






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

Transformer 是现代深度学习的基石。传统上,Transformer 依赖多层感知器 (MLP) 层来混合通道之间的信息。
前段时间,来自 MIT 等机构的研究者提出了一种非常有潜力的替代方法 ——KAN。该方法在准确性和可解释性方面表现优于 MLP。而且,它能以非常少的参数量胜过以更大参数量运行的 MLP。
KAN的发布,引起了AI社区大量的关注与讨论,同时也伴随很大的争议。
而此类研究,又有了新的进展。
最近,来自新加坡国立大学的研究者提出了 Kolmogorov–Arnold Transformer(KAT),用 Kolmogorov-Arnold Network(KAN)层取代 MLP 层,以增强模型的表达能力和性能。

论文标题:Kolmogorov–Arnold Transformer
论文地址:https://arxiv.org/pdf/2409.10594
项目地址:https://github.com/Adamdad/kat
KAN 原论文第一作者 Ziming Liu 也转发点赞了这项新研究。

将 KAN 集成到 Transformer 中并不是一件容易的事,尤其是在扩展时。具体来说,该研究确定了三个关键挑战:
(C1) 基函数。KAN 中使用的标准 B 样条(B-spline)函数并未针对现代硬件上的并行计算进行优化,导致推理速度较慢。
(C2) 参数和计算效率低下。KAN 需要每个输入输出对都有特定的函数,这使得计算量非常大。
(C3) 权重初始化。由于具有可学习的激活函数,KAN 中的权重初始化特别具有挑战性,这对于实现深度神经网络的收敛至关重要。
为了克服上述挑战,研究团队提出了三个关键解决方案:
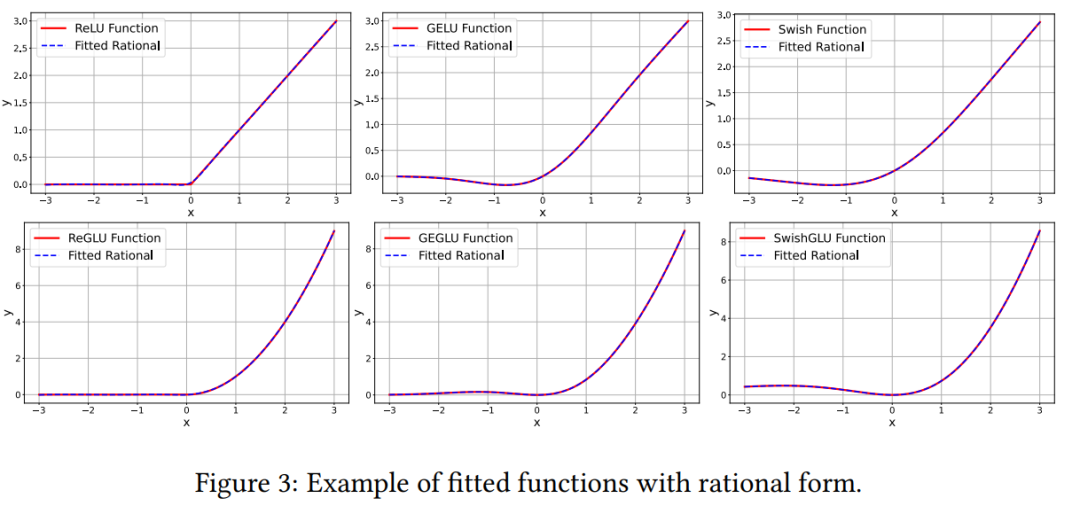
(S1) 有理基础。该研究用有理函数替换 B 样条函数,以提高与现代 GPU 的兼容性。通过在 CUDA 中实现这一点,该研究实现了更快的计算。
(S2) Group KAN。通过一组神经元共享激活权重,以在不影响性能的情况下减少计算负载。
(S3) Variance-preserving 初始化。该研究仔细初始化激活权重,以确保跨层保持激活方差。
结合解决方案 S1-S3,该研究提出了一种新的 KAN 变体,称为 Group-Rational KAN (GR-KAN),以取代 Transformer 中的 MLP。
实验结果表明:GR-KAN 计算效率高、易于实现,并且可以无缝集成到视觉 transformer(ViT)中,取代 MLP 层以实现卓越的性能。此外,该研究的设计允许 KAT 从 ViT 模型加载预训练权重并继续训练以获得更好的结果。
该研究在一系列视觉任务中实证验证了 KAT,包括图像识别、目标检测和语义分割。结果表明,KAT 的性能优于传统的基于 MLP 的 transformer,在计算量相当的情况下实现了增强的性能。

如图 1 所示,KAT-B 在 ImageNet-1K 上实现了 82.3% 的准确率,超过相同大小的 ViT 模型 3.1%。当使用 ViT 的预训练权重进行初始化时,准确率进一步提高到 82.7%。
不过,也有网友质疑道:「自从有论文比较了具有相同参数大小的 MLP 模型和 KAN 模型的性能后,我就对 KAN 持怀疑态度。可解释性似乎是唯一得到巨大提升的东西。」

对此,论文作者回应道:「的确,原始 KAN 在可解释性上做得很好,但不保证性能和效率。我们所做的就是修复这些 bug 并进行扩展。」

还有网友表示,这篇论文和其他人的想法一样,就是用 KAN 取代了 MLP,并质疑为什么作者在尝试一些已经很成熟和类似的东西,难道是在炒作 KAN?对此, 论文作者 Xingyi Yang 解释道,事实确实如此,但不是炒作,根据实验,简单地进行这种替换是行不通的,他们在努力将这个简单的想法变成可能的事情。
Kolmogorov–Arnold Transformer (KAT)
作者表示,标准的 KAN 面临三大挑战,限制了其在大型深度神经网络中的应用。
它们分别是基函数的选择、冗余参数及其计算、初始化问题。这些设计选择使得原始版本的 KAN 是资源密集型的,难以应用于大规模模型。
本文对这些缺陷设计加以改进,以更好地适应现代 Transformer,从而允许用 KAN 替换 MLP 层。
KAT 整体架构
正如其名称所暗示的那样,KAT 用 KAN 层取代了视觉 transformer 中的 MLP 层。
具体来说,对于 2D 图像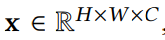 ,作者首先将其平面化成 1D 序列,在此基础上应用 patch 嵌入和位置编码,然后通过一系列 KAT 层进行传递。对于
,作者首先将其平面化成 1D 序列,在此基础上应用 patch 嵌入和位置编码,然后通过一系列 KAT 层进行传递。对于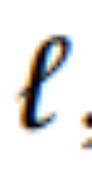 层,可以执行如下操作:
层,可以执行如下操作:
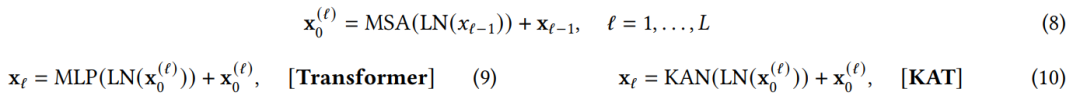
其中,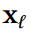 表示
表示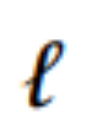 层的输出特征序列。
层的输出特征序列。
如图所示,作者用两层 KAN 替换两层 MLP,同时保持注意力层不变。然而,简单的替换不足以在大模型中实现可扩展性。
最重要的是,在这里,作者引入了一种特殊的 Group-Rational KAN。作者使用有理函数作为 KAN 的基函数,并在一组边之间共享参数。此外,作者还指定了权重初始化方案以确保稳定的训练。这些改进使得 KAT 更具可扩展性并提高了性能。
有理基函数
作者使用有理函数作为 KAN 层的基函数,而不是 B 样条函数,即每个边上的函数 𝜙 (𝑥) 参数化为 𝑚、𝑛 阶多项式 𝑃 (𝑥)、𝑄(𝑥) 上的有理数。
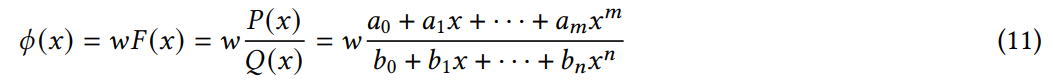
标准形式转化为:

至于为什么采用有理函数,作者表示从效率角度来看,多项式求值涉及简单的运算,非常适合并行计算。这使得有理函数对于大规模模型具有计算效率。
其次,从理论角度来看,有理函数可以比多项式更高效、更准确地逼近更广泛的函数。由于 B 样条本质上是局部多项式的和,因此有理函数在复杂行为建模方面比 B 样条具有理论优势。
第三,从实践角度来看,有理激活函数已经成功用作神经网络中的激活函数。
Group KAN
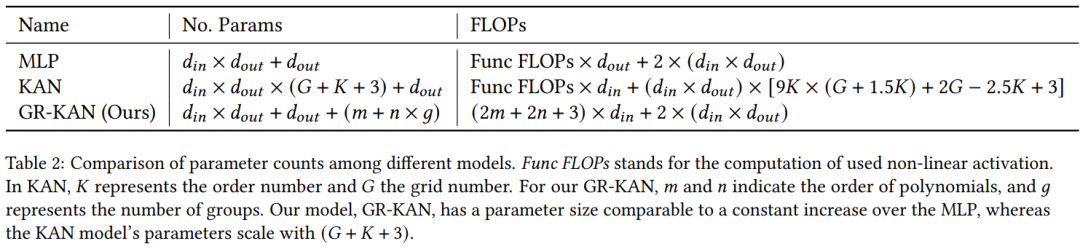
作者表示,他们不必为每个输入 - 输出对学习一个独特的基函数,而是可以在一组边内共享它们的参数。这减少了参数数量和计算量。这种参数共享和分组计算的方式一直是神经网络设计中的关键技术
图 2 说明了原始 KAN、Group KAN 和标准 MLP 之间的区别。Group KAN 通过在一组边之间共享这些函数来减少参数数量。

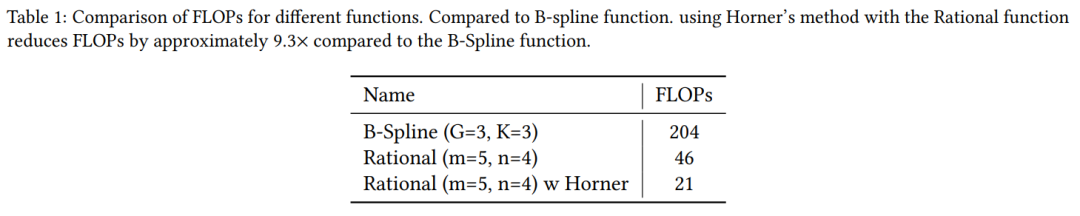
除了节省参数数量外,这种分组还减少了计算需求。不同模型间参数数量和计算量的对比如下所示:
Variance-preserving 初始化
作者旨在初始化 Group-Rational KAN 中的 𝑎_𝑚、𝑏_𝑛 和 𝑤 的值,其核心是防止整个层中的激活参数呈量级增长或减少,从而保持稳定性。
实验
实验中,作者修改了原始 ViT 架构,用 GR-KAN 层替换其 MLP 层。
图像识别
实验结果表明,KAT 模型在 IN-1k( ImageNet-1K ) 数据集上的表现始终优于其他模型。首先,GR-KAN 在 Transformer 架构中的表现优于传统的基于 MLP 的混合器的性能。例如,KAT-S 模型的准确率达到 81.2%,比 DeiT-S 模型高出 2.4%。
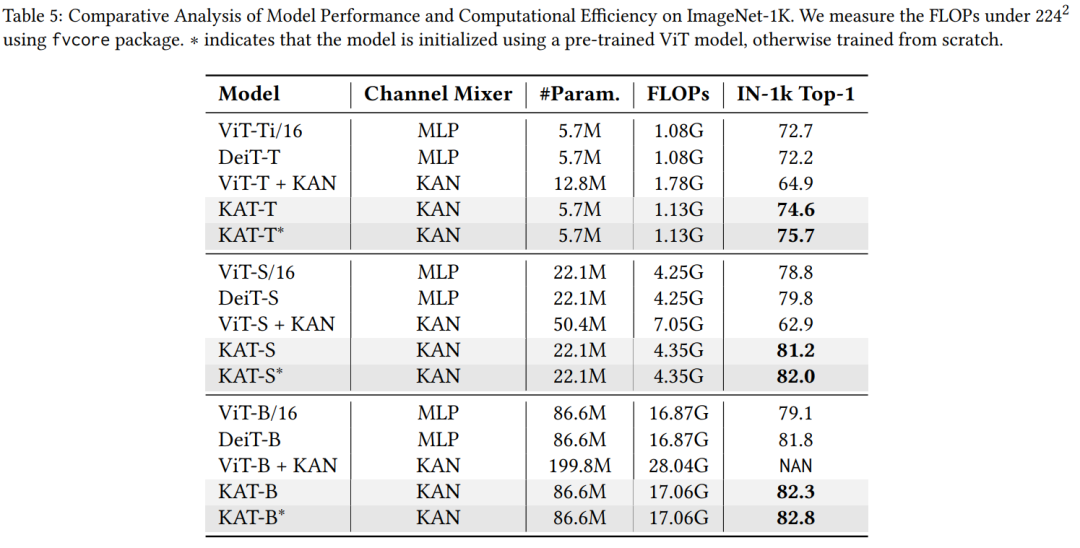
其次,原始 KAN 层面临可扩展性问题。ViT-T/S + KAN 的准确率仅为 63% 左右,即使计算成本高得多。ViT-L + KAN 无法收敛,导致 NAN 错误。本文解决了这些扩展挑战,从而使 KAT 模型能够成功扩展。
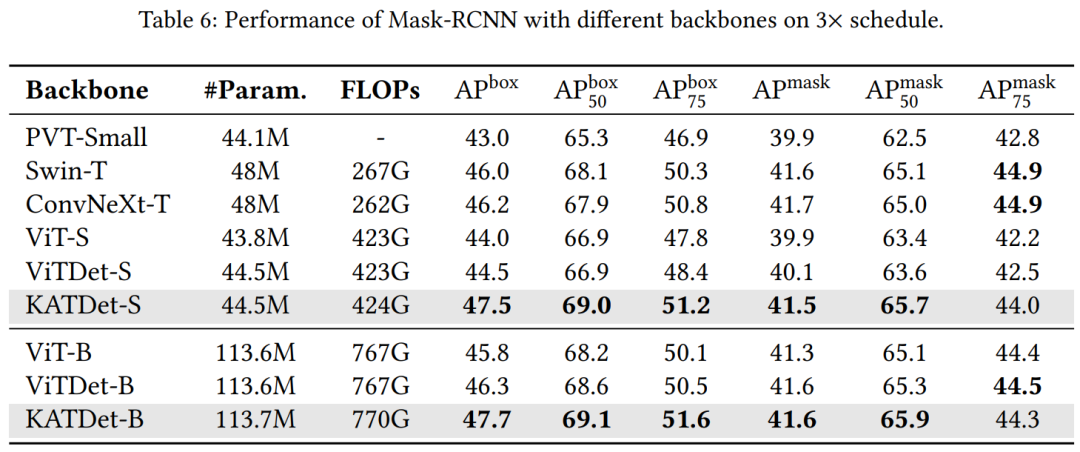
目标检测和实例分割
表 6 比较了不同骨干模型的性能。KAT 的表现始终优于其他模型,尤其是在物体检测方面,与 ViTDet 相比,其在 S 规模的模型上实现了 3.0 AP^box 增益,在 L 规模的模型上实现了 1.4 AP^box 增益。这种改进在较小的模型中最为明显,计算成本仅增加了 1 GFLOP。这表明 KAT 以最小的开销提供了更好的准确率。
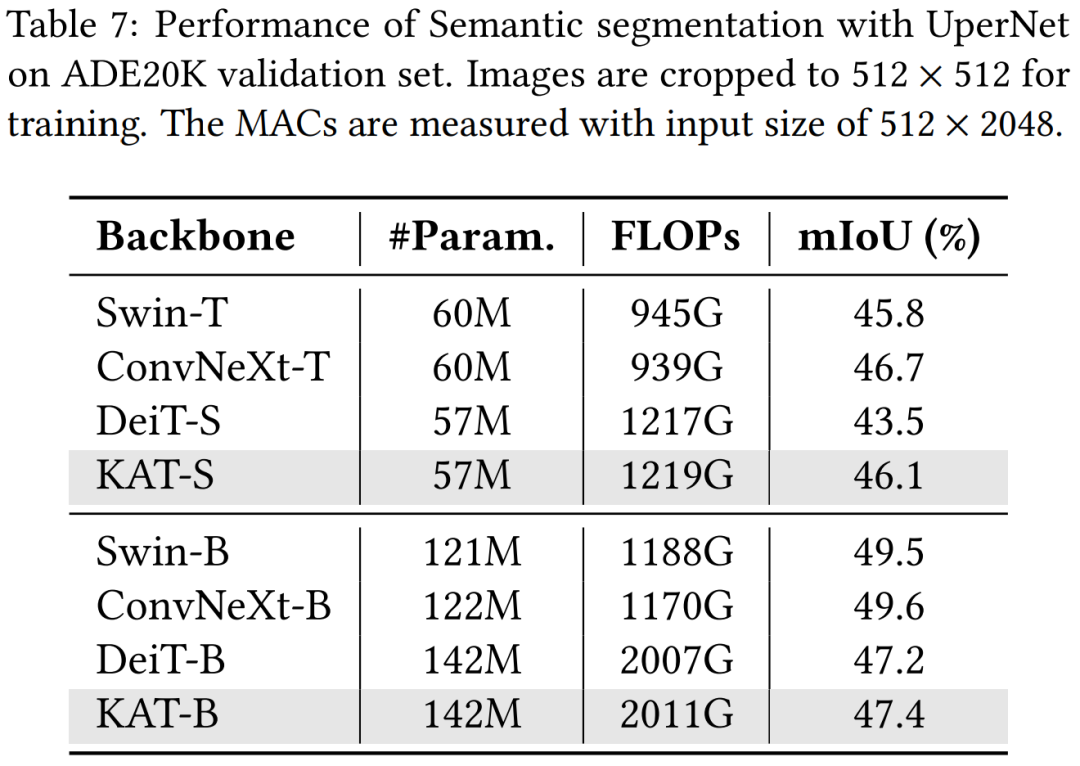
语义分割
表 7 总结了分割结果。总体而言,KAT 比基于 ViT 的普通架构表现出了竞争优势,比 DeiT-S 提高了 2.4%,比 DeiT-B 提高了 0.2%。这种性能提升伴随着计算成本的轻微增加,反映在更高的 FLOP 上。与检测结果类似,KAT 在较小的模型中显示出更显著的收益。然而,与具有分层架构的模型(如 ConvNeXt)相比,它仍然有所不足,这些模型受益于更高效的架构设计。
作者介绍
Xingyi Yang 现在是新加坡国立大学(NUS)三年级博士生,导师是 Xinchao Wang 教授,这篇论文就是师徒两人合作完成的。
Xingyi Yang 于 2021 年在加州大学圣地亚哥分校获得硕士学位,并于 2019 年在东南大学获得计算机科学学士学位。
Xinchao Wang 目前是新加坡国立大学电气与计算机工程系(ECE)的助理教授,研究兴趣包括人工智能、计算机视觉、机器学习、医学图像分析和多媒体。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









