






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐!

转载自:量子位(QbitAI)
PyTorch团队让大模型推理速度加快了10倍。
且只用了不到1000行的纯原生PyTorch代码!
项目名为GPT-fast,加速效果观感是这样婶儿的:
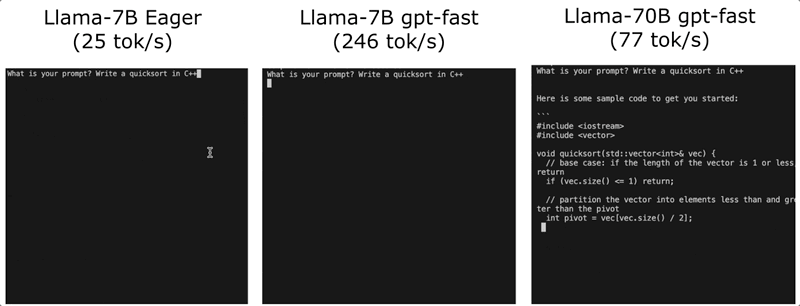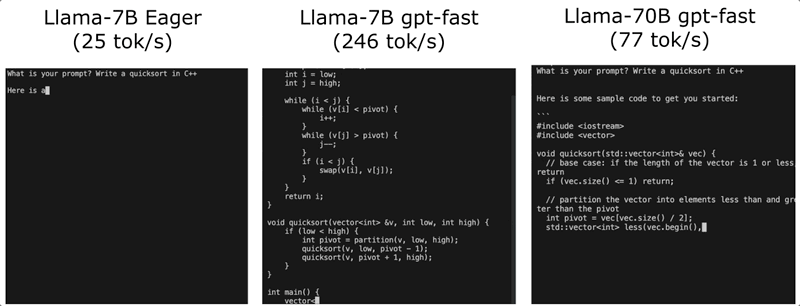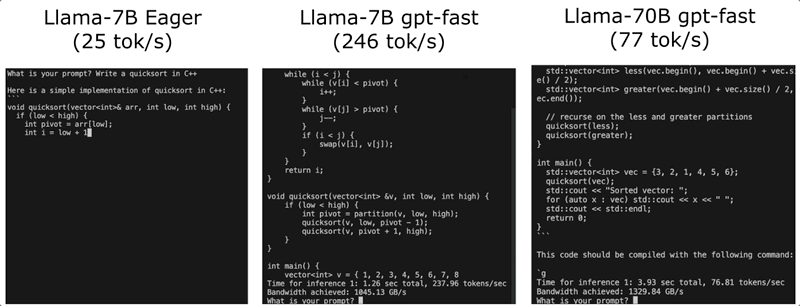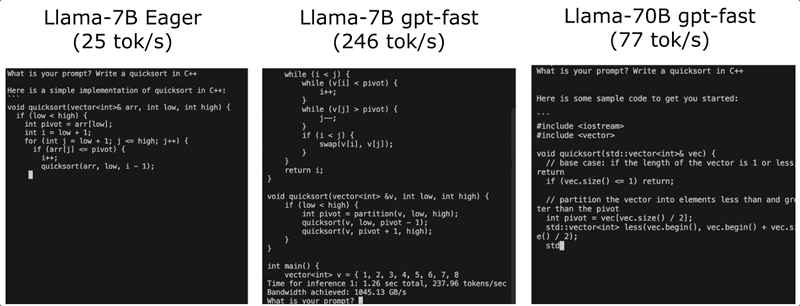
通畅,属实通畅!
重点是,团队直接放出了代码以及详细“教程”。还是简笔画版的那种,特别好理解。
开发团队成员@Horace He表示:
我们不把它看作是库或者框架,更希望大家能把它当成个例子,根据自己的需求“复制粘贴”。
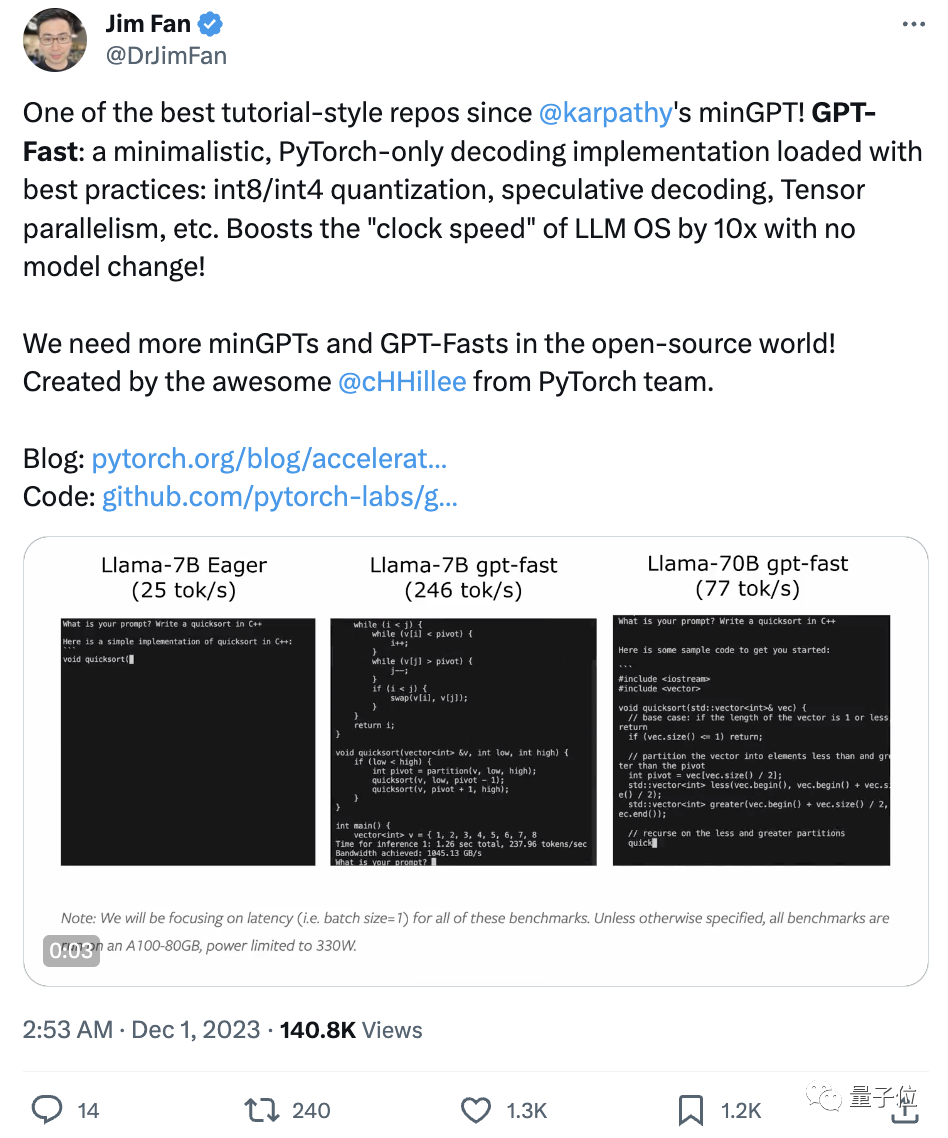
网友直接炸开锅,英伟达AI科学家Jim Fan评价道:
这是自Andrej Karpathy发布的minGPT以来最棒的教程式repo之一!
开源世界需要更多minGPT、GPT-Fast这样的项目!
那么GPT-fast究竟是如何给大模型提速的?
开盒大模型“加速包”
总的来说,用到这几种方法:
Torch.compile:一个专门为PyTorch模型设计的编译器,可以提升模型运行效率。
GPU量化:通过减少计算的精度来加速模型的运算速度。
推测性解码:使用一个较小的模型来预测较大模型的输出,以此加快大语言模型的运算。
张量并行性:通过在多个硬件设备上分布模型的运算来加速处理速度。
下面我们来一一展开。
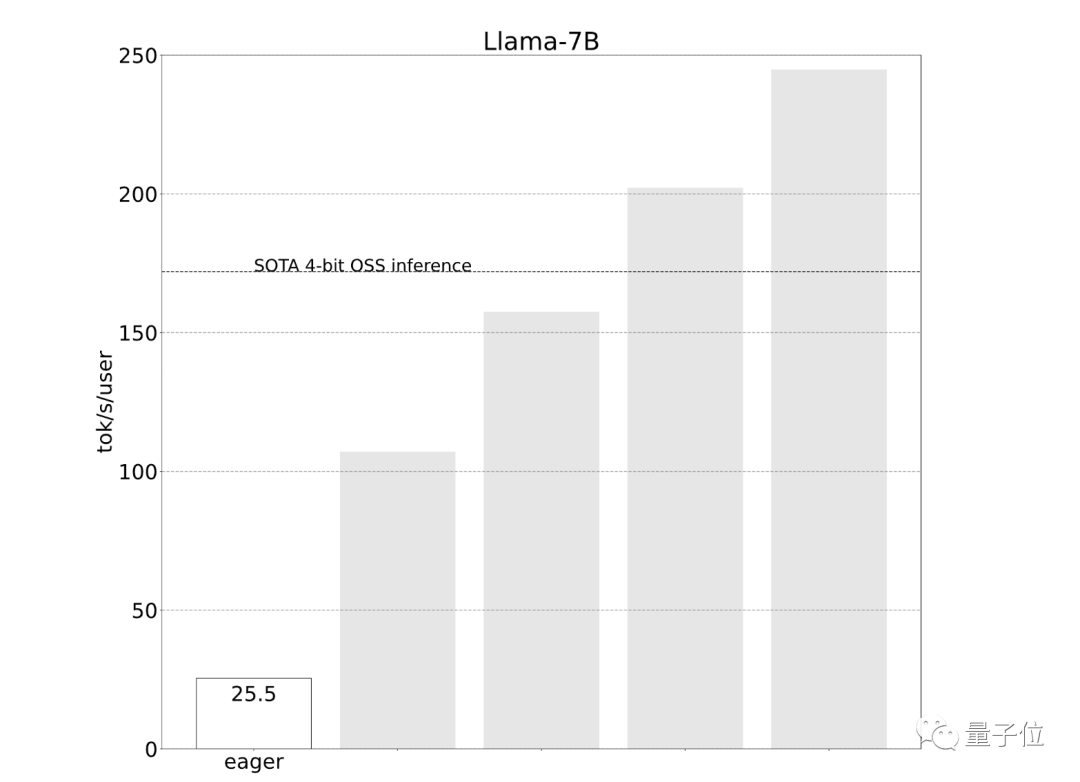
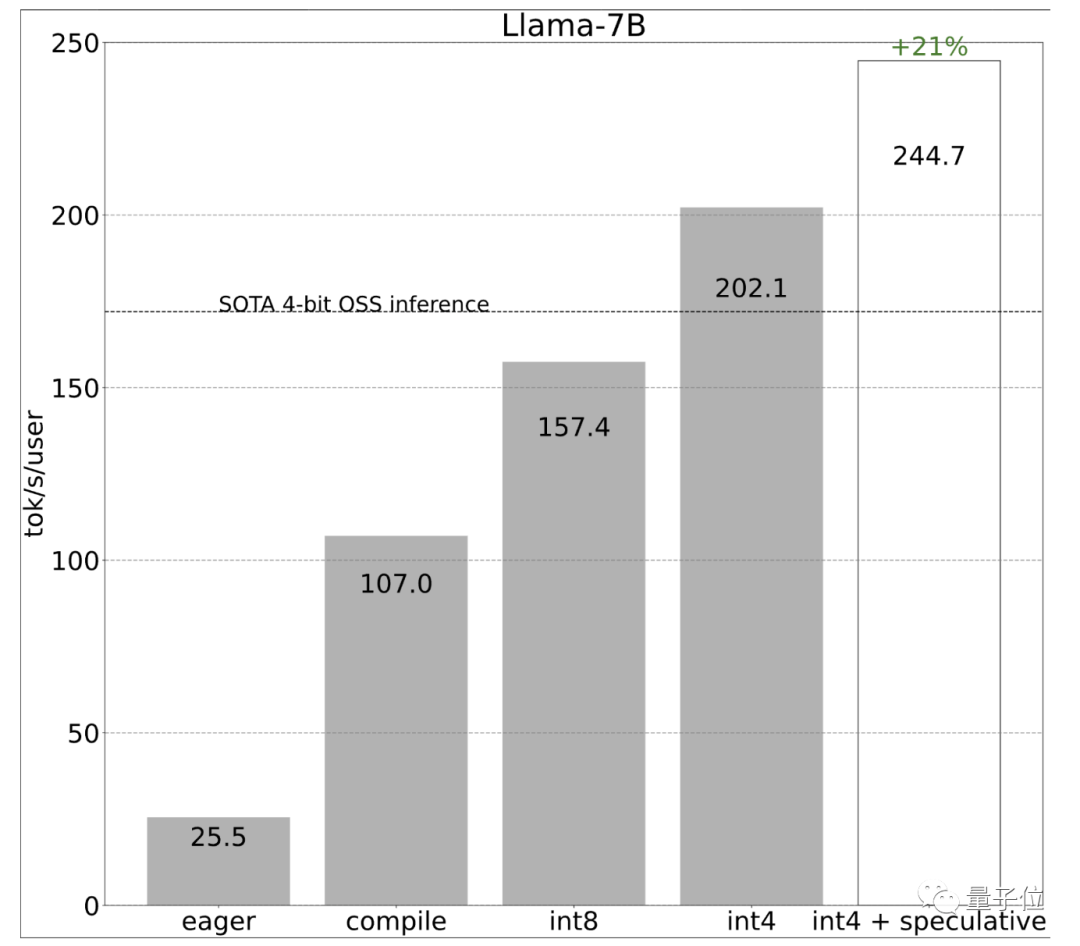
开发团队一开始使用简单的PyTorch来实现,但效果不佳(25.5 tok/s):
他们查看跟踪后发现,一个原因是推理性能由于CPU过多占用而受限。

那么如何解决呢?
可以想象这样一个场景,GPU是一个庞大的工厂(拥有大量可用的算力),而CPU则是一个小推车,来回为工厂“供货”。
在很多情况下,CPU无法足够快地“喂”GPU。
因此,开发团队建议给GPU更多的工作量,或者说一次性给它更大“块”的任务来处理。
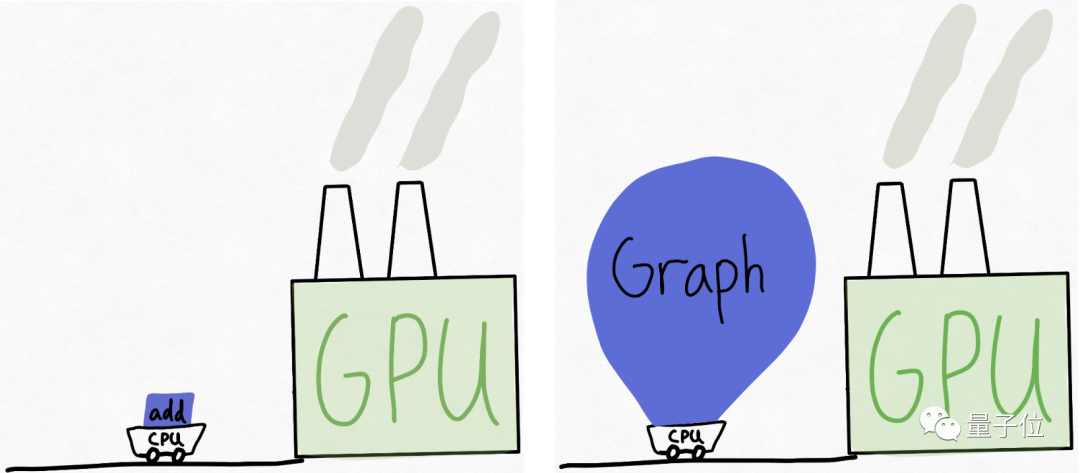
在推理过程中要做到这一点,可以引入torch.compile。
torch.compile能够捕获模型中更大的区域,并将其编译成单一的编译区域。特别是当以“reduce-overhead”模式运行时,它非常有效地减少了CPU的开销。
效果立竿见影,性能直接提升了4倍,从25 tok/s提高到107 tok/s:
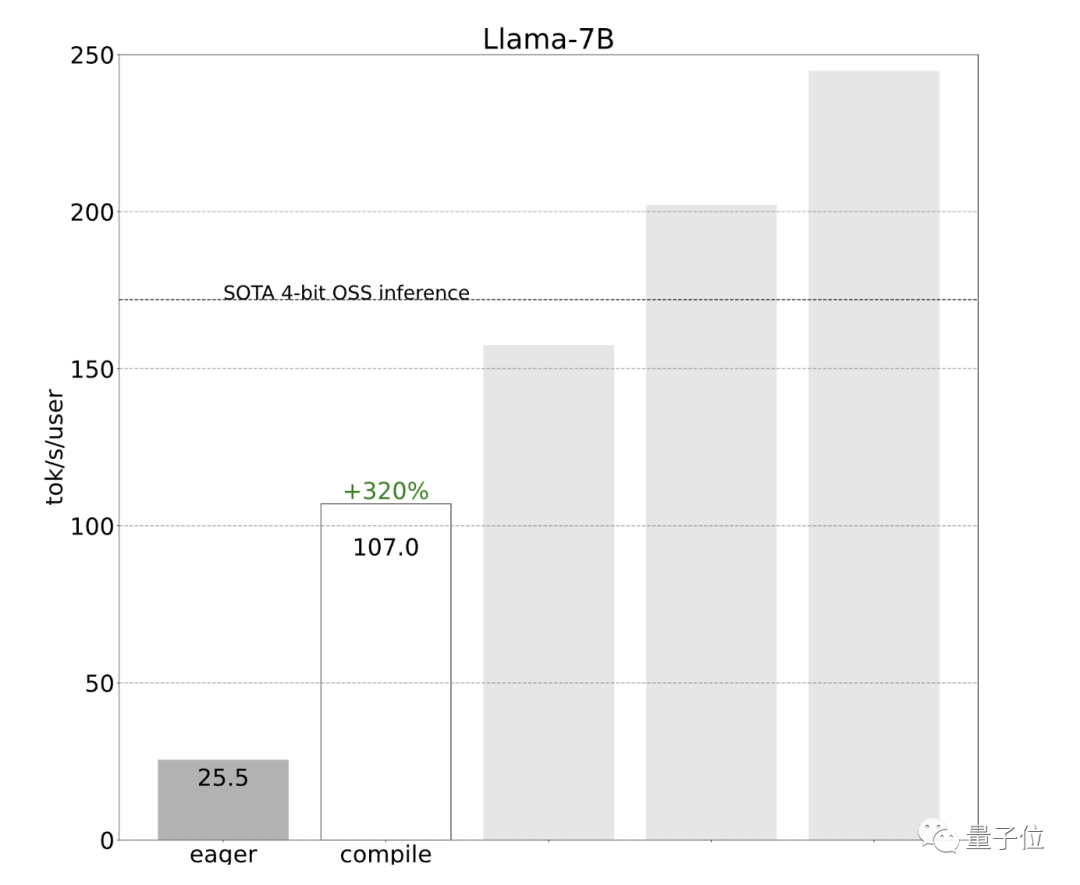
接下来,开发团队想进一步提升速度,但遇到了内存带宽瓶颈。
开发团队计算了模型的带宽利用率,结果已经达到了72%:

也就是说进一步提高速度的空间可能有限。
重新审视上面的方程式,团队发现虽然实际上不能改变模型参数量,也不能改变GPU的内存带宽(至少在不花更多钱的情况下),但可以改变存储每个参数所用的字节数。

这意味着,虽然无法改变模型的大小或者升级硬件来提高性能,但可以通过减少存储模型参数所需的数据量来提高效率。
通常可以通过量化技术来实现,即减少表示每个参数所需的位数。
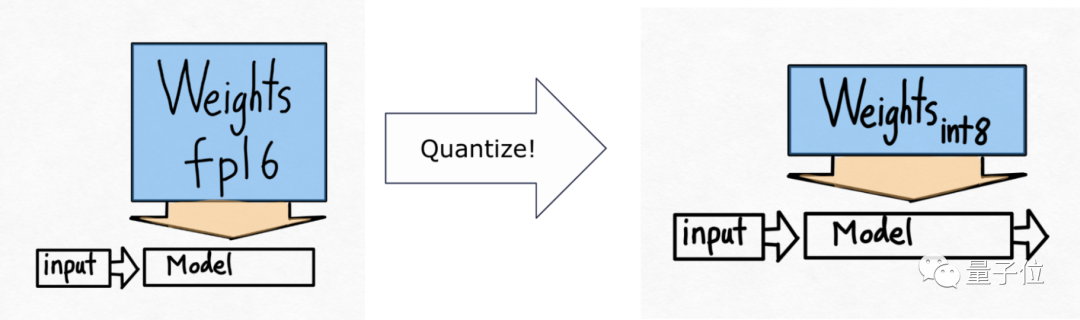
由此,开发团队引入了下一个技术——int8量化。
采用int8权重量化减少了内存负载,进一步提升了性能(157.4 tok/s):
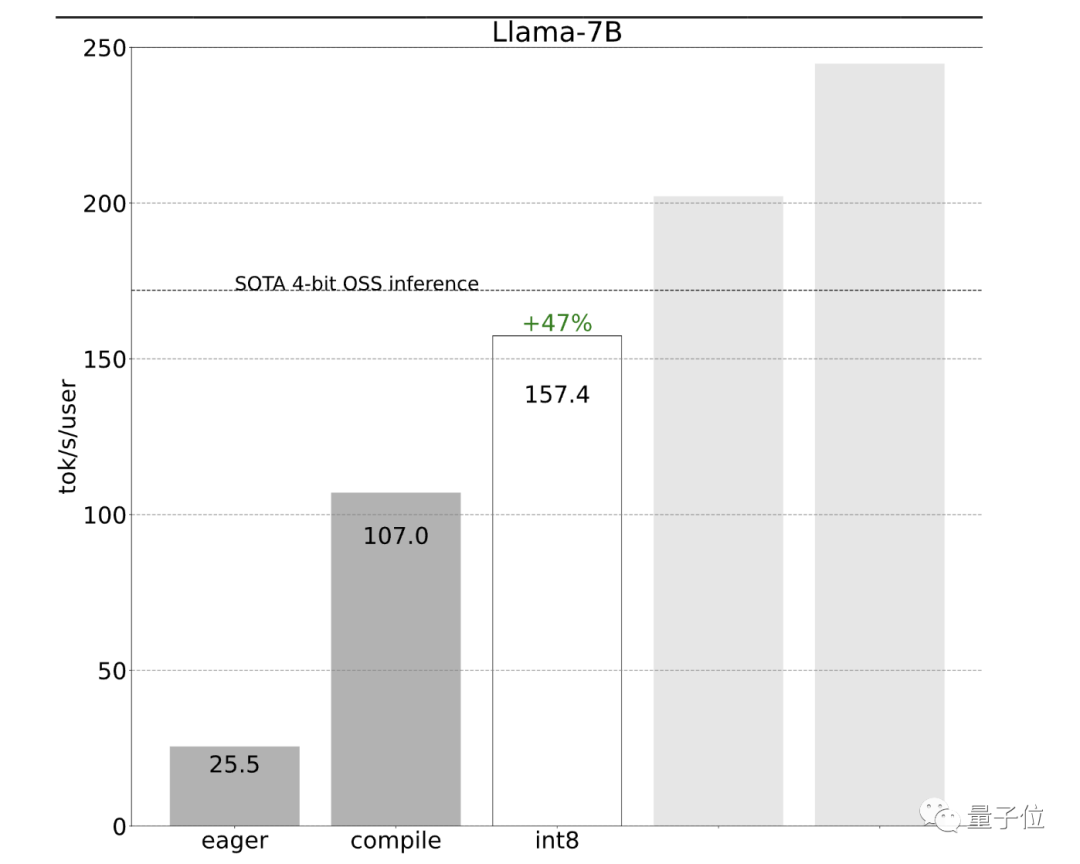
使用量化后还有一个问题:要生成100个token,必须加载(或调用)模型权重100次。频繁加载模型权重也会导致效率低下。
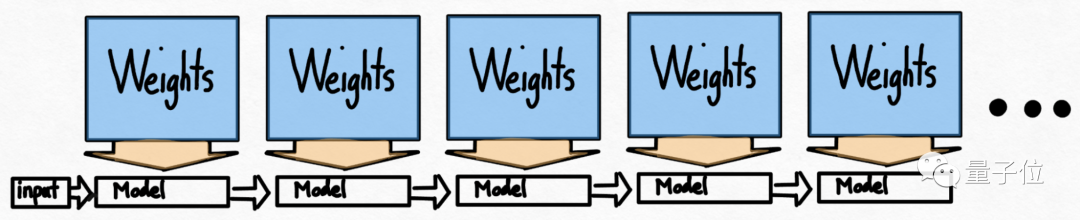
乍一看,好像没有什么解决的法子,因为在自回归生成模式中存在着严格的序列依赖关系。
但开发团队指出,通过利用推测性解码可以打破这种严格的序列依赖关系。
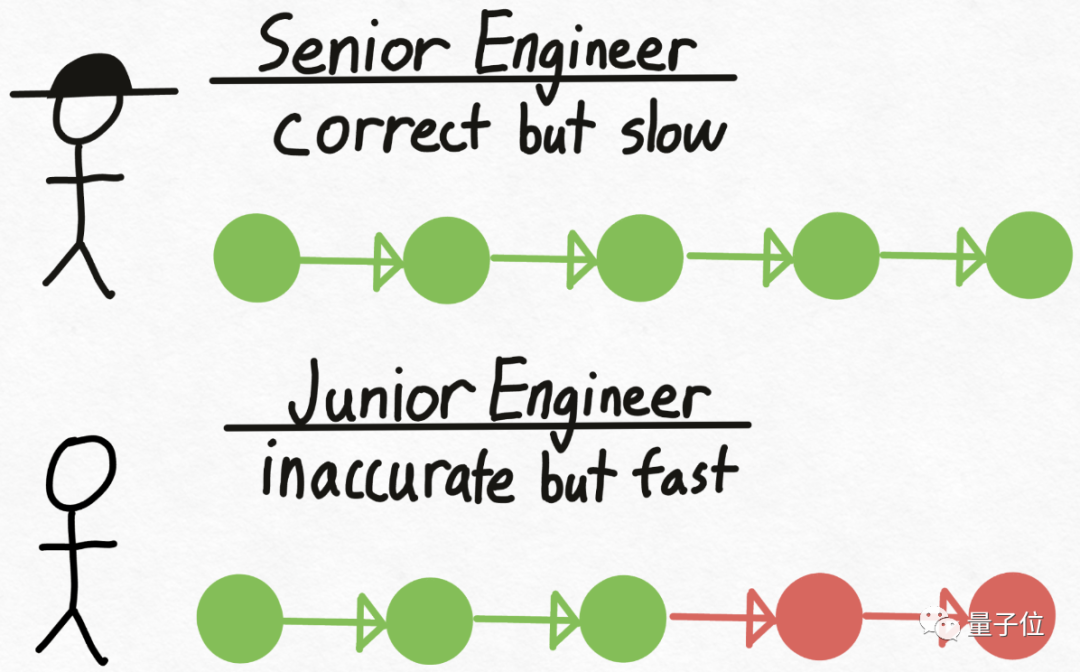
再来打个比方,想象有一个资深工程师Verity,他在技术决策上总是正确,但编写代码的速度相对较慢。
同时,还有一个初级工程师Drake,和Verity相反,不擅长技术决策,但编写代码的速度更快、成本也更低。

那么如何利用不同人的优势来提高整体效率?
方法很简单,先让Drake编写代码,并在此过程中做出技术决策。接下来,将代码交给Verity进行审查,不对的地方就让Drake重做。
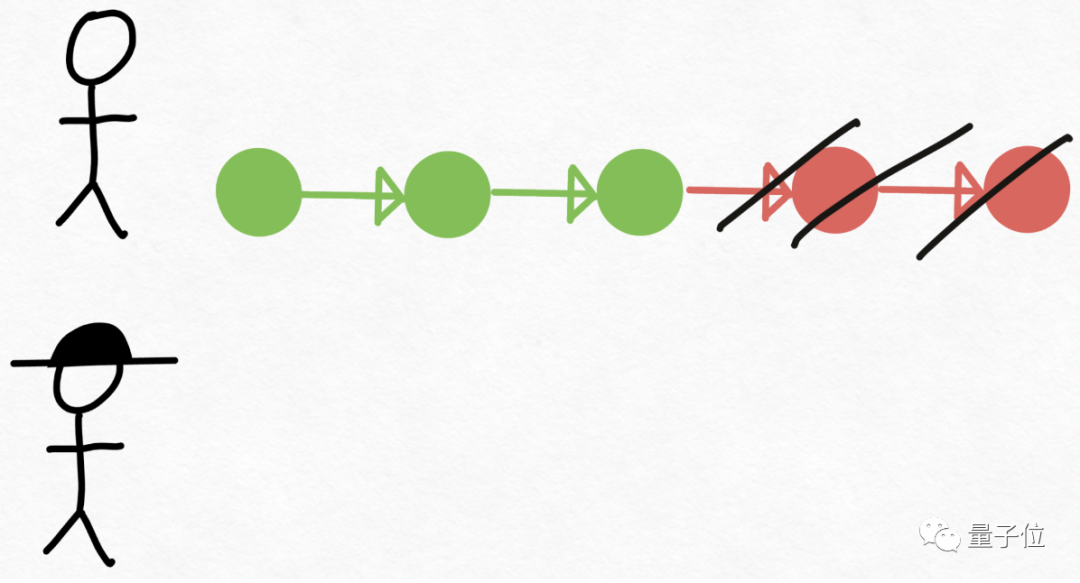
在Transformer模型推理中,大型的验证模型即为Verity角色,Drake则是一个更小的、能更快生成文本的草稿模型。
开发团队使用草稿模型生成8个token,然后使用验证模型并行处理,丢弃不匹配的部分。
由此一来,打破了串行依赖,再次提高速度。
值得一提的是,推测性解码不会改变输出的质量。只要使用草稿模型生成token+验证这些token所需的时间少于单独生成这些token所需的时间,这种方法就是有效的。
而且使用原生PyTorch实现这种技术实际上非常简单,整个实现过程只需要大约50行原生PyTorch代码。

由于AMD也支持Triton和torch.compile后端,因此之前在Nvidia GPU上应用的所有优化也可以在AMD GPU上重新应用。
开发团队观察到int8量化的加速从22 tok/s达到102 tok/s:

之后开发团队又用了int4量化,进一步提升速度,但模型准确性有所下降。
因此使用了分组量化和GPTQ降低权重大小。
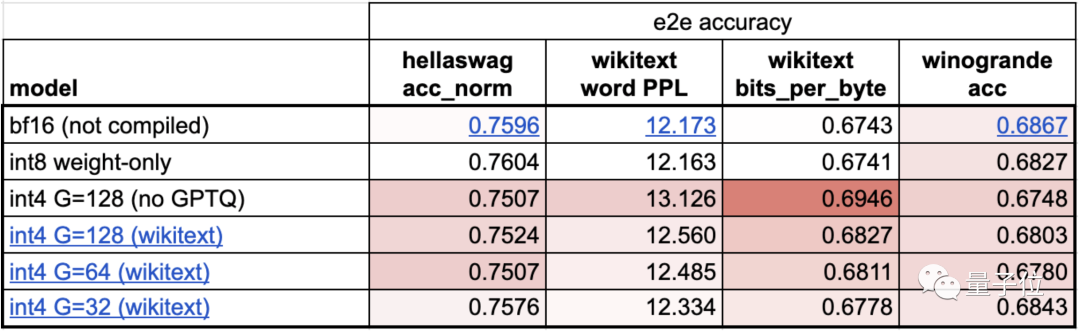
最后在保证准确性的前提下,速度提升至202.1 tok/s:
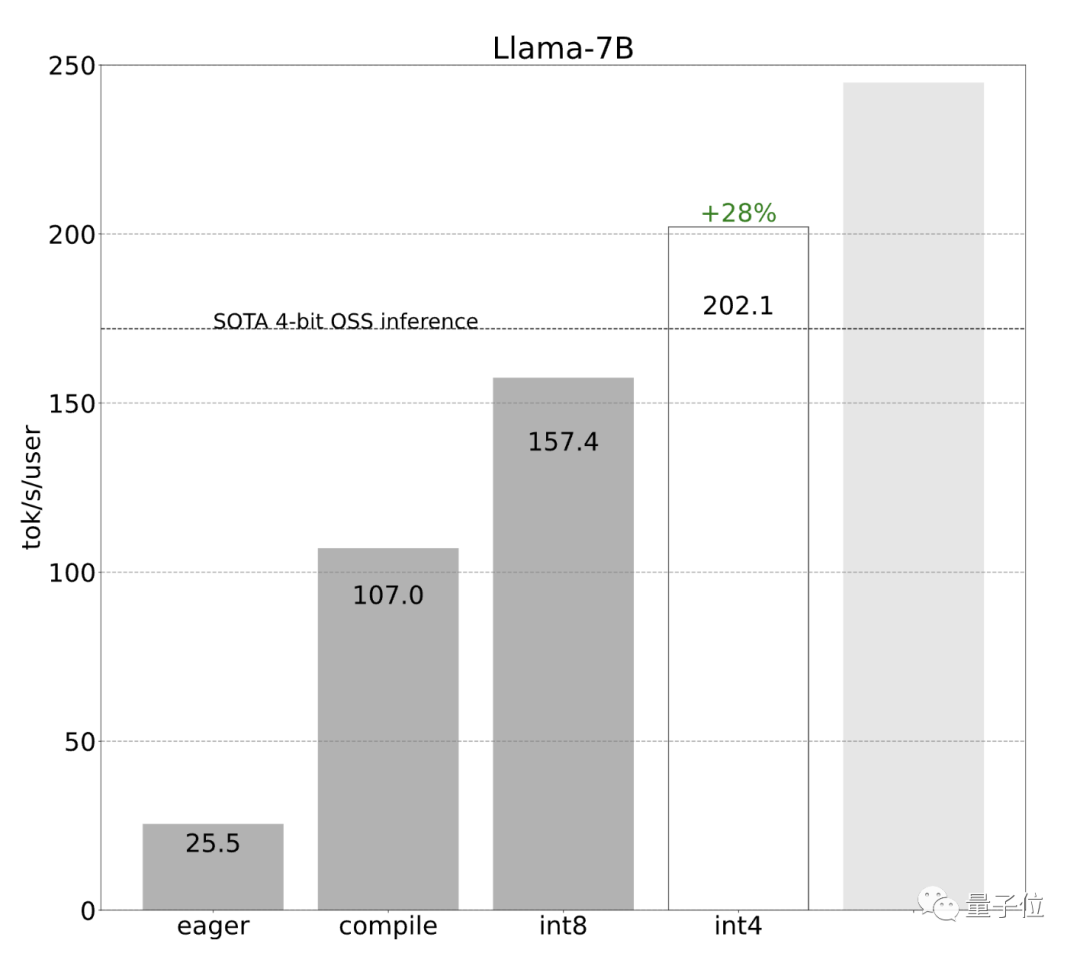
将以上技术结合使用,达到更高速度244.7 tok/s:
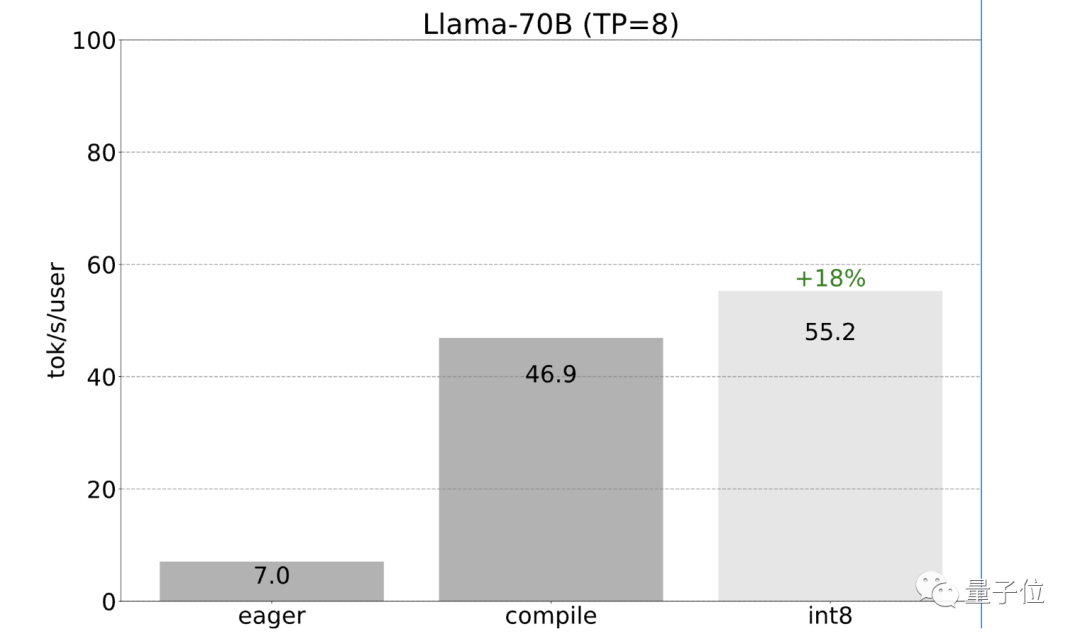
到目前为止,研发团队一直都是在单个GPU上提速。但其实很多情况下是可以使用多个GPU的。
而使用多个GPU可以增加内存带宽,从而提高模型的整体性能。

在选择并行处理策略时,需要在多个设备上分割一个token的处理过程,所以需要使用张量并行性。
而PyTorch也提供了用于张量并行性的底层工具,可以与torch.compile结合使用。
开发团队还透露也正在开发用于表达张量并行性的更高级别的API。
然而,即使没有更高级别的API,添加张量并行性也很容易,150行代码即可实现,且不需要对模型进行任何改变。

之前提到的所有优化都可以与张量并行性相结合。将这些优化结合起来,能够以55 tokens/s的速度为Llama-70B提供int8量化。
最后总结成果,忽略量化,仅用766行代码(model.py 244行代码,generate.py 371行代码,tp.py 151行代码),就实现了快速推理、推测性解码和张量并行性。
对于Llama-7B,使用compile+int4量化+推测性解码速度达到241 tok/s。对于Llama-70B,通过加入张量并行性,达到80 tok/s。
这些性能都接近或超越了当前SOTA。
参考链接:
[1]https://pytorch.org/blog/accelerating-generative-ai-2/?utm_content=273712248&utm_medium=social&utm_source=twitter&hss_channel=tw-776585502606721024
[2]https://twitter.com/DrJimFan/status/1730298947376443698
[3]https://twitter.com/cHHillee/status/1730293330213531844
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()

















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









