






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:机器之心
既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?
序列建模的进展具有极大的影响力,因为它们在广泛的应用中发挥着重要作用,包括强化学习(例如,机器人和自动驾驶)、时间序列分类(例如,金融欺诈检测和医学诊断)等。
在过去的几年里,Transformer 的出现标志着序列建模中的一个重大突破,这主要得益于 Transformer 提供了一种能够利用 GPU 并行处理的高性能架构。
然而,Transformer 在推理时计算开销很大,主要在于内存和计算需求呈二次扩展,从而限制了其在低资源环境中的应用(例如,移动和嵌入式设备)。尽管可以采用 KV 缓存等技术提高推理效率,但 Transformer 对于低资源领域来说仍然非常昂贵,原因在于:(1)随 token 数量线性增加的内存,以及(2)缓存所有先前的 token 到模型中。在具有长上下文(即大量 token)的环境中,这一问题对 Transformer 推理的影响更大。
为了解决这个问题,加拿大皇家银行 AI 研究所 Borealis AI、蒙特利尔大学的研究者在论文《Attention as an RNN 》中给出了解决方案。值得一提的是,我们发现图灵奖得主 Yoshua Bengio 出现在作者一栏里。

论文地址:https://arxiv.org/pdf/2405.13956
论文标题:Attention as an RNN
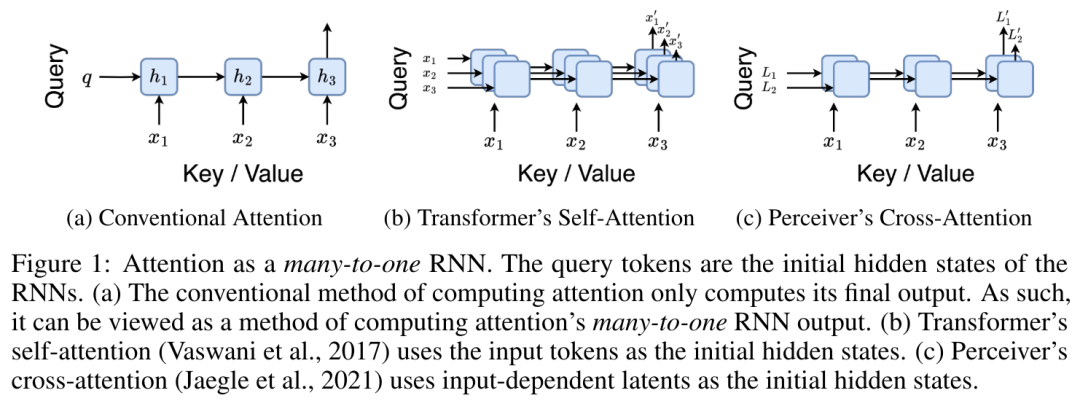
具体而言,研究者首先检查了 Transformer 中的注意力机制,这是导致 Transformer 计算复杂度呈二次增长的组件。该研究表明注意力机制可以被视为一种特殊的循环神经网络(RNN),具有高效计算的多对一(many-to-one)RNN 输出的能力。利用注意力的 RNN 公式,该研究展示了流行的基于注意力的模型(例如 Transformer 和 Perceiver)可以被视为 RNN 变体。
然而,与 LSTM、GRU 等传统 RNN 不同,Transformer 和 Perceiver 等流行的注意力模型虽然可以被视为 RNN 变体。但遗憾的是,它们无法高效地使用新 token 进行更新。
为了解决这个问题,该研究引入了一种基于并行前缀扫描(prefix scan)算法的新的注意力公式,该公式能够高效地计算注意力的多对多(many-to-many)RNN 输出,从而实现高效的更新。
在此新注意力公式的基础上,该研究提出了 Aaren([A] ttention [a] s a [re] current neural [n] etwork),这是一种计算效率很高的模块,不仅可以像 Transformer 一样并行训练,还可以像 RNN 一样高效更新。
实验结果表明,Aaren 在 38 个数据集上的表现与 Transformer 相当,这些数据集涵盖了四种常见的序列数据设置:强化学习、事件预测、时间序列分类和时间序列预测任务,同时在时间和内存方面更加高效。
方法介绍
为了解决上述问题,作者提出了一种基于注意力的高效模块,它能够利用 GPU 并行性,同时又能高效更新。
首先,作者在第 3.1 节中表明,注意力可被视为一种 RNN,具有高效计算多对一 RNN(图 1a)输出的特殊能力。利用注意力的 RNN 形式,作者进一步说明,基于注意力的流行模型,如 Transformer(图 1b)和 Perceiver(图 1c),可以被视为 RNN。然而,与传统的 RNN 不同的是,这些模型无法根据新 token 有效地更新自身,从而限制了它们在数据以流的形式到达的序列问题中的潜力。
为了解决这个问题,作者在第 3.2 节中介绍了一种基于并行前缀扫描算法的多对多 RNN 计算注意力的高效方法。在此基础上,作者在第 3.3 节中介绍了 Aaren—— 一个计算效率高的模块,它不仅可以并行训练(就像 Transformer),还可以在推理时用新 token 高效更新,推理只需要恒定的内存(就像传统 RNN)。
将注意力视为一个多对一 RNN
查询向量 q 的注意力可被视为一个函数,它通过 N 个上下文 token x_1:N 的键和值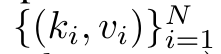 将其映射到单一输出 o_N = Attention (q, k_1:N , v_1:N ) 。给定 s_i = dot (q,k_i),输出 o_N 可表述为:
将其映射到单一输出 o_N = Attention (q, k_1:N , v_1:N ) 。给定 s_i = dot (q,k_i),输出 o_N 可表述为:

其中分子为 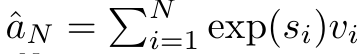 ,分母为
,分母为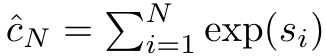 。将注意力视为 RNN,可以在 k = 1,...,...... 时,以滚动求和的方式迭代计算
。将注意力视为 RNN,可以在 k = 1,...,...... 时,以滚动求和的方式迭代计算 和
和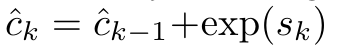 。然而,在实践中,这种实现方式并不稳定,会因有限的精度表示和可能非常小或非常大的指数(即 exp (s))而遇到数值问题。为了缓解这一问题,作者用累积最大值项
。然而,在实践中,这种实现方式并不稳定,会因有限的精度表示和可能非常小或非常大的指数(即 exp (s))而遇到数值问题。为了缓解这一问题,作者用累积最大值项 来重写递推公式,计算
来重写递推公式,计算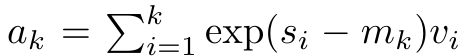 和
和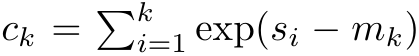 。值得注意的是,最终结果是相同的
。值得注意的是,最终结果是相同的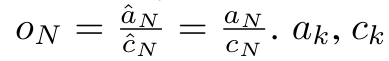 ,m_k 的循环计算如下:
,m_k 的循环计算如下:
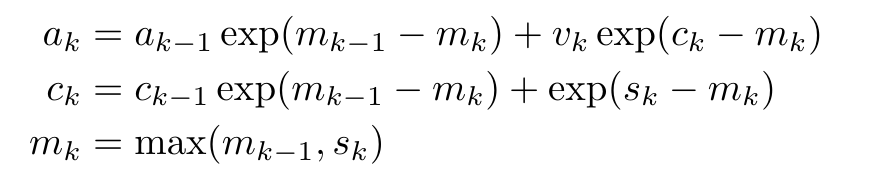
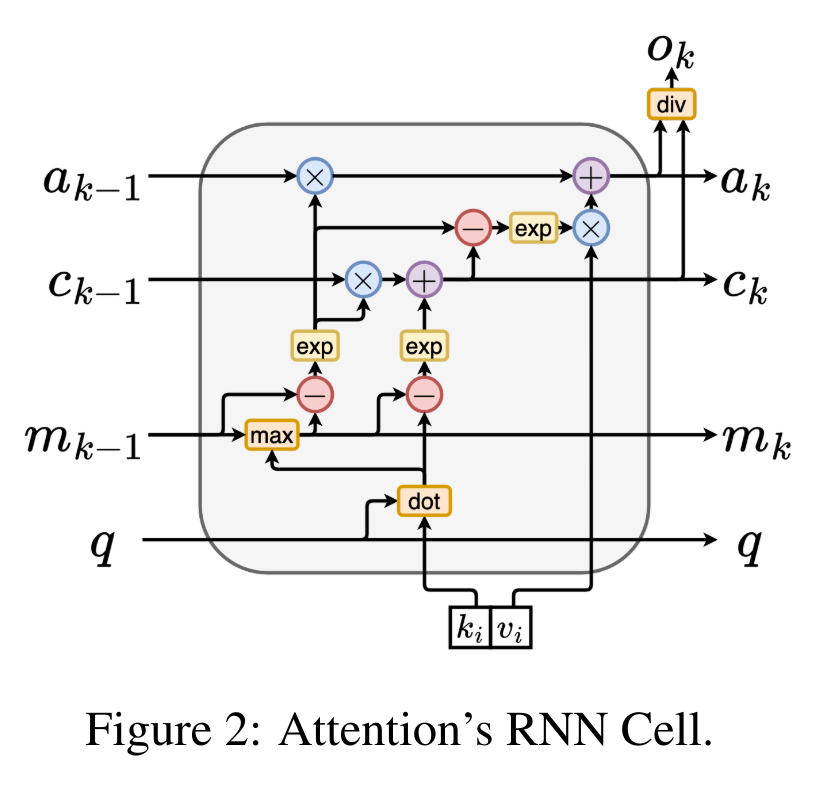
通过从 a_(k-1)、c_(k-1) 和 m_(k-1) 对 a_k、c_k 和 m_k 的循环计算进行封装,作者引入了一个 RNN 单元,它可以迭代计算注意力的输出(见图 2)。注意力的 RNN 单元以(a_(k-1), c_(k-1), m_(k-1), q)作为输入,并计算(a_k, c_k, m_k, q)。注意,查询向量 q 在 RNN 单元中被传递。注意力 RNN 的初始隐藏状态为 (a_0, c_0, m_0, q) = (0, 0, 0, q)。
计算注意力的方法:通过将注意力视为一个 RNN,可以看到计算注意力的不同方法:在 O (1) 内存中逐个 token 循环计算(即顺序计算);或以传统方式计算(即并行计算),需要线性 O (N) 内存。由于注意力可以被看作是一个 RNN,因此计算注意力的传统方法也可以被看作是计算注意力多对一 RNN 输出的高效方法,即 RNN 的输出以多个上下文 token 为输入,但在 RNN 结束时只输出一个 token(见图 1a)。最后,也可以将注意力计算为一个逐块处理 token 的 RNN,而不是完全按顺序或完全并行计算,这需要 O (b) 内存,其中 b 是块的大小。
将现有的注意力模型视为 RNN。通过将注意力视为 RNN,现有的基于注意力的模型也可以被视为 RNN 的变体。例如,Transformer 的自注意力是 RNN(图 1b),上下文 token 是其初始隐藏状态。Perceiver 的交叉注意力是 RNN(图 1c),其初始隐藏状态是与上下文相关的潜变量。通过利用其注意力机制的 RNN 形式,这些现有模型可以高效地计算其输出存储。
然而,当将现有的基于注意力的模型(如 Transformers)视为 RNN 时,这些模型又缺乏传统 RNN(如 LSTM 和 GRU)中常见的重要属性。
值得注意的是,LSTM 和 GRU 能够仅在 O (1) 常量内存和计算中使用新 token 有效地更新自身,相比之下, Transformer 的 RNN 视图(见图 1b)会通过将一个新的 token 作为初始状态添加一个新的 RNN 来处理新 token。这个新的 RNN 处理所有先前的 token,需要 O (N) 的线性计算量。
在 Perceiver 中,由于其架构的原因,潜变量(图 1c 中的 L_i)是依赖于输入的,这意味着它们的值在接收新 token 时会发生变化。由于其 RNN 的初始隐藏状态(即潜变量)发生变化,Perceiver 因此需要从头开始重新计算其 RNN,需要 O (NL) 的线性计算量,其中 N 是 token 的数量,L 是潜变量的数量。
将注意力视为一个多对多 RNN
针对这些局限性,作者建议开发一种基于注意力的模型,利用 RNN 公式的能力来执行高效更新。为此,作者首先引入了一种高效的并行化方法,将注意力作为多对多 RNN 计算,即并行计算 的方法。为此,作者利用并行前缀扫描算法(见算法 1),这是一种通过关联算子 ⊕ 从 N 个连续数据点计算 N 个前缀的并行计算方法。该算法可高效计算
的方法。为此,作者利用并行前缀扫描算法(见算法 1),这是一种通过关联算子 ⊕ 从 N 个连续数据点计算 N 个前缀的并行计算方法。该算法可高效计算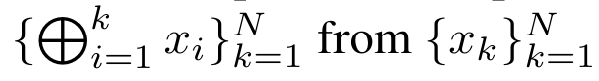

回顾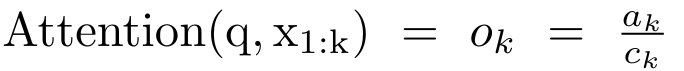 ,其中
,其中 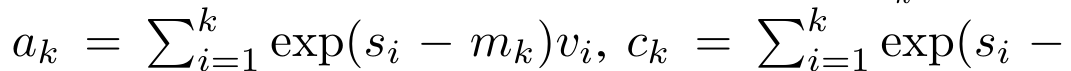
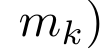 ,
,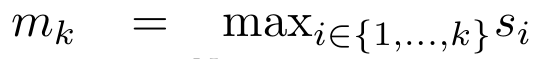 为了高效计算
为了高效计算 ,可以通过并行扫描算法计算
,可以通过并行扫描算法计算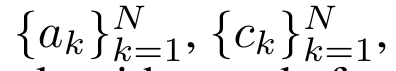 和
和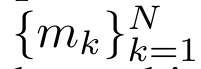 ,然后结合 a_k 和 c_k 计算
,然后结合 a_k 和 c_k 计算 。
。
为此,作者提出了以下关联算子⊕,该算子作用于形式为(m_A、u_A、w_A)的三元组,其中 A 是一组索引,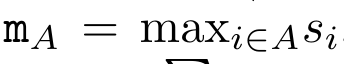 ,
,
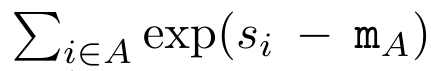 ,
,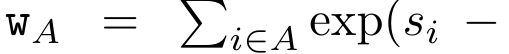
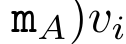 。并行扫描算法的输入为
。并行扫描算法的输入为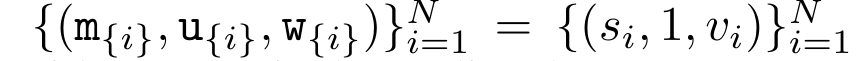 。该算法递归应用算子 ⊕,其工作原理如下:
。该算法递归应用算子 ⊕,其工作原理如下:
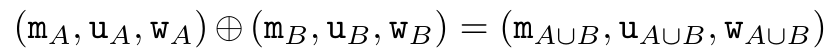 ,其中,
,其中,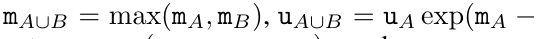
 ,
,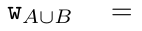
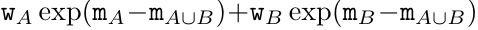 。
。
在完成递归应用算子后,算法输出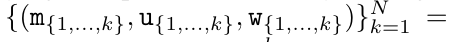

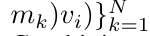 。也被称作
。也被称作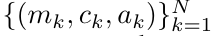 。结合输出元组的最后两个值,检索
。结合输出元组的最后两个值,检索 从而产生一种高效的并行方法,将注意力计算为多对多 RNN(图 3)。
从而产生一种高效的并行方法,将注意力计算为多对多 RNN(图 3)。

Aaren:[A] ttention [a] s a [re] current neural [n] etwork
Aaren 的接口与 Transformer 相同,即将 N 个输入映射到 N 个输出,而第 i 个输出是第 1 到第 i 个输入的聚合。此外,Aaren 还自然可堆叠,并且能够计算每个序列 token 的单独损失项。然而,与使用因果自注意力的 Transformers 不同,Aaren 使用上述计算注意力的方法作为多对多 RNN,使其更加高效。Aaren 形式如下:
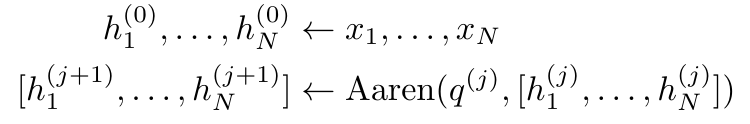
与 Transformer 不同,在 Transformer 中查询是输入到注意力的 token 之一,而在 Aaren 中,查询 token q 是在训练过程中通过反向传播学习得到的。
下图展示了一个堆叠 Aaren 模型的例子,该模型的输入上下文 token 为 x_1:3,输出为 y_1:3。值得注意的是,由于 Aaren 利用了 RNN 形式的注意力机制,堆叠 Aarens 也相当于堆叠 RNN。因此,Aarens 也能够高效地用新 token 进行更新,即 y_k 的迭代计算仅需要常量计算,因为它仅依赖于 h_k-1 和 x_k。
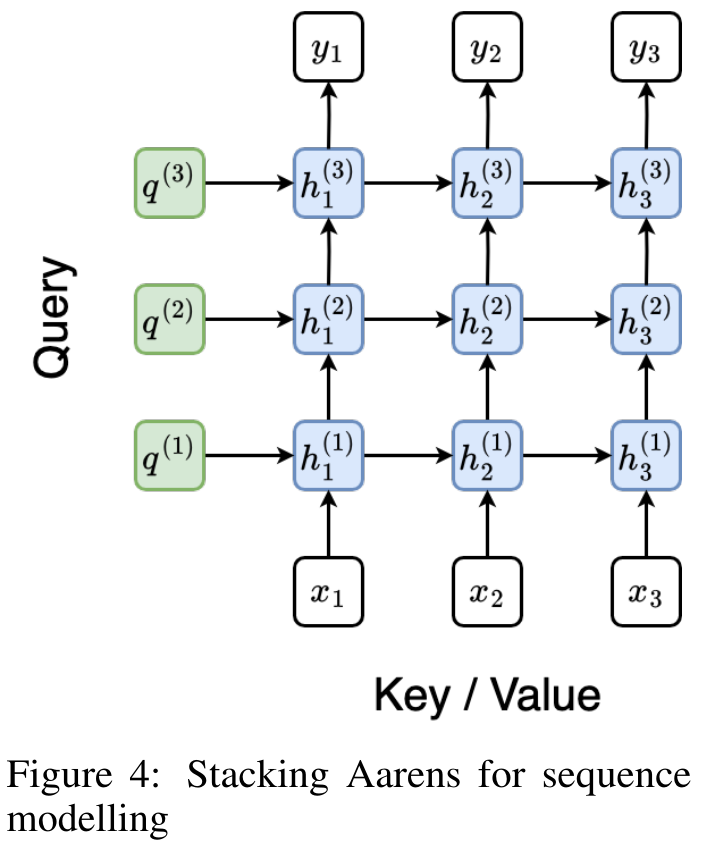
基于 Transformer 的模型需要线性内存(使用 KV 缓存时)并且需要存储所有先前的 token ,包括中间 Transformer 层中的那些,但基于 Aaren 的模型只需要常量内存,并且不需要存储所有先前的 token ,这使得 Aarens 在计算效率上显著优于 Transformer。
实验
实验部分的目标是比较 Aaren 和 Transformer 在性能和所需资源(时间和内存)方面的表现。为了进行全面比较,作者在四个问题上进行了评估:强化学习、事件预测、时间序列预测和时间序列分类。
强化学习
作者首先比较了 Aaren 和 Transformer 在强化学习方面的表现。强化学习在机器人、推荐引擎和交通控制等交互式环境中很受欢迎。
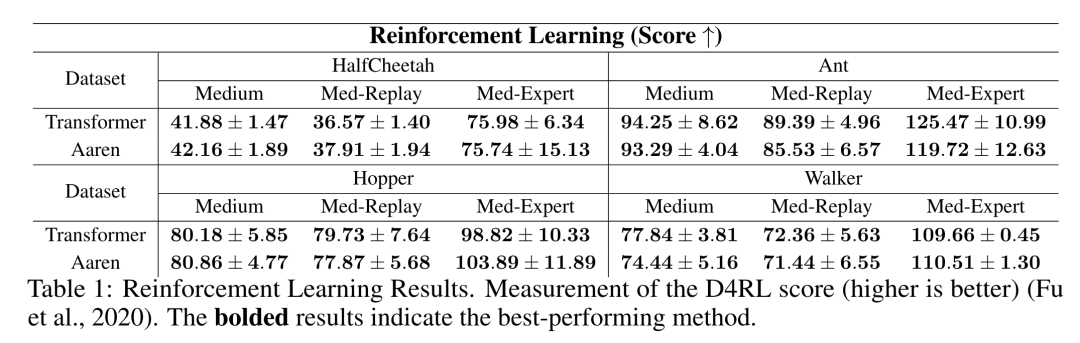
表 1 中的结果表明,在所有 12 个数据集和 4 种环境中,Aaren 与 Transformer 的性能都不相上下。不过,与 Transformer 不同的是,Aaren 也是一种 RNN,因此能够在持续计算中高效处理新的环境交互,从而更适合强化学习。
事件预测
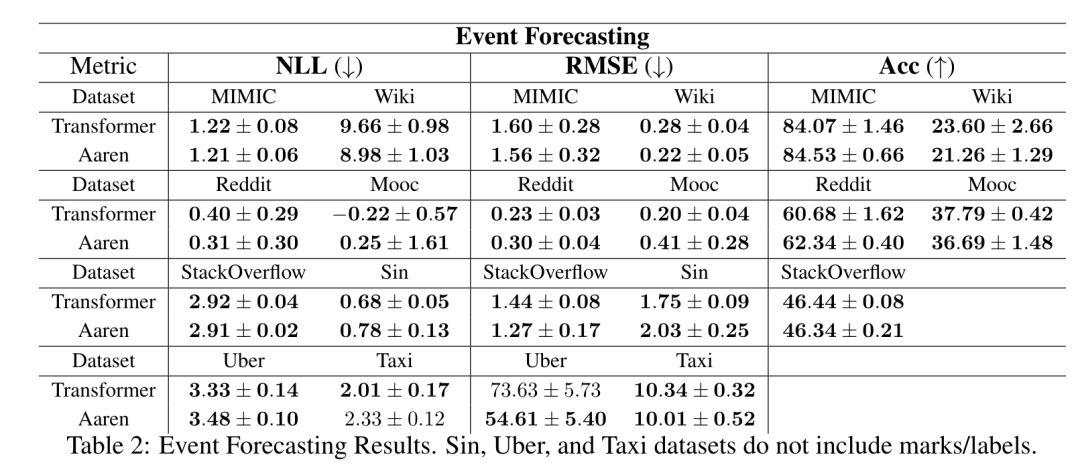
接下来,作者比较了 Aaren 和 Transformer 在事件预测方面的表现。事件预测在许多现实环境中都很流行,例如金融(如交易)、医疗保健(如患者观察)和电子商务(如购买)。
表 2 中的结果显示,Aaren 在所有数据集上的表现都与 Transformer 相当。Aaren 能够高效处理新输入,这在事件预测环境中尤为有用,因为在这种环境中,事件会以不规则流的形式出现。
时间序列预测
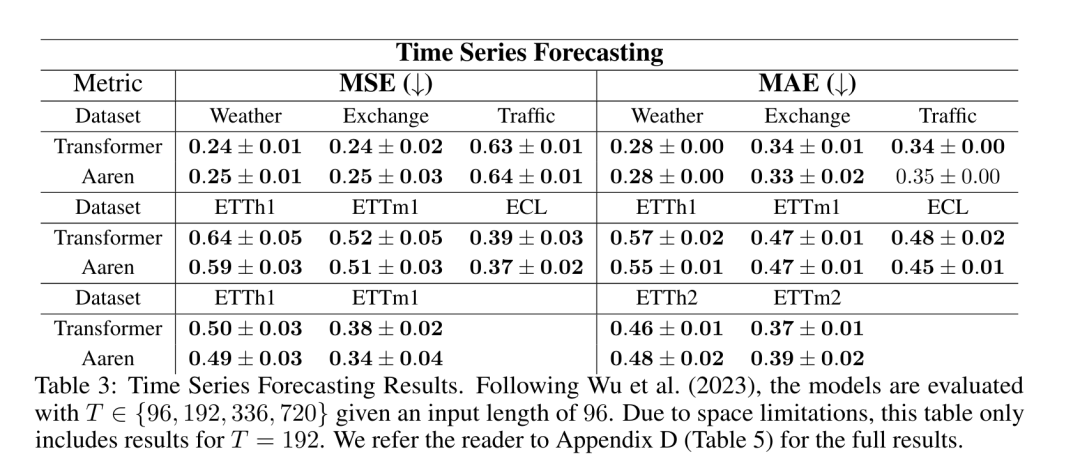
然后,作者比较了 Aaren 和 Transformer 在时间序列预测方面的表现。时间序列预测模型通常用在与气候(如天气)、能源(如供需)和经济(如股票价格)相关的领域。
表 3 中的结果显示,在所有数据集上,Aaren 与 Transformer 的性能相当。不过,与 Transformer 不同的是,Aaren 能高效处理时间序列数据,因此更适合与时间序列相关的领域。
时间序列分类
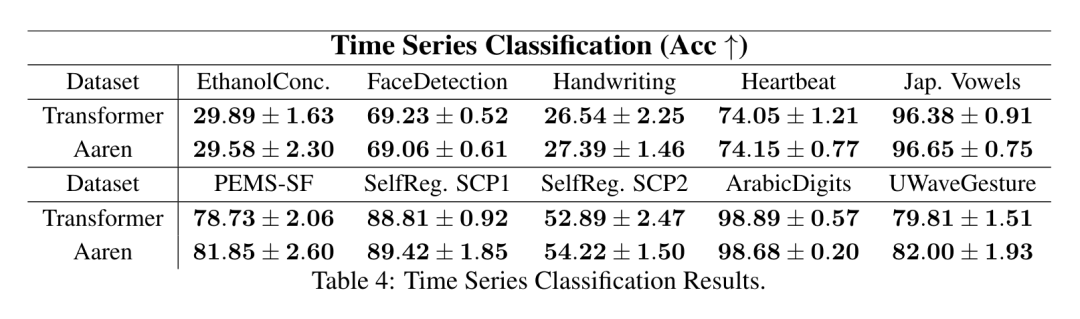
接下来,作者比较了 Aaren 和 Transformer 在时间序列分类方面的表现。时间序列分类在许多重要的应用中很常见,例如模式识别(如心电图)、异常检测(如银行欺诈)或故障预测(如电网波动)。
从表 4 中可以看出,在所有数据集上,Aaren 与 Transformer 的表现不相上下。
分析
最后,作者比较了 Aaren 和 Transformer 所需的资源。
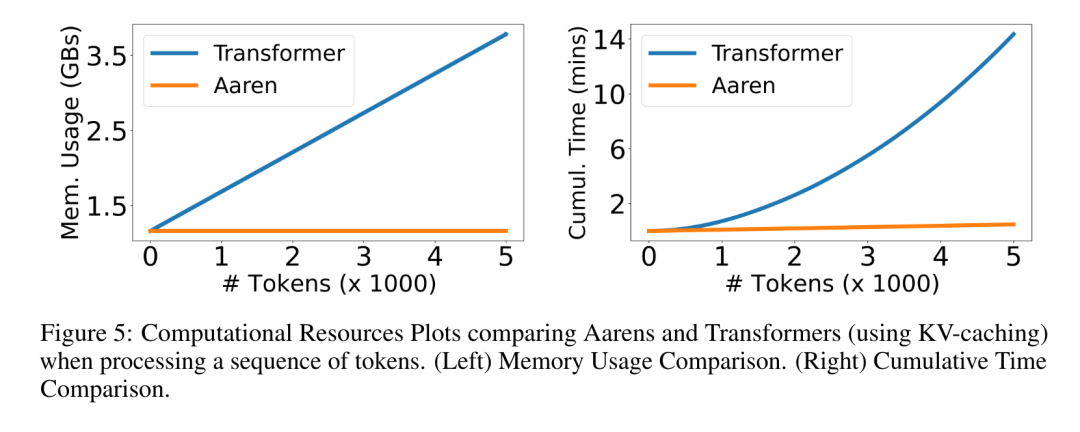
内存复杂性:在图 5(左)中,作者比较了 Aaren 和 Transformer(使用 KV 缓存)在推理时的内存使用情况。可以看到,伴随 KV 缓存技术的使用,Transformer 的内存使用量呈线性增长。相比之下,Aaren 只使用恒定的内存,无论 token 数量如何增长,因此它的效率要高得多。
时间复杂度:在图 5(右图)中,作者比较了 Aaren 和 Transformer(使用 KV 缓存)按顺序处理一串 token 所需的累计时间。对于 Transformer,累计计算量是 token 数的二次方,即 O (1 + 2 + ... + N) = O (N^2 )。相比之下,Aaren 的累计计算量是线性的。在图中,可以看到模型所需的累计时间也是类似的结果。具体来说,Transformer 所需的累计时间呈二次增长,而 Aaren 所需的累计时间呈线性增长。
参数数量:由于要学习初始隐藏状态 q,Aaren 模块需要的参数略多于 Transformer 模块。不过,由于 q 只是一个向量,因此差别不大。通过在同类模型中进行实证测量,作者发现 Transformer 使用了 3, 152, 384 个参数。相比之下,等效的 Aaren 使用了 3, 152, 896 个参数,参数增加量仅为 0.016%—— 对于内存和时间复杂性的显著差异来说,这只是微不足道的代价。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看














 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









