






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
转载自:机器之心
研究者表示,他们将边缘训练看作一个优化问题,从而发现了在给定内存预算下实现最小能耗的最优调度。
目前,智能手机和嵌入式平台等边缘设备上已经广泛部署深度学习模型来进行推理。其中,训练仍然主要是在具有 GPU 等高通量加速器的大型云服务器上完成。集中式云训练模型需要将照片和按键等敏感数据从边缘设备传输到云端,从而牺牲了用户隐私并导致了额外的数据移动成本。

图注:推特 @Shishir Patil
因此,为了使用户在不牺牲隐私的情况下个性化他们的模型,联邦学习等基于设备的训练方法不需要将数据整合到云端,也能执行本地训练更新。这些方法已被部署在谷歌 Gboard 键盘上以个性化键盘建议,也被 iPhones 手机用来提升自动语音识别。同时,当前基于设备的训练方法不支持训练现代架构和大模型。在边缘设备上训练更大的模型不可行,主要是有限的设备内存无法存储反向传播激活。ResNet-50 的单次训练迭代所需的内存是推理的 200 多倍。
以往工作提出的策略包括分页到辅助内存和重新实现,以减少云端训练的内存占用。但是,这些方法会显著增加整体能耗。与分页方法相关的数据传输通常需要比重计算数据更多的能量。随着内存预算的缩减,重新实现会以 O(n^2 ) 的速度增加能耗。
在 UC 伯克利最近的一篇论文中,几位研究者表明分页和重新实现是高度互补的。通过对简单操作重新实现,同时将复杂操作的结果分页到闪存或 SD 卡等辅助存储器上,他们能够以最小的能耗扩展有效的内存容量。并且,通过这两种方法的结合,研究者还证明了在移动级边缘设备上训练 BERT 等模型是可能的。通过将边缘训练看作一个优化问题,他们发现了在给定内存预算下实现最小能耗的最优调度。

论文地址:https://arxiv.org/pdf/2207.07697.pdf
项目主页:https://poet.cs.berkeley.edu/
GitHub 地址:https://github.com/shishirpatil/poet
研究者提出了 POET(Private Optimal Energy Training),这是一种在内存受限边缘设备上对现代神经网络进行能量最优训练的算法,其架构如下图 1 所示。鉴于为反向传播缓存所有激活张量的成本极高,POET 对激活进行优化分页和重新实现,因而可以将内存消耗最高减少两倍。他们将边缘训练问题重新表述为整数线性程规划(ILP),发现可以通过求解器在 10 分钟内将其求解到最优。
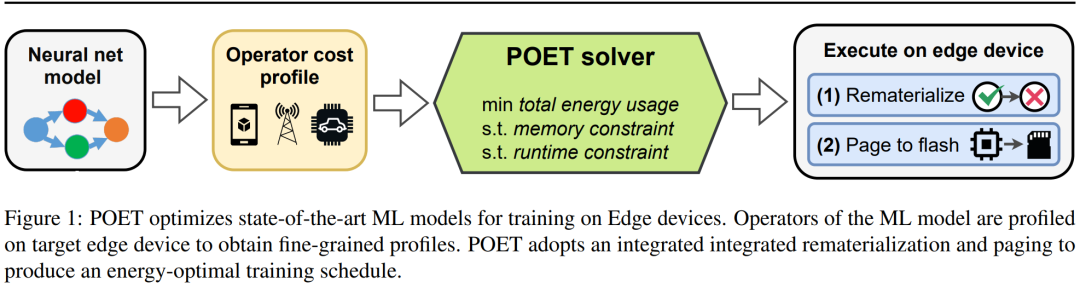
图注:POET 在边缘设备上对 SOTA 机器学习模型的训练进行优化。
对于部署在真实世界边缘设备上的模型,当边缘设备出现空闲并可以计算周期时就会进行训练,例如谷歌 Gboard 会在手机充电时安排模型更新。因此,POET 也包含了严格的训练限制。给定内存限制和训练 epoch 的数量,POET 生成的解决方案也能满足给定的训练截止期限。此外,研究者还利用 POET 开发了一个全面的成本模型,并证明它在数学上是保值的(即不做近似),适用于现有的开箱即用架构。
论文一作 Shishir Patil 在演示视频中表示,POET 算法可以在智能手机等商用边缘设备上训练任何需要极大内存的 SOTA 模型。他们也成为了首个展示在智能手机和 ARM Cortex-M 设备上训练 BERT 和 ResNet 等 SOTA 机器学习模型的研究团队。
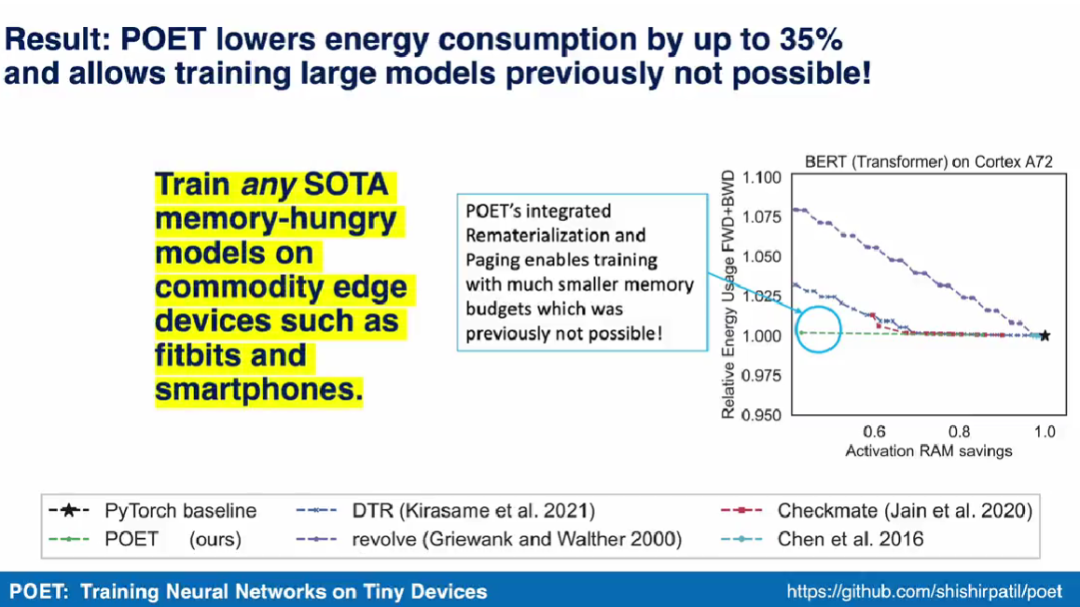
集成分页和重新实现
重新实现和分页是降低大型 SOTA ML 模型内存消耗的两种技术。在重新实现中,一旦不再需要激活张量就会被删除,最常见的是在前向传播期间。从而释放了宝贵的内存,可用于存储后续层的激活。当再次需要删除的张量时,该方法会根据谱系的规定从其他相关的激活中重新计算。而分页,也称为 offloading,是一种减少内存的补充技术。在分页中,不是立即需要的激活张量从主存储器调出到二级存储器,例如闪存或 SD 卡。当再次需要张量时,将其分页。
图 2 显示了一个八层神经网络的执行时间表。沿着 X 轴,每个单元对应神经网络的每一层(共 8 层 L8)。Y 轴表示一个 epoch 内的逻辑时间步长。图中占用的单元(用颜色填充)表示在相应的时间步执行的操作(前向 / 后向传播计算、重新实现或分页)。
例如,我们可以看到 L1 的激活是在第一个时间步 (T1) 计算的。在 T2 和 T3 时刻,分别计算 L2 和 L3 的激活量。假设层 L2 和 L3 恰好是内存密集型但计算成本较低的运算,例如非线性 (tanH、ReLU 等),那么重新实现就成为了最佳选择。我们可以删除激活({T3, L2}, {T4, L3}) 来释放内存,当后向传播过程中需要这些激活时,可以再重新实现它们({T14, L3}, {T16, L2})。
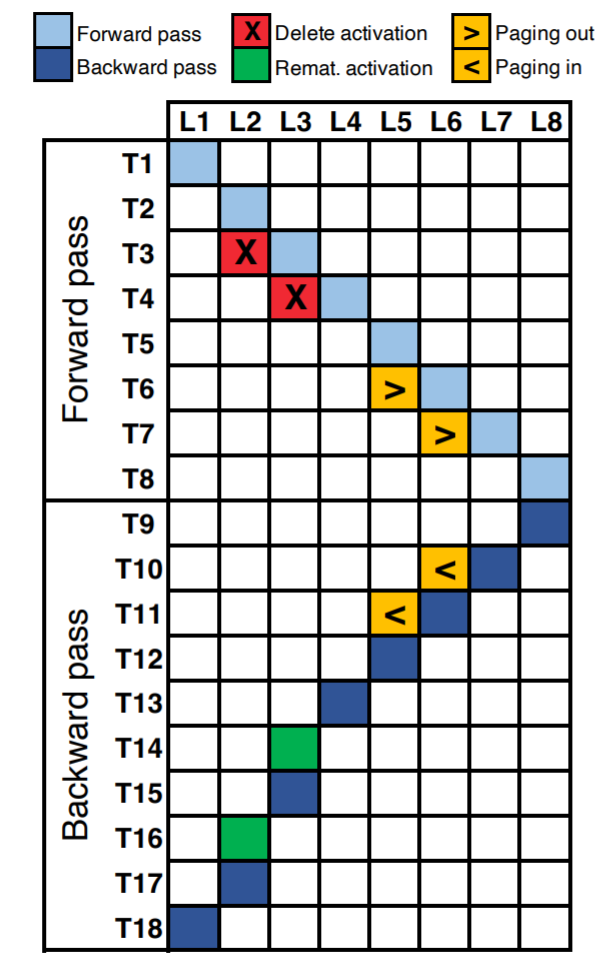
假设 L5 和 L6 层是计算密集型运算,例如卷积、密集矩阵乘法等。对于此类运算,重新实现将导致运行时间和能量的增加,并且这种方式是次优的。对于这些层,最好将激活张量分页到辅助存储({T6,L5},{T7,L6}),并在需要时分页到({T10,L6},{T11,L5 })。
分页的一个主要优点是,根据内存总线的占用情况,可以进行 pipelin 处理,以隐藏延迟。这是因为现代系统具有 DMA(直接内存访问)特性,它可以在计算引擎并行运行时将激活张量从辅助存储移动到主内存。例如,在时间步 T7,可以同时将 L6 调出并计算 L7。但是,重新实现是计算密集型的,不能并行化,这导致运行时间增加。例如,我们必须将时间步 T14 用于重新计算 L3,从而延迟其余反向传播执行。
POET
该研究提出了 POET,这是一种用于深度神经网络的图形级编译器,它重写了大型模型的训练 DAG,以适应边缘设备的内存限制,同时保持高能效。
POET 是硬件感知的,它首先跟踪前向和后向传播的执行以及相关的内存分配请求、运行时间以及每次操作的内存和能源消耗。对于给定的硬件,每个工作负载的这种细粒度分析只发生一次,具有自动化、便宜等特性,并且为 POET 提供了最准确的成本模型。POET 然后生成可以有效求解的混合整数线性规划 (MILP)。
POET 优化器搜索有效的重新实现和分页调度,以最大限度地减少受内存限制的端到端能源消耗。然后使用得到的调度生成一个新的 DAG,在边缘设备上执行。
虽然 MILP 是在商用硬件上解决的,但发送到边缘设备的调度表只有几百字节,因此内存效率很高。
对于计算成本低但内存密集型的操作,重新实现是最有效的。然而,分页最适合于计算密集型操作,在这种操作中,重新实现将导致大量的能量开销。POET 在一个集成搜索空间中共同考虑重新实现和分页。
本文方法可扩展到复杂、现实的架构中,POET 优化器算法如下。

该研究在优化问题中引入了一个新的目标函数,以最小化计算、page-in 和 page-out 的综合能耗,分页和重新实现能耗结合的新目标函数为:
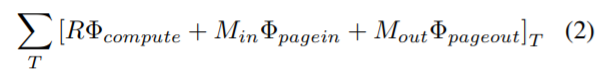
其中Φ_compute、Φ_pagein 和Φ_pageout 分别表示每个节点在计算、page-in 和 page-out 时所消耗的能量。
POET 根据图的哪些节点 (k) 进行了重新实现,以及在每个时间步长 (t) 将哪些节点 page-in 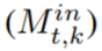 或 page-out
或 page-out 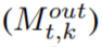 来输出 DAG 调度。
来输出 DAG 调度。

实验结果
在对 POET 的评估中,研究者试图回答三个关键问题。首先,POET 在不同的模型和平台上能够减少多少能耗?其次,POET 如何从混合分页和重新实现策略中获益?最后,POET 如何适应不同的运行时预算?
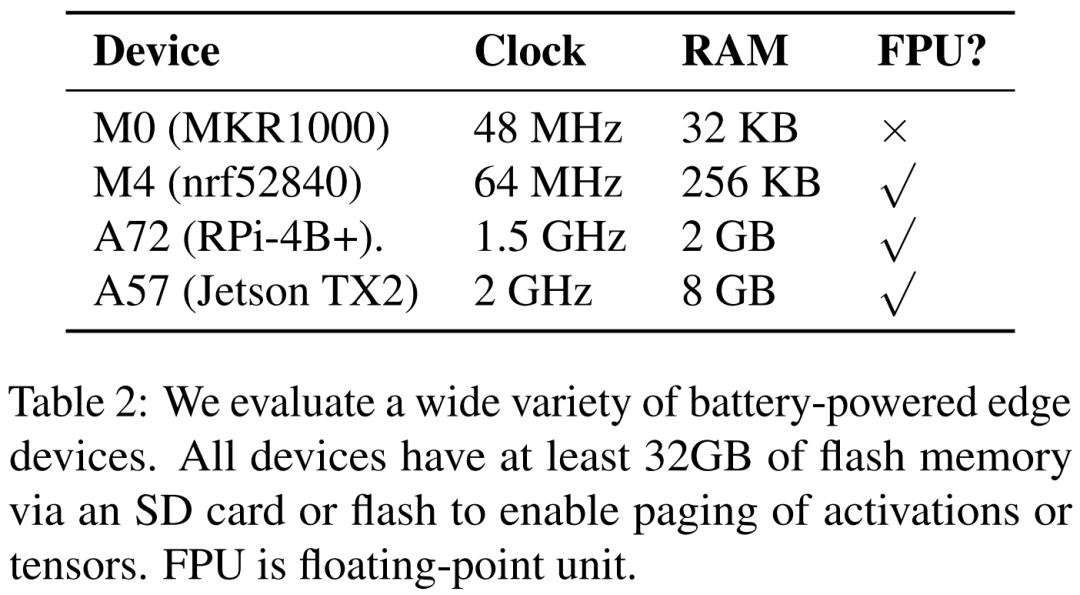
研究者在下表 2 中列出四种不同的硬件设备,分别为 ARM Cortex M0 MKR1000、ARM Cortex M4F nrf52840、A72 Raspberry Pi 4B + 和 Nvidia Jetson TX2。POET 是完全硬件感知的,依赖于细粒度的分析。
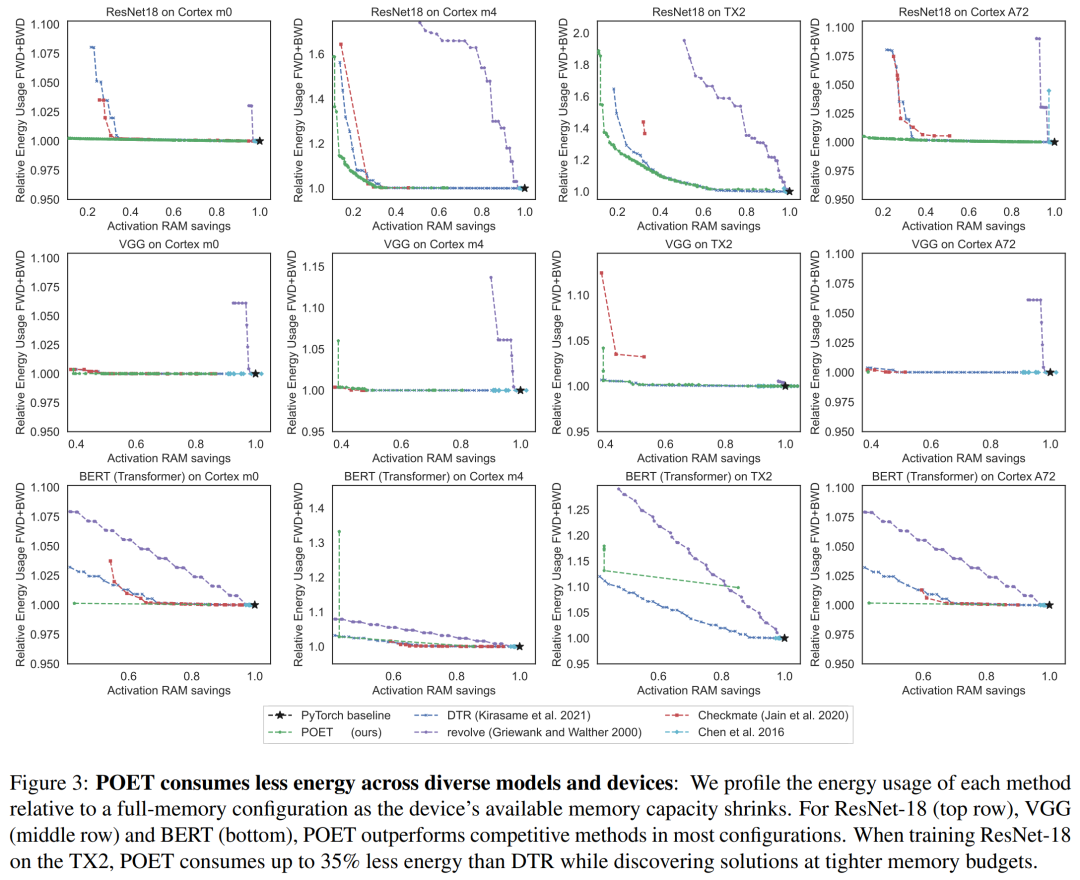
下图 3 显示了单次训练 epoch 的能耗,每列分别对应不同的硬件平台。研究者发现,POET 在所有平台上生成节能耗最优的调度(Y 轴),同时减少峰值内存消耗(X 轴)并符合时间预算。
在下图 5 中,研究者在 A72 上训练 ResNet-18 时对 POET 和 Capuchin 进行了基准测试。随着 RAM 预算的减少,Capuchin 比具有完整内存的基线多了 73% 到 141% 的能耗。相比之下,POET 产生的能耗不到 1%。这种趋势适用于测试的所有架构和平台。
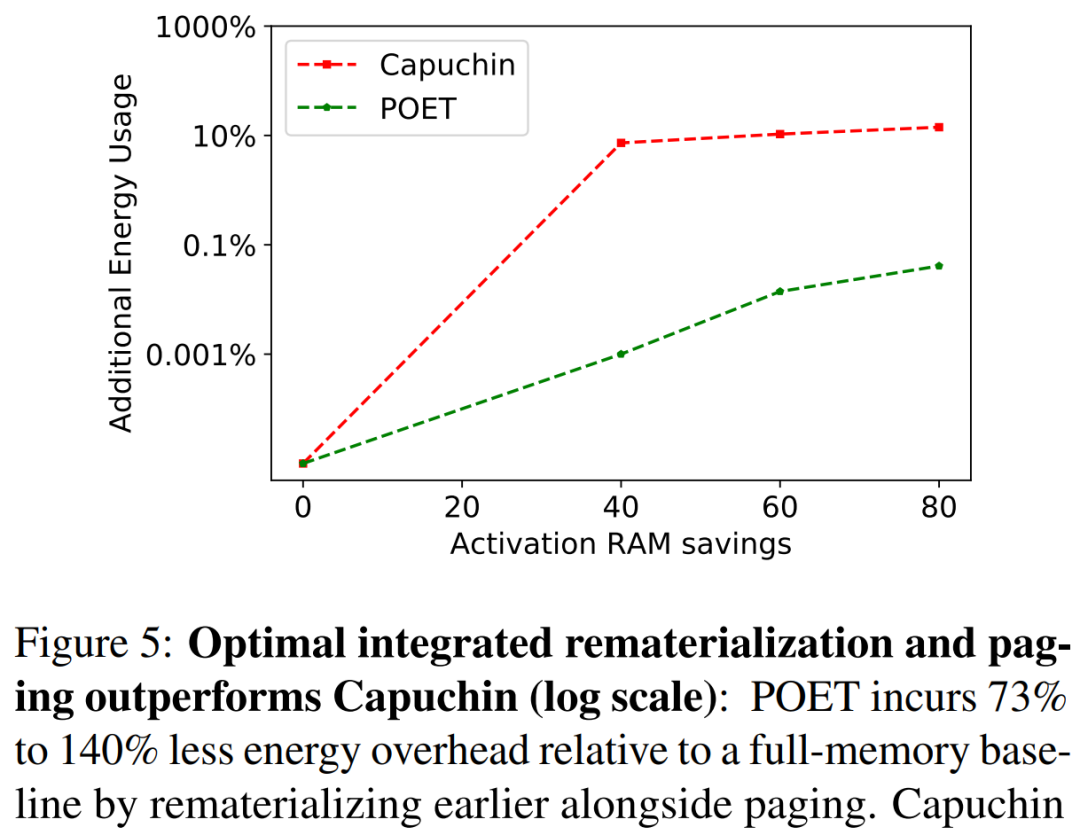
表 3 中,该研究在 Nvidia 的 Jetson TX2 上训练 ResNet-18 时对 POET 和 POFO 进行了基准测试。研究发现 POET 找到了一个集成的重新实现和分页调度,可将峰值内存消耗降低 8.3%,并将吞吐量提高 13%。这展示了 POET 的 MILP 求解器的优势,它能够在更大的搜索空间上进行优化。虽然 POFO 仅支持线性模型,但 POET 可以推广到非线性模型,如图 3 所示。
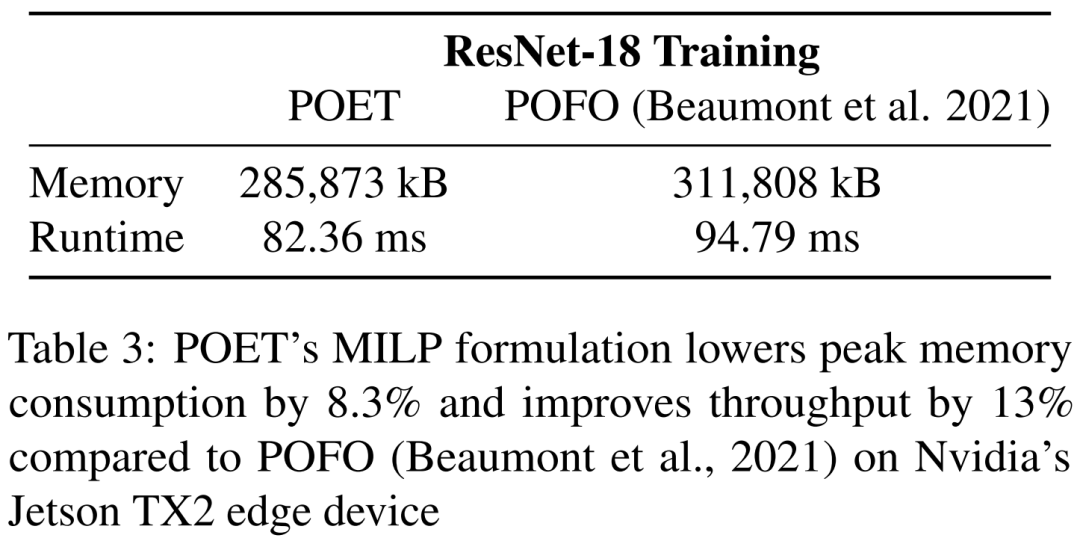
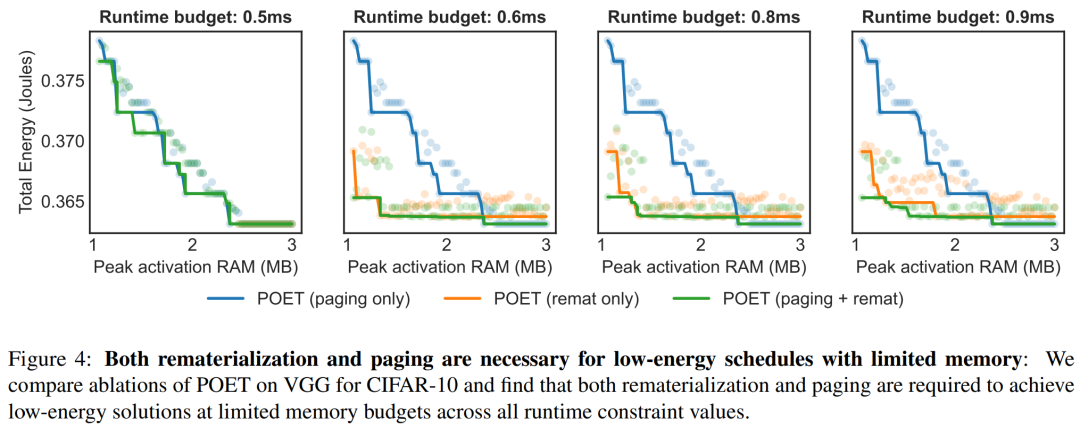
图 4 强调了 POET 在不同时间约束下采用集成策略的好处。对于每个运行时,下图绘制了总能耗图。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 84
84

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









