






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer444,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!

转载自:机器之心
图像匹配是计算机视觉的一项基础任务,其目标在于估计两张图像之间的像素对应关系。图像匹配是众多视觉应用如三维重建、视觉定位和神经渲染 (neural rendering) 等的基础和前置步骤,其精确度和效率对于后续处理十分重要。
传统算法(SIFT)在面临长基线或极端天气等复杂场景时,其匹配的准确度和密度往往有限。为了解决这些问题,近年来,基于深度学习的匹配模型逐渐流行。然而,由于缺乏大规模且多样化的具有真值标签的训练数据,目前的匹配模型通常是在 ScanNet 和 MegaDepth 上分别训练室内和室外两个模型。这种针对特定场景的训练限制了模型对 zero-shot 场景的泛化,无法扩展至未知场景中。此外,现有的数据构建方法往往依赖于 RGBD 扫描或 SfM+MVS 进行重建,其效率和适用性有限,无法有效地扩展数据并用于模型训练。
为了解决基于深度学习方法泛化性的问题,来自厦门大学、Intel、大疆的研究者们提出了 GIM: Learning Generalizable Image Matcher from Internet Videos。GIM 是第一个可以让匹配模型从互联网视频中学习到强泛化能力的训练框架。

论文主页:https://xuelunshen.com/gim
论文地址:https://arxiv.org/abs/2402.11095
论文视频:https://www.youtube.com/watch?v=FU_MJLD8LeY
代码地址:https://github.com/xuelunshen/gim
在线模型:https://huggingface.co/spaces/xuelunshen/gim-online
GIM 从易于获取、种类繁多且近乎于无限的互联网视频 (如图 1 所示) 中提取有效的监督信号,用于匹配模型的训练。

图 1. 部分互联网视频包含的多样场景
GIM 框架适用于训练所有匹配模型。如图 2 所示,三个匹配模型 DKM、LoFTR 和 SuperGlue 分别对应了:密集匹配、半密集匹配和稀疏匹配这三种主流匹配范式。在 GIM 框架下,用于训练的视频时长越长,匹配模型的性能就会越高。从目前的折线来看,在使用 50 小时的视频后,性能还没有表现出饱和的现象,因此如果使用更多的视频,性能还会进一步提高。
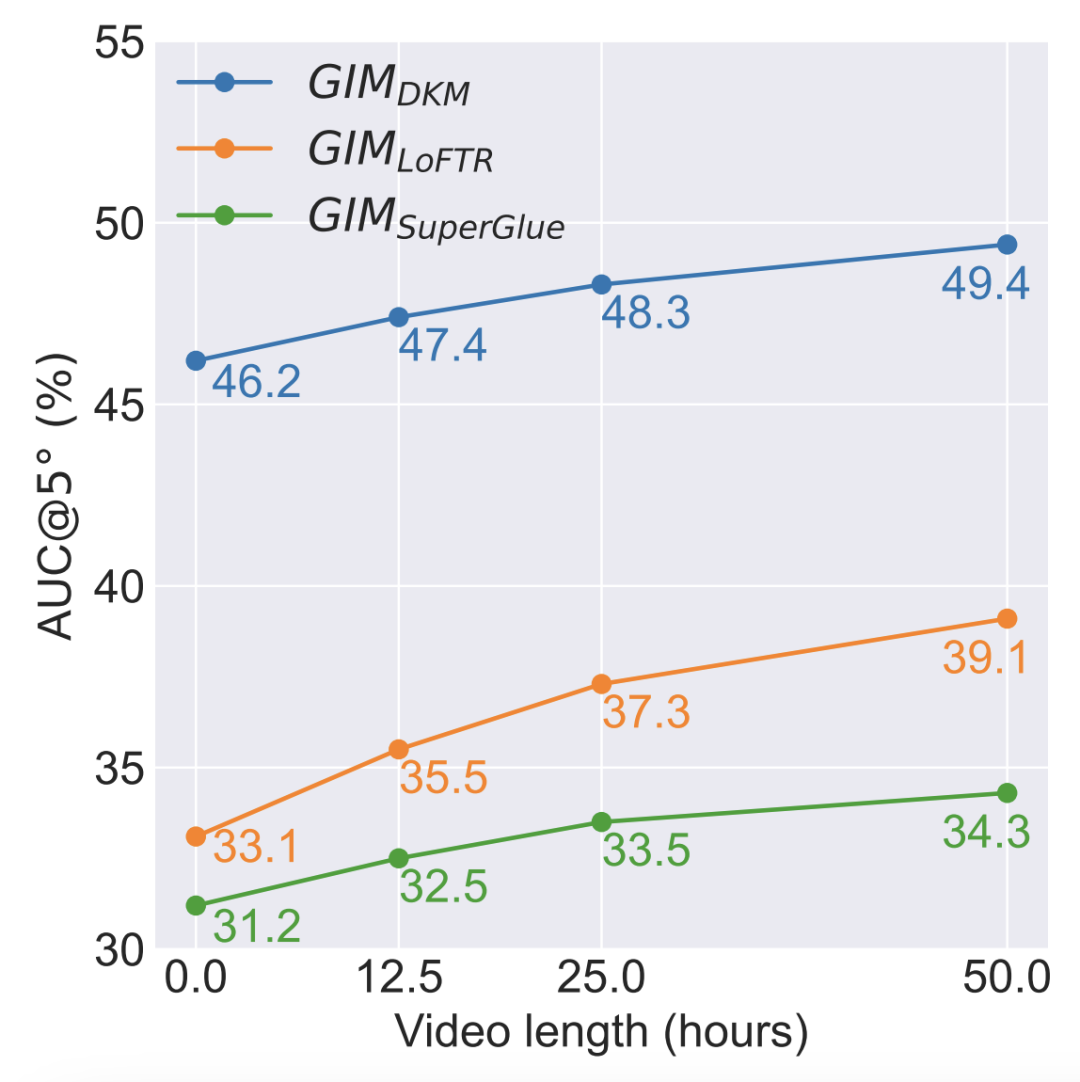 图 2. 用于训练的视频时长和模型泛化性能的关系
图 2. 用于训练的视频时长和模型泛化性能的关系
为了能充分衡量一个匹配模型的泛化性能,作者提出了第一个 Zero-shot Evaluation Benchmark (ZEB)。如图 3 所示,ZEB 由 12 个涵盖各种场景、天气和相机模型的公开数据集组成,大约包含 4.6 万对测试图片。ZEB 所包含的数据数量远多于现有方法普遍采用的,由 MegaDepth 和 ScanNet 组成,仅包含 3000 对图像的测试集。
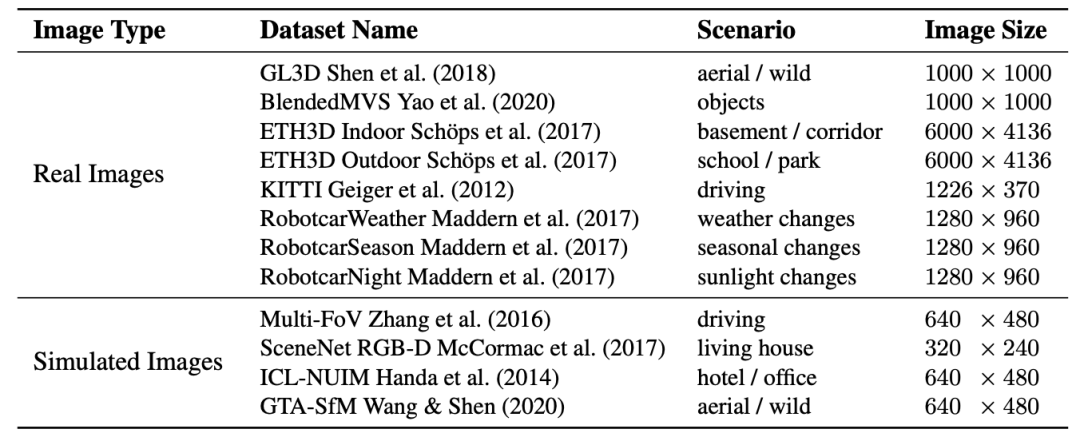
图 3.ZEB 的组成情况
图 2 中的模型泛化性能正是来自 ZEB 的评估结果,具体的评估结果在图 4 展示。Mean Rank 指标代表匹配模型在 12 个测试序列中的平均排名,排名越接近于 1 越好。Mean AUC@5° 代表匹配模型对姿态估计的准确度,数值越高越好。
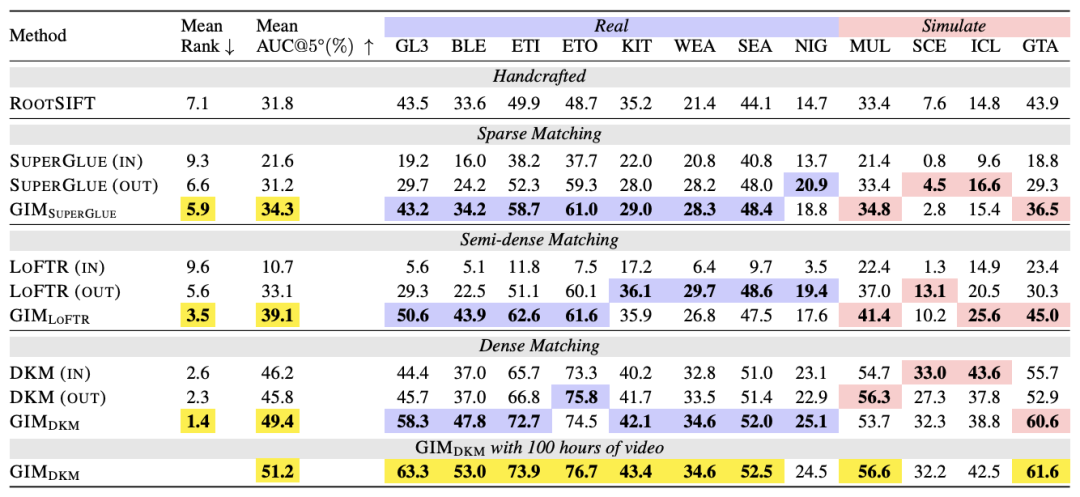
图 4. 匹配模型泛化性能评估结果
从图 4 可以看到,GIM 可以明显地提升匹配模型的泛化性能。在被 GIM 训练前,SuperGlue 和 LoFTR 在 GL3、BLE 和 GTA 序列中甚至不如传统算法 RootSIFT。在被 GIM 训练后,这两个模型的泛化性能都得到了极大的提升。
正如刚才所说,50 小时的视频数据还远未让模型的性能达到极限。按照作者最新的 100 小时视频数据训练结果,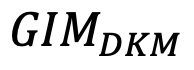 的性能已经可以达到 51.2,远超现有的模型。
的性能已经可以达到 51.2,远超现有的模型。
如图 5 所示,匹配模型的泛化性能提升,同样会为下游任务带来增益。值得注意的是,在图 5 的重定位任务中,GIM 都是仅以一个模型和其他特定场景的模型进行对比,但依然能取得更好的结果。
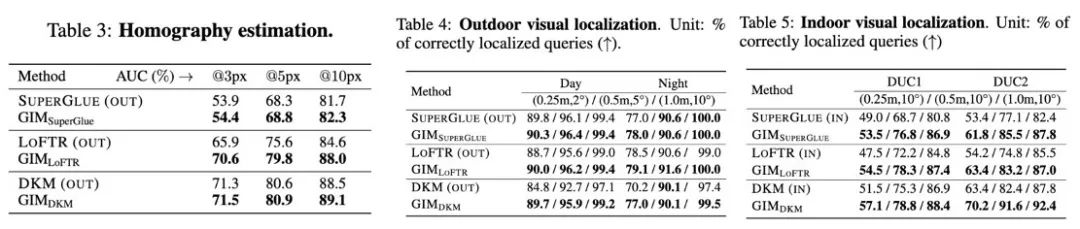
图 5. 匹配模型在下游任务:单应性矩阵估计、室内和室外重定位任务下的性能表现
双视图图像匹配的结果如下图所示:

图 6. 匹配模型在双视图匹配下的可视化结果
除此之外,如图 7 所示,GIM 模型强大的泛化性能还可以处理训练中从未见过的点云鸟瞰图匹配任务。

图 7. 匹配模型在点云鸟瞰图匹配下的可视化结果
作为多视图重建的通用方法,COLMAP 被广泛地应用于如 visual localization,neural rendering 等下游任务。将 COLMAP 中的匹配方法替换成 GIM,多视图重建的效果更好,这极大程度地提升了 COLMAP 的鲁棒性。

图 8. 不同匹配模型对多视图重建的影响。第一行是部分重建图像的展示。第二行是重建的结果展示。读者感兴趣可以去论文主页和介绍视频中观看动态可交互的结果。
由于 GIM 能够有效提升 COLMAP 多视角重建的质量,因此,GIM 也能为对应的下游任务中「增光添彩」,下面几张图展示了用 GIM 的 COLMAP 结果来初始化 Gaussian Splatting 的效果。可以看到在一些有挑战性的场景中,基于 SIFT 和 DKM 的 COLMAP 都不能够很好地提供有效的 initialization,导致渲染效果不佳。



图 9. 不同匹配模型在多视图重建后对 Gaussian Splatting 的影响。读者感兴趣可以去论文主页和介绍视频中观看动态结果。
框架方法
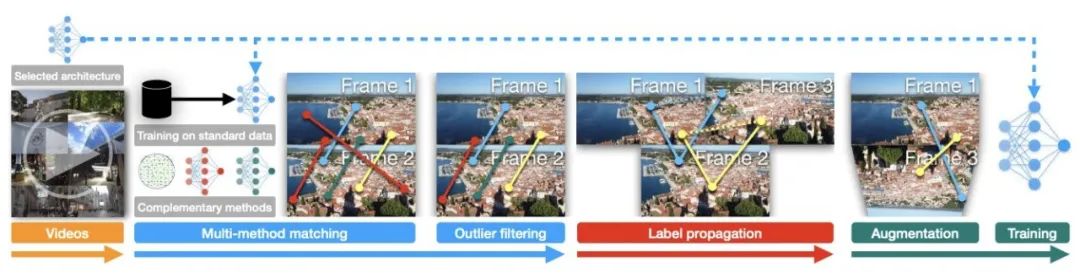
图 10.GIM 框架
GIM 框架的方法很简洁,方法的核心在于利用视频中帧和帧之间的连续性,将匹配从短距离的帧传递到长距离的帧上,以此获取宽基线的训练图像。
第一步,准备一个用于训练的匹配模型和互联网视频。
第二步,用标准训练数据(非互联网视频,如 MegaDepth)训练匹配模型,然后再收集其他补充的匹配方法,用所有这些方法在互联网视频上的短距离间隔的帧上进行匹配,获取较为密集的匹配结果。再用 outlier filtering 过滤一遍匹配。
第三步,利用视频的时序关系,将匹配传递到更远的帧上,得到重合度较低和基线较宽的训练图像对。
最后,对传递后的图像对及其匹配标签进行数据增强并进行训练。
下图是 GIM 在互联网视频上生成的匹配标签可视化。这仅仅是极小的一部分,用于训练的数据的多样性远远多于作者能展示出来的图片。

图 11. 部分互联网视频标签的可视化
总结
GIM 的提出受到了 GPT 等大模型的启发,促使作者用海量的视频数据去训练匹配模型,并达到更高的泛化性能。GIM 的主页的地址是 xuelunshen.com/gim。欢迎大家跳转到 GIM 的主页,浏览更详细生动的介绍视频、开源的代码,在线体验 GIM 匹配效果的 HuggingFace Demo。
Blog: https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/Intel-Labs-Research-Work-Receives-Spotlight-Award-at-Top-AI/post/1575985
CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态和扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









