






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

作者:庞子奇
https://zhuanlan.zhihu.com/p/703340384
宣传一下这次CVPR 2024的工作——我们试图理解并尝试对于更长/更难的视频理解,什么样的Temporal Information是有用的。具体在Video Object Segmentation的任务上,我们发现用一个精简而且有限的Memory Bank筛选和存储Temporal Information,要比盲目地存储所有时段的信息更有用。
我们的【精简Memory Bank】被我们称作“Restricted Memory Banks” (RMem),它表面上利用了更少的信息,但是实际上却显著地在视频理解最难的两个场景下取得了显著的提升:(1) 长视频理解,顾名思义,视频有更多的帧(the Long Videos Dataset & LVOS) (2) Egocentric State Changes,物体会经历大量的形变、遮挡、移出视频等等 (VOST)。
因为最近越来越多的研究开始关注视频理解,我们希望“精简信息”这个既对Efficiency友好,又对Performance有帮助的原则可以帮助到更多的人——我们不需要害怕扔掉信息,我们只需要确认【自己扔掉的是冗余的信息】【自己留下的是有用的信息】。
论文已经在Arxiv上公开并开源代码,欢迎大家Star、关注:

主页:https://restricted-memory.github.io/
代码:https://github.com/Restricted-Memory/RMem
论文:https://arxiv.org/abs/2406.08476
1. 在视频理解中,什么是精简的Memory Bank,它有什么好处?
在视频理解中,大家总会认为“我的信息越多越好” ——基于这个非常直观的信念,大家普遍的做法是“让我们不停地采样一些关键帧放在我们的Memory Bank里吧,总能用上的。”
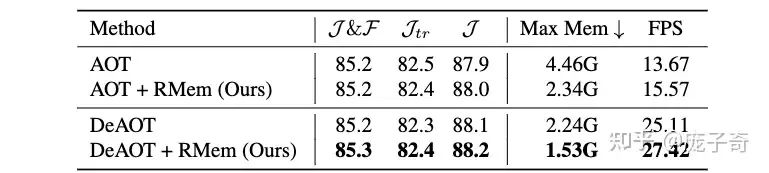
不过事实就是,我们采用了一个简单的Baseline——固定Memory Bank的大小(比如说就存8帧),然后每次把最老的一帧踢出去。它看起来损失了信息,但是却为Video Object Segmentation带来了显著的提升:
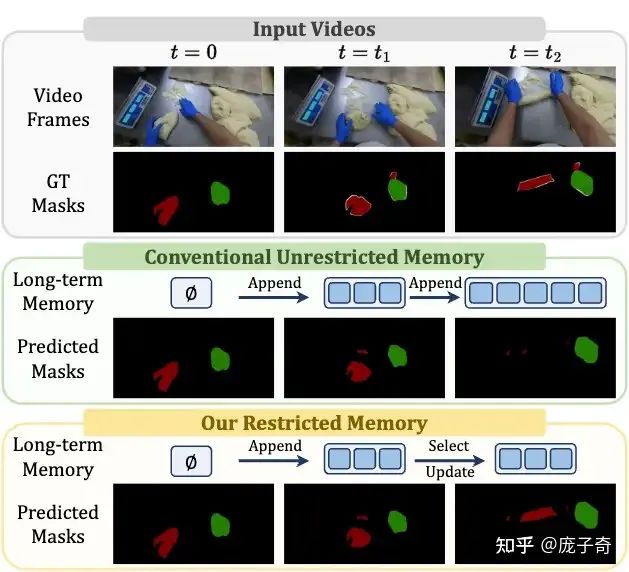
除了在VOS Accuracy上的显著提升,我们发现精简Memory Bank本身就自带了如下优势:
Efficiency: Memory Bank里面存储的帧少了,当然跑得快了占的GPU也少了。
Training/Test Consistency: 因为我们限制了memory bank的大小,所以它在长视频上做inference的时候差别跟training time见到的短Clip差别变小了。为了展示这一点的重要性,我们是第一次在Video Object Segmentation上能够使用Temporal Position Embedding的方法。(这一点有点绕,细节请参考论文)
2. 为什么精简的Memory Bank有好处,讲点儿实在的?
简而言之一句话 -- 【信息存得太多反而带来了太多冗余,太多冗余让Model反而困惑了】。我们是如何验证这一点的呢,请看我们的Memory Deciphering Analysis。
我们的实验设置非常简单——在VOS模型预测当前帧的物体Mask之外,我们让它从Memory Bank里存储的Features去预测最开始的第一帧的物体Mask是什么样子的。因为第一帧的信息其实已经被存储在了Memory Bank内,所以Theoretically对第一帧的记忆应该是接近完美的,即使Memory Bank在不断地增长、有越来越多的信息。可实际上呢 -- 用不断增长的Memory Bank去记忆的第一帧Mask一直在显著变差。这其实就已经印证了“多余信息的坏处。”
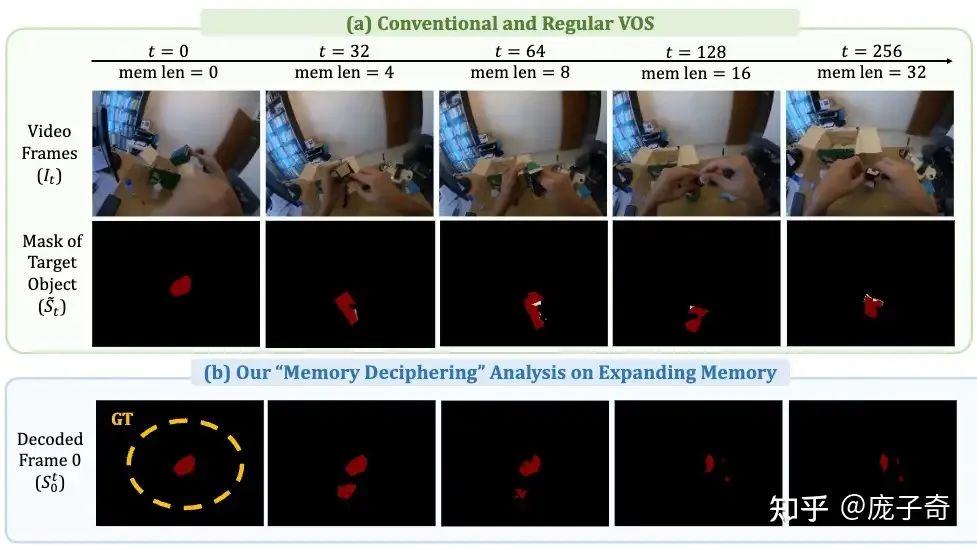
如果我们挖得更深——冗余信息究竟是如何危害视频理解的呢?
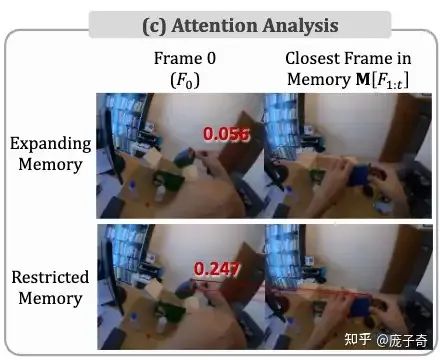
冗余信息使得正确物体之间的Attention Score显著下降了,而Restricted Memory Bank使得正确物体之间的关联维持在相对较高的Attention Score上——我们内部称这一发现为“【Needle in a Haystack (视频理解版)】。”
事实上,我们Restricted Memory Bank的发现还真的跟LLM这边的研究有点联系,例如去年比较火的StreamingLLM和其它加速/处理长Context相关的工作。
3. 有哪些构建精简Memory Bank的关键点,说来听听?
这部分对应于我们论文的方法和实验分析部分,其实整体的framework如下,非常简单。其中,有三个关键点:
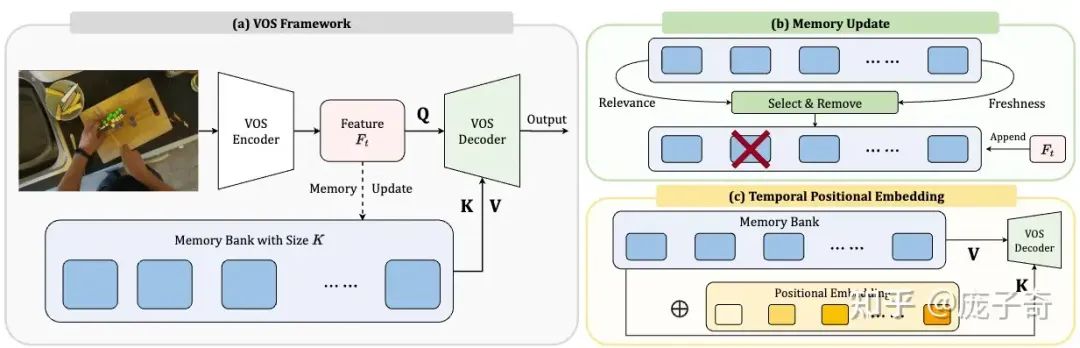
3.1 Memory Bank的大小
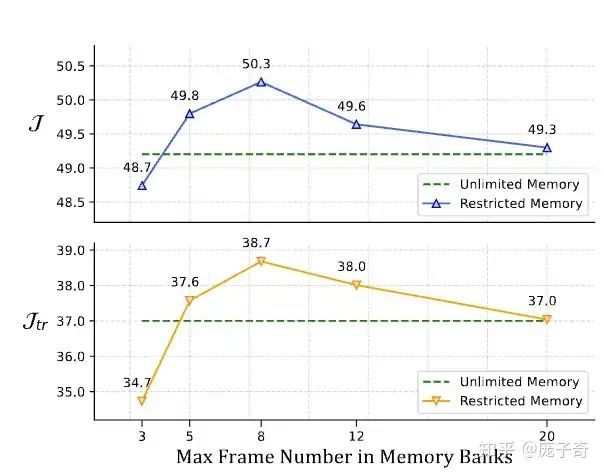
之前我们一直在说Memory Bank太大的问题,其实Memory Bank太小了也不行,毕竟至少需要把有用的信息都装下。根据如下的实验,我们可以发现,对于online的VOS,一个Sweet Spot就是在Memory Bank包含8帧左右。
3.2 帧的筛选
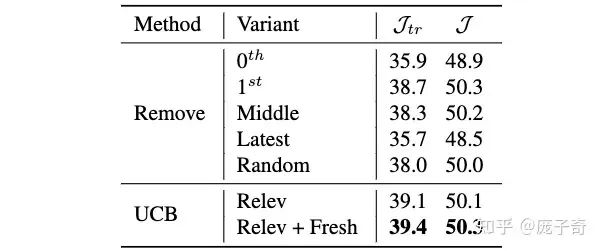
既然我们希望扔掉冗余信息,那么它本质上就是如何选择有效信息?我们认为两个原则是选择有效信息的关键:
相关性(Relevance):Memory Bank的帧究竟有多大帮助?我们采用的计算方式是看Memory Bank中的帧究竟贡献了多少Attention Score。
新鲜度(Freshness):为了避免很老的某些帧尸位素餐,我们会惩罚长期占据Memory Bank的帧。
为了平衡这两种指标,我们受到Multi-arm Bandit的启发并采用了UCB算法。相对于简单的Heuristics (Remove),我们的UCB算法可以有显著提升。
3.3 Temporal Positional Embedding
在这次研究VOS的过程中,我们非常惊讶地发现现有的算法都没有对Memory Bank中的Feature加时序上的Positional Embedding。这就相当于视频中物体出现的先后顺序甚至都没有被考虑到。事实上,这和之前的算法没有考虑到Memory Bank Size的变化紧密相关:
在Training的时候,GPU Memory有限,往往大家最多只能训练到Memory Bank里面有<5帧的情形;
在Inference的时候,算法是Streaming的,所以Memory Bank有时可以积累数十甚至上百帧的Features。
这样严重的training/inference mismatch带来的就是无法有效地训练Temporal Positional Embedding。
然而,我们的Restricted Memory Bank带来了全新的机会:因为精简Memory Bank限制了Memory Bank的无限增长,所以有效地减少了training/inference的mismatch,也就使得我们可以真正地把temporal positional embedding在视频理解上做work,可以去处理时序的信息。
4. 你们的精简Memory Bank听起来简单有效,为什么之前的人没发现它的作用?
简而言之一句话:【之前的数据集太简单了】。我们的Restricted Memory Bank能够起作用,全是在困难的场景下——(1) 长视频理解,顾名思义,视频有更多的帧(the Long Videos Dataset & LVOS) (2) Egocentric State Changes,物体会经历大量的形变、遮挡、移出视频等等 (VOST)。在简单的视频中,例如大家经常使用的DAVIS,Restricted Memory Bank就只剩下提升Efficiency的效果了。所以说,我们的发现其实要感谢最近新出现的这些更加Challenging的视频数据集。
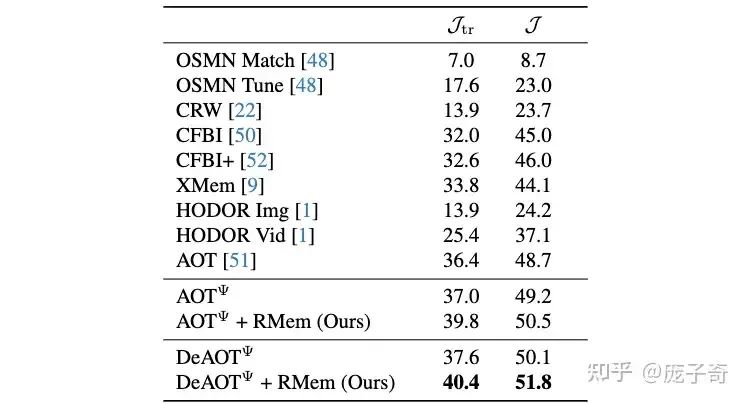
关于难的数据长什么样子,请看如下例子:

当然,也请查看我们的Video Demo:
5. 一些最后的讨论——知道如何筛选信息又何尝不是一种信息?
5.1 总结
我们的CVPR论文提出了一种非常简单而且有效的提升视频理解的方法:精简Memory Bank (Restricted Memory Bank)。它的成功证明了在处理长Context或者困难任务的时候,合理地筛选信息、扔掉冗余不仅仅可以提升Efficiency,而且可以显著提升Perception的准确性。
在这个项目中,我们受制于资源,无法在长视频+LLM等多模态任务上进行实验,非常遗憾。不过我们希望上述的Insight可以启发或者直接帮助到视频理解或者相关领域的研究。事实上,在最近的一些结合Video Understanding + LLM的工作中,例如“Streaming Long Video Understanding with Large Language Models”,已经开始应用Restricted Memory相似Flavor的方法。
5.2 更深的理解和原则
我PhD期间的研究主要是计算机视觉,其中最令我着迷的问题就是Representation Learning:相对于容易做Tokenization的语言信息,视觉信息包含了大量的冗余,那么该如何从这样的视觉信息中找到真正对当前任务有效的信息呢?在探索这个问题的路径上,我们探索了许多领域,最终发现能够因地制宜地(Actively)压缩(Compress)信息是Encoding过程的关键,而在压缩的过程中,其实我们也在创造有用的信息。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看














 2782
2782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









