how the reasoning processes over implicit and explicit knowledge should be integrated(推理过程应该如何结合显式和隐式的知识?)
2. 解决方法:
a - Knowledge Augmented Transformer (KAT)(同时结合了显式和隐式知识,其中显式知识的结合提高了模型的可解释性)
1 Introduction
1. 应用场合:
许多自动化引擎需要模型seamlessly integrate implicit (i.e., commonsense) and explicit knowledge (e.g., Wikidata)——显式知识即维基百科知识,隐式知识即常识性知识
2. 比较符合的数据集:
OK-VQA
3. 核心问题:
A key challenge here is to accurately link image content to abstract external knowledge(准确地链接图像内容到抽象的外部知识)
4. 现有方法以及不足:
(1)第一类:
first retrieve external knowledge from external knowledge resources(首先从外部知识源中检索外部知识);
不足:
① First, explicit knowledge retrieved using keywords from questions or image tags may be too generic, which leads noise or irrelevant knowledge during knowledge reasoning(使用来自于问题和图像中的关键词来检索外部知识可能过于通用,导致产生了大量噪声或者不相关的知识,影响了知识推理过程)
② existing work mainly focuses on explicit knowledge(现有工作主要集中于外部知识)
5. 主要贡献:
(1)Knowledge extraction(知识提取):① for implicit knowledge, we design new prompts to extract both tentative answers and supporting evidence from a frozen GPT-3 model(对于隐式知识,设计了新的prompt,从参数冻结的GPT-3模型中提取试探性的答案以及支撑证据);② design a contrastive learning-based explicit knowledge retriever using the CLIP model(对于显式知识,设计基于对比学习的显式知识检索器,即CLIP,希望所有检索到的知识都是以视觉对齐的目标为中心)
(2)Reasoning in an encoder-decoder transformer(编解码推理):
(3)将外部知识转化为neural-symbolic inference based knowledge(神经符号推理)。
Open-Domain Question Answering (ODQA)
3 Method
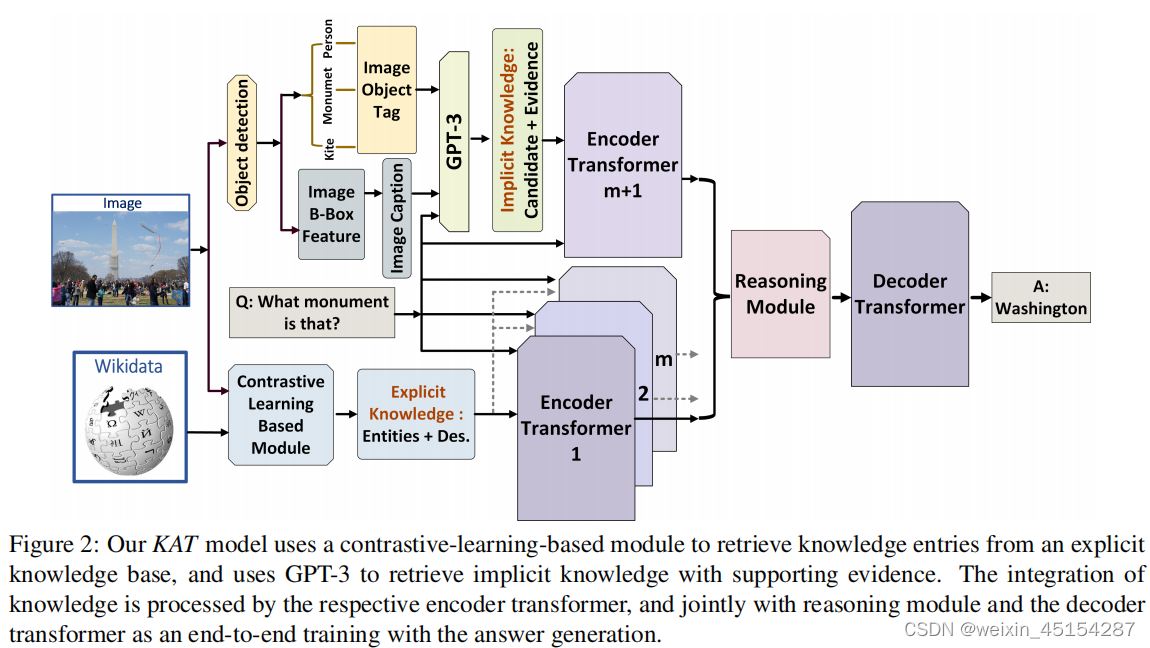
3.1 Overview
3.2 Explicit Knowledge Retrieval
3.2.1 Explicit Knowledge Extraction
传统方法:图像:目标检测器去提取特征,image tags can be generic and have a limited vocabulary size, leading noise or irrelevant knowledge(图像提示是通用的,有有限的单词数量,导致带噪声的或者不相关的知识产生);
本文方法:contrastive-learning based model to associate image regions with external knowledge bases(对比学习,将图像区域和外部知识联系在一起),有八类知识类型,每一个都是实体+对应文本描述
3.2.2 Knowledge Base Construction
知识源:维基百科
3.3 Implicit Knowledge Retrieval
leverage GPT-3 as an implicit language knowledge base and treat VQA as an open-ended text generation task(利用GPT-3作为隐式知识库,并且将VQA任务视为文本生成任务)
3.4 KAT Model
Encoder:
Reasoning Module:
Decoder:
4 Experiment
4.1 Dataset
OK-VQA:包含14
, 031 images和14
, 055 questions covering a variety of knowledge categories(包含各种知识类型)
KAT: A Knowledge Augmented Transformer for Vision-and-Language——论文
(1)Knowledge extraction(知识提取):① for implicit knowledge, we design new prompts to extract both tentative answers and supporting evidence from a frozen GPT-3 model(对于隐式知识,设计了新的prompt,从参数冻结的GPT-3模型中提取试探性的答案以及支撑证据);, Wikidata)——显式知识即维基百科知识,隐式知识即常识性知识。








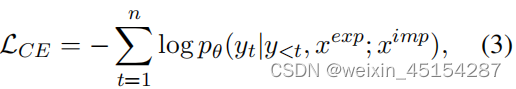















 4860
4860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









