






【引用格式】:Shen X, Yin W, Müller M, et al. GIM: Learning Generalizable Image Matcher From Internet Videos[C]//The Twelfth International Conference on Learning Representations. 2023.
【网址】:https://arxiv.org/pdf/2402.11095
【开源代码】:https://github.com/xuelunshen/gim
目录
1.1 Multi-method matching(多方法匹配)
1.3 Strong data augmentation(数据增强)
2. ZEB: Zero-shot Evaluation Benchmark For Image Matching
一、瓶颈问题
- 现有的基于学习的图像匹配方法在特定数据集上表现良好,但在现实世界图像泛化能力不足,特別是在面对不同场景类型时。【泛化能力差】
- 现有图像匹配数据集的多样性和规模有限。【数据集局限】
- 依赖于RGBD扫描或SfM+MVS的数据集构建方法效率有限,不适合大规模数据和模型训练。【方法局限】
二、本文贡献
- 提出了GIM,一个自训练框架,用于学习基于任何使用互联网视频的图像匹配框架的单个可泛化模型。
- 提出了一种用于图像匹配的零样本评估基准ZEB。
三、解决方案
文中指出,训练图像匹配模型需要多视图图像和ground-truth对应关系,数据多样性和规模是其他计算机视觉问题中可泛化模型的关键。为此,文中提出了一个利用互联网视频的自训练框架GIM,基于任何图像匹配架构学习单个可泛化模型。

GIM可以使用各种视频,但由于互联网视频自然多样且几乎是无限的,文中采用了来自YouTube的50小时的视频,涵盖了26个国家、43个城市、各种闪电条件、动态对象和场景类型。
标准图像匹配基准由RGBD或COLMAP(SfM+MVS)创建。但是,RGBD扫描需要对场景进行物理访问,很难从不同的环境中获取数据。COLMAP对于视图覆盖密集的地标型场景是有效的,但是它的效率有限,并且在具有任意运动的野外数据上往往失败。尽管目前已有的数据集中有数百万个图像,但由于数千个图像来自一个小场景,多样性是有限的。与之相比,互联网视频不是以地标为中心的,一个小时的旅游视频通常涵盖几公里的范围,并且具有广泛的传播视点,视频中的时间信息还允许我们显著增强监督信号。
1. self-training
从视频数据中学习的一种简单方法是使用标准的基于COLMAP生成标签;通过文中实验证明它是低效的,并且容易在野外视频中失败。为此,GIM依赖于自训练,首先在标准数据集上训练模型,然后利用训练模型的增强输出(视频)来提高相同架构的泛化能力。
1.1 Multi-method matching(多方法匹配)
GIM框架首先选定一个图像匹配框架,并在标准的领域特定数据集上进行训练,来获得一个基础模型,作为“基础标签生成器”。对于每个视频,GIM均匀地采样图像,每隔20帧采样一次,以减少冗余。对于每个采样得到的帧X,GIM生成帧X与X+20、X+40和X+80之间的基础对应关系。这些对应关系通过在基础标签生成器的输出上运行鲁棒拟合算法【MAGSAC: Marginalizing Sample Consensus】来得到,实现过滤掉异常值的目的。最后通过融合不同方法生成的对应关系,GIM能够创建一个更加密集和可靠的对应关系集合。
1.2 Label propagation(标签传播)
标签传播目的是利用视频中帧之间的密集对应关系,将已经确定的对应关系从近邻帧扩展到更远的帧,从而增强帧信号并提高模型的泛化能力。文中定义作为图像
和
之间的对应关系矩阵,其中
和
分别是
和
中的像素数。矩阵中的元素
表示
中的第i个像素与
中的第j个像素对应。通过给定的两幅图对应关系
和
,来获得对应关系
。对于
中的每个非零元素
,如果在
中也存在一个
,并且IB中的j和j'之间的距离小于1像素,则在
中设置
,故
和
在位置(i,k)上存在对应关系。
为了获得强监督信号,文中设置,只要两幅图像之间存在超过1024个一应关系,就尽可能远地传播这些对应关系,传播是在每个采样帧(20帧间隔)上单独执行的。在每个传播步骤之后,文中将具有对应关系的每个图像对的帧间隔加倍。例如,最初文中在每个 20、40 和 80 帧之间都有基本对应关系。经过 1 轮传播后,文中将每 20 帧的基本对应关系传播到每 40 帧,并将传播的对应关系与基本对应合并。现在文中有了每 40 帧的合并对应关系,文中执行相同的操作来为每 80 帧生成合并的对应关系。由于文中没有超过 80 帧的基本对应关系,因此剩余的传播轮次不执行合并操作并保持帧间隔加倍,直到文中没有超过 1024 个对应关系。文中强制最小对应数为1024,目的是为了使模型不偏向于困难或容易的样本。
1.3 Strong data augmentation(数据增强)
数据增强是为了在训练过程中提供更好的监督信号,帮助模型学习到更加鲁棒的特征表示。文中在处理视频数据时,对于每对视频帧,文中在现有方法中使用的标准增强之外执行随机透视转换,以达到缓解两个视频帧的相机模型相同且相机大多位于正面,没有太多的滚动旋转的问题。
2. ZEB: Zero-shot Evaluation Benchmark For Image Matching

现有的图像匹配框架通常在同一域内数据集 (MegaDepth 上训练和评估模型用于室外模型和 ScanNet用于室内模型)。为了分析单个模型对野外数据的鲁棒性,文中通过合并8个真实数据集和4个具有不同图像分辨率、场景条件和视图点的模拟数据集来构建一个新的评估基准ZEB。
对于每个数据集,文中从5个图像重叠率(从10%到50%)中统一采样大约3800个评估图像对。因此,最终的 ZEB 基准包含来自各种场景和重叠比的 46K 评估图像对,与现有方法中使用的 1500 个域内图像对相比,其多样性和规模要大得多。
下面实验的度量标准:
按照标准评估协议 ,文中报告了 5° 内相对位姿误差的 AUC,其中位姿误差是旋转角误差和平移角误差之间的最大。相对位姿是通过使用图像匹配方法和RANSAC的输出对应关系来估计基本矩阵来获得的。遵循零样本计算机视觉文献【Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer】,文中还提供了 12 个跨域数据集的平均性能排名。
四、实验结果
1、主要结果
1.1 零样本匹配性能的比较结果
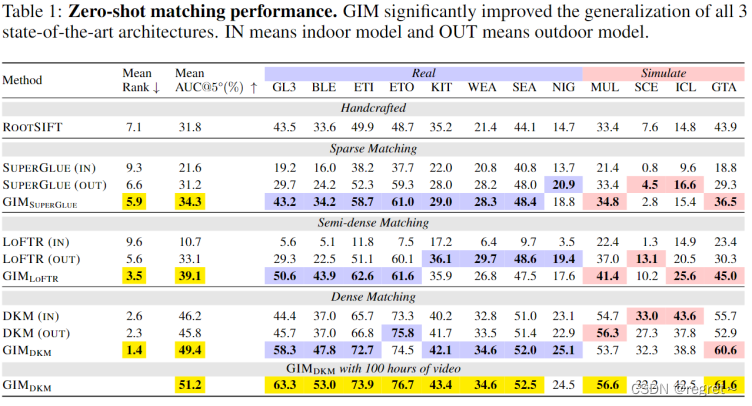
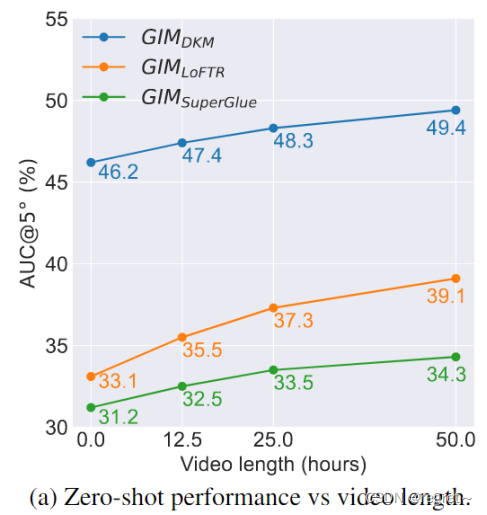
1.2 双视图几何




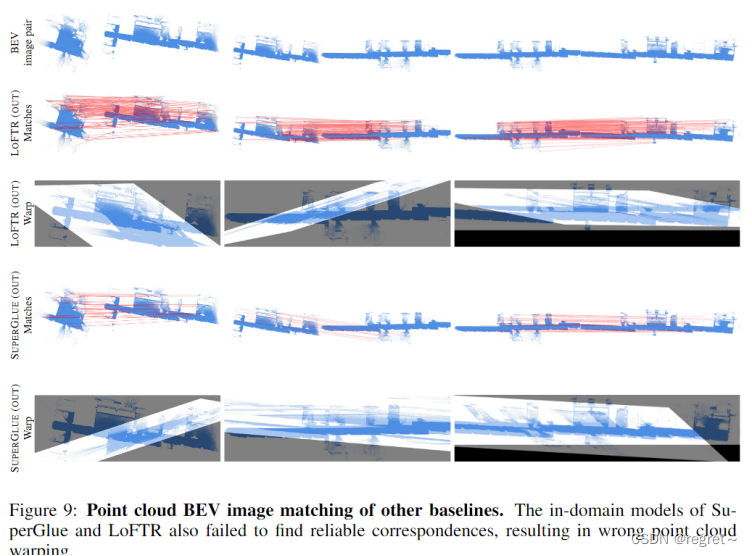
1.3 多视图重建

1.4 域内性能
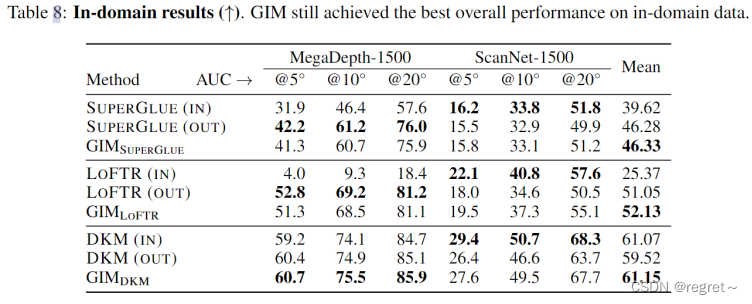
域内数据仍然可以取得整体最好的性能(室内室外平均)
2. 消融实验

3. 应用
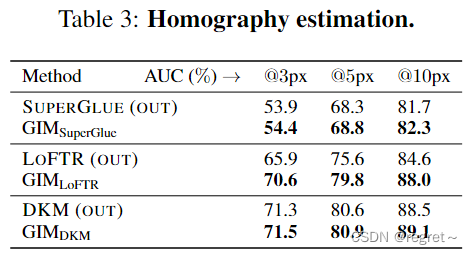
3.1 单应性估计
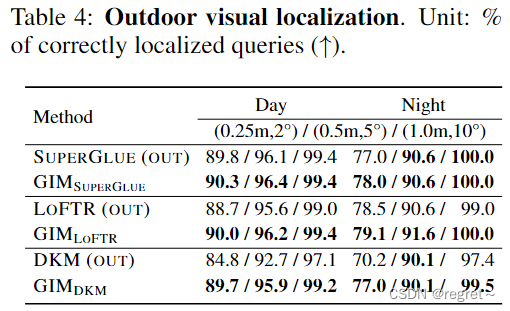
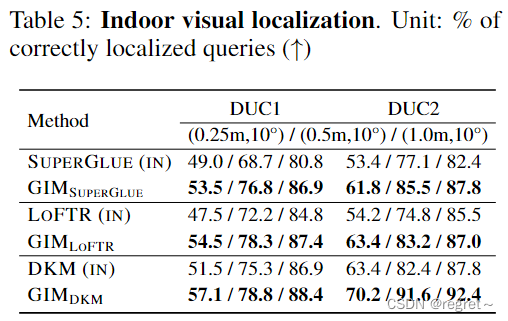
3.2 视觉定位















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









