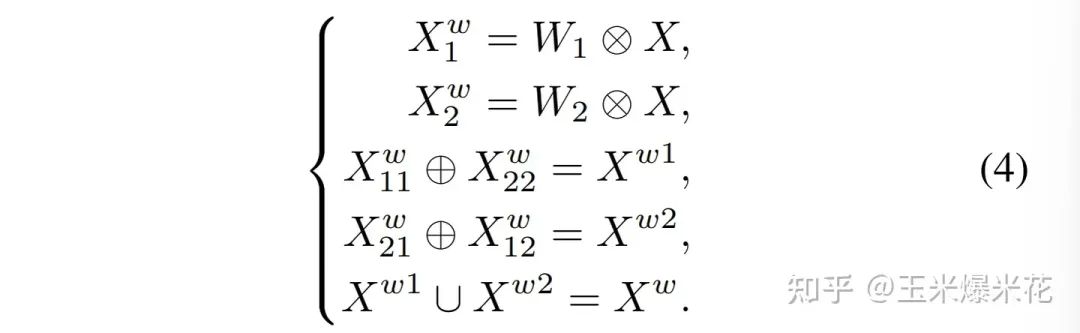

经过 SRU 处理后,信息量大的特征从信息量小的特征中分离出来,减少了空间维度上的冗余特征。
CRU 通道重建单元
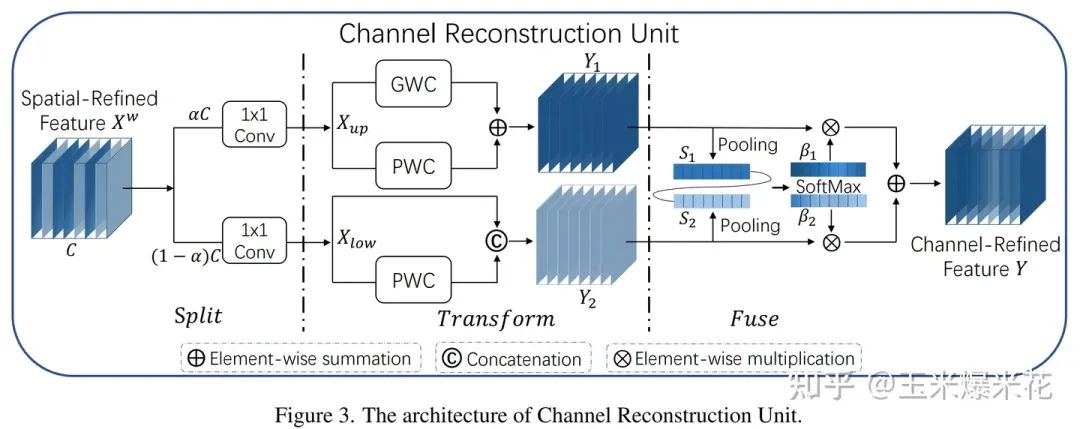
在作者的设计中,该单元采用 分割-转换-融合 的方法。

实验
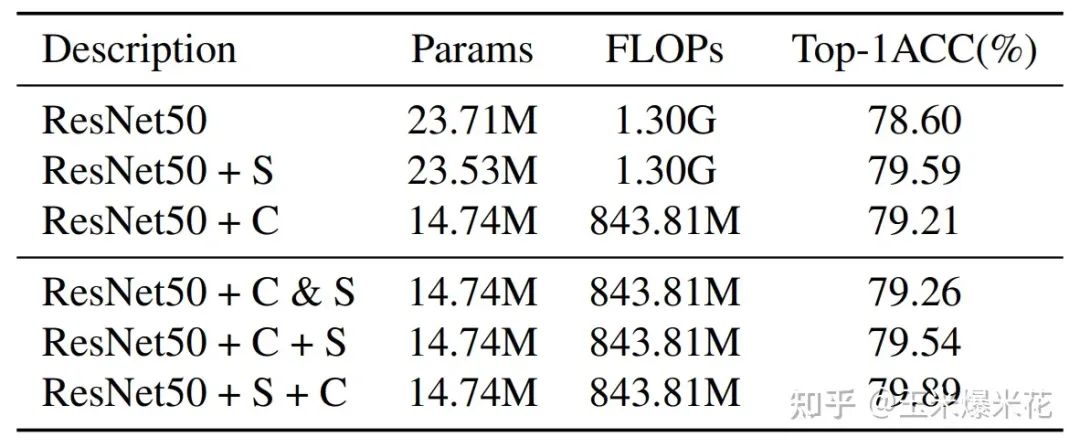
消融实验
下图的消融实验确定了 SRU 和 CRU 的排列方式
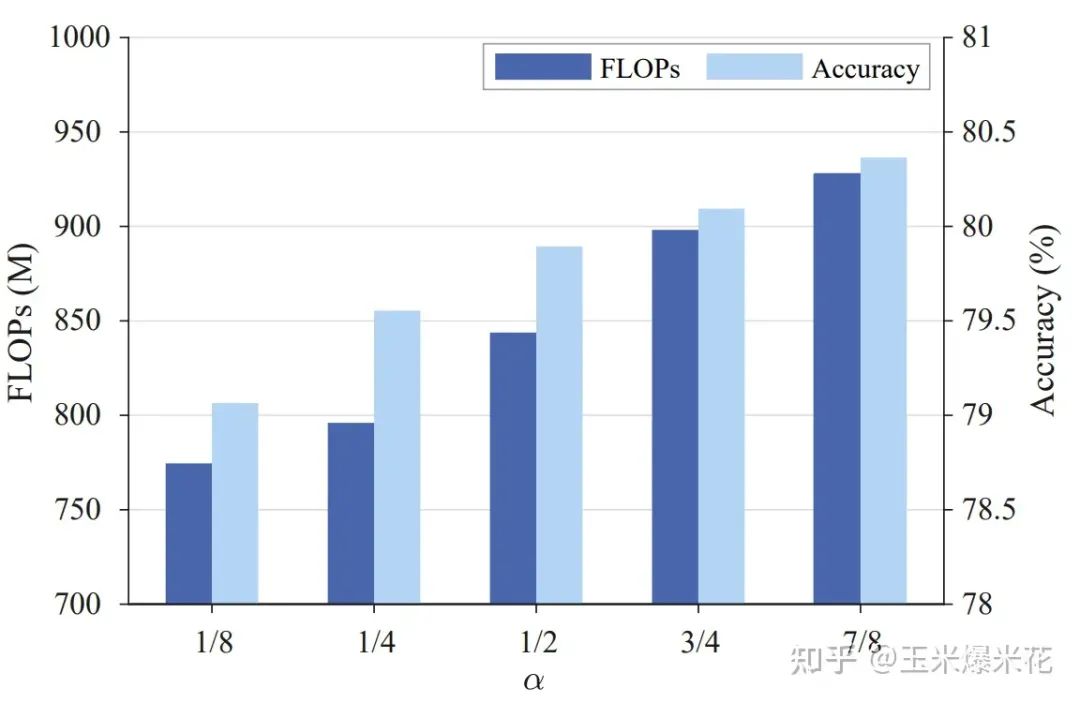
下图的消融实验确定了 CRU 中的拆分系数 α
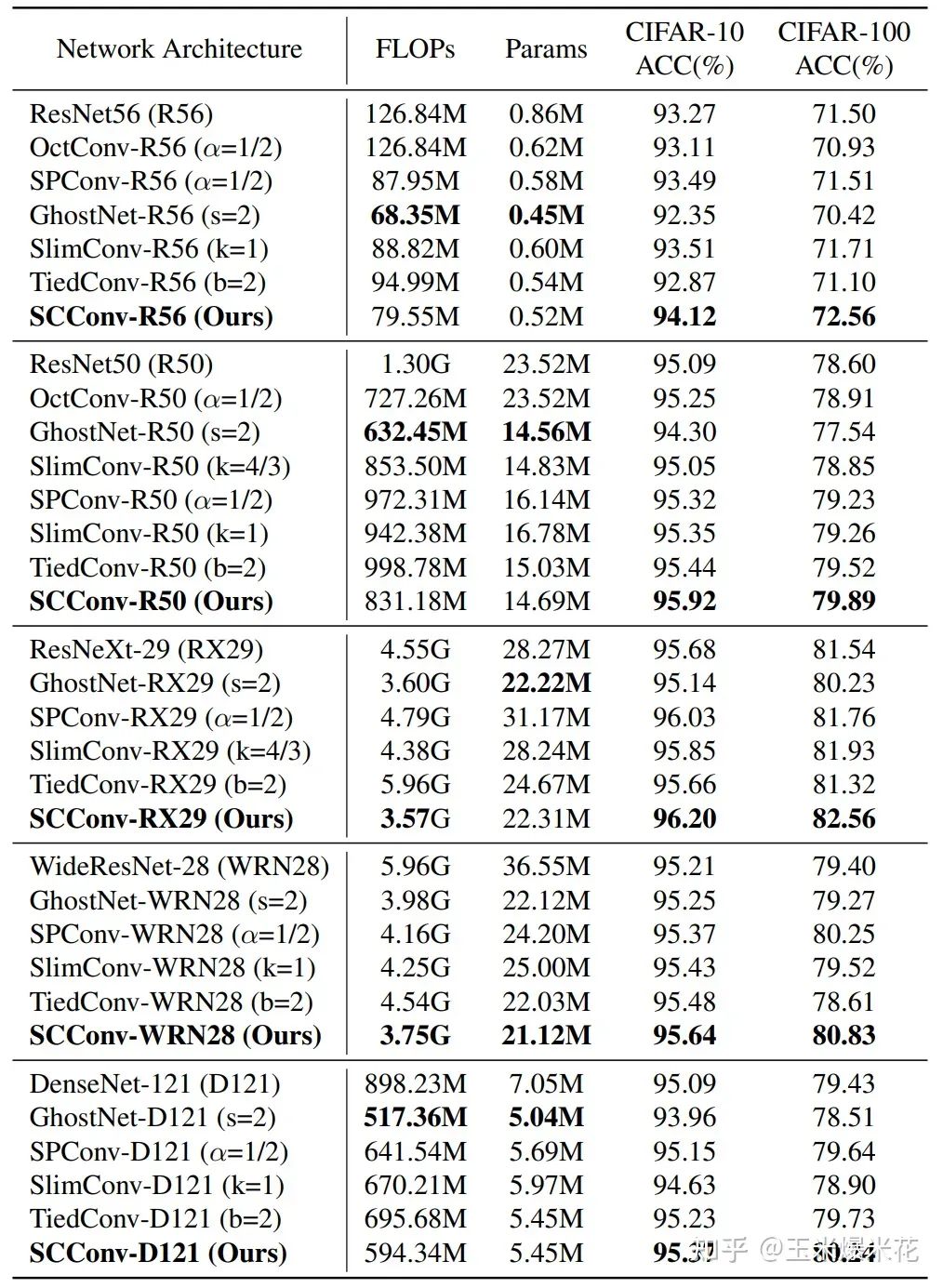
图片分类实验
下图是与其他 SOTA 方法的比较,作者认为在所有的情况下,SCConv-embedded 模型的准确性都优于先前所有的网络。在某些模型中,对比同类模型在减少参数和 FLOPs 的同时还实现了更高的准确率
在CVer微信公众号后台回复:SCConv,可以下载本论文pdf和代码
相关代码中文注释
import torch # 导入 PyTorch 库
import torch.nn.functional as F # 导入 PyTorch 的函数库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
# 自定义 GroupBatchnorm2d 类,实现分组批量归一化
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int, group_num:int = 16, eps:float = 1e-10):
super(GroupBatchnorm2d,self).__init__() # 调用父类构造函数
assert c_num >= group_num # 断言 c_num 大于等于 group_num
self.group_num = group_num # 设置分组数量
self.gamma = nn.Parameter(torch.randn(c_num, 1, 1)) # 创建可训练参数 gamma
self.beta = nn.Parameter(torch.zeros(c_num, 1, 1)) # 创建可训练参数 beta
self.eps = eps # 设置小的常数 eps 用于稳定计算
def forward(self, x):
N, C, H, W = x.size() # 获取输入张量的尺寸
x = x.view(N, self.group_num, -1) # 将输入张量重新排列为指定的形状
mean = x.mean(dim=2, keepdim=True) # 计算每个组的均值
std = x.std(dim=2, keepdim=True) # 计算每个组的标准差
x = (x - mean) / (std + self.eps) # 应用批量归一化
x = x.view(N, C, H, W) # 恢复原始形状
return x * self.gamma + self.beta # 返回归一化后的张量
# 自定义 SRU(Spatial and Reconstruct Unit)类
class SRU(nn.Module):
def __init__(self,
oup_channels:int, # 输出通道数
group_num:int = 16, # 分组数,默认为16
gate_treshold:float = 0.5, # 门控阈值,默认为0.5
torch_gn:bool = False # 是否使用PyTorch内置的GroupNorm,默认为False
):
super().__init__() # 调用父类构造函数
# 初始化 GroupNorm 层或自定义 GroupBatchnorm2d 层
self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(c_num=oup_channels, group_num=group_num)
self.gate_treshold = gate_treshold # 设置门控阈值
self.sigomid = nn.Sigmoid() # 创建 sigmoid 激活函数
def forward(self, x):
gn_x = self.gn(x) # 应用分组批量归一化
w_gamma = self.gn.gamma / sum(self.gn.gamma) # 计算 gamma 权重
reweights = self.sigomid(gn_x * w_gamma) # 计算重要性权重
# 门控机制
info_mask = reweights >= self.gate_treshold # 计算信息门控掩码
noninfo_mask = reweights < self.gate_treshold # 计算非信息门控掩码
x_1 = info_mask * x # 使用信息门控掩码
x_2 = noninfo_mask * x # 使用非信息门控掩码
x = self.reconstruct(x_1, x_2) # 重构特征
return x
def reconstruct(self, x_1, x_2):
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1) # 拆分特征为两部分
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1) # 拆分特征为两部分
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1) # 重构特征并连接
# 自定义 CRU(Channel Reduction Unit)类
class CRU(nn.Module):
def __init__(self, op_channel:int, alpha:float = 1/2, squeeze_radio:int = 2, group_size:int = 2, group_kernel_size:int = 3):
super().__init__() # 调用父类构造函数
self.up_channel = up_channel = int(alpha * op_channel) # 计算上层通道数
self.low_channel = low_channel = op_channel - up_channel # 计算下层通道数
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
# 上层特征转换
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1, padding=group_kernel_size // 2, groups=group_size) # 创建卷积层
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False) # 创建卷积层
# 下层特征转换
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
self.advavg = nn.AdaptiveAvgPool2d(1) # 创建自适应平均池化层
def forward(self, x):
# 分割输入特征
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)
up, low = self.squeeze1(up), self.squeeze2(low)
# 上层特征转换
Y1 = self.GWC(up) + self.PWC1(up)
# 下层特征转换
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# 特征融合
out = torch.cat([Y1, Y2], dim=1)
out = F.softmax(self.advavg(out), dim=1) * out
out1, out2 = torch.split(out, out.size(1) // 2, dim=1)
return out1 + out2
# 自定义 ScConv(Squeeze and Channel Reduction Convolution)模型
class ScConv(nn.Module):
def __init__(self, op_channel:int, group_num:int = 16, gate_treshold:float = 0.5, alpha:float = 1/2, squeeze_radio:int = 2, group_size:int = 2, group_kernel_size:int = 3):
super().__init__() # 调用父类构造函数
self.SRU = SRU(op_channel, group_num=group_num, gate_treshold=gate_treshold) # 创建 SRU 层
self.CRU = CRU(op_channel, alpha=alpha, squeeze_radio=squeeze_radio, group_size=group_size, group_kernel_size=group_kernel_size) # 创建 CRU 层
def forward(self, x):
x = self.SRU(x) # 应用 SRU 层
x = self.CRU(x) # 应用 CRU 层
return x
if __name__ == '__main__':
x = torch.randn(1, 32, 16, 16) # 创建随机输入张量
model = ScConv(32) # 创建 ScConv 模型
print(model(x).shape) # 打印模型输出的形状在CVer微信公众号后台回复:SCConv,可以下载本论文pdf和代码
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 4932
4932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









