






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

编辑:CVer 微信公众号| 作者:Xiaobiao Du

https://xiaobiaodu.github.io/mvgs-project/
论文:https://arxiv.org/pdf/2410.02103
代码: https://github.com/xiaobiaodu/MVGS

摘要
最近在体积渲染领域开展的工作,例如 NeRF 和 3D Gaussian Splatting(3DGS)借助学习到的隐式神经辐射场或 3D Gaussians,大大提高了渲染质量和效率。Vanilla 3DGS 及其变体在显式表示的基础上进行渲染,通过在训练过程中采用 NeRF 的每次迭代单视角监督来优化参数模型,从而提高实时效率。因此,某些视图被过度拟合,导致新视图合成中出现不令人满意的外观和不精确的三维几何图形。为了解决上述问题,我们提出了一种新的 3DGS 优化方法,其中包含四个关键的新贡献:
我们将传统的单视角训练模式转变为多视角训练策略。通过我们提出的多视角约束,可以进一步优化三维高斯属性,而不会过度拟合某些训练视角。作为一种通用解决方案,我们提高了各种场景和不同高斯变体的整体准确性。
受多视图训练带来的好处和启发,我们进一步提出了cross-intrinsic guidance方案,从而实现了从粗到细的不同分辨率训练程序。
在多视角约束训练的基础上,我们进一步提出了cross-ray densification策略,从选定的视角出发,在射线交叉区域致密化更多的高斯核。
通过进一步研究致密化策略,我们发现当某些视图显著不同时,致密化的效果应该得到加强。作为解决方案,我们提出了一种新颖的multi-view augmented densification策略,即鼓励三维高斯相应地致密化到足够的数量,从而提高重建精度。
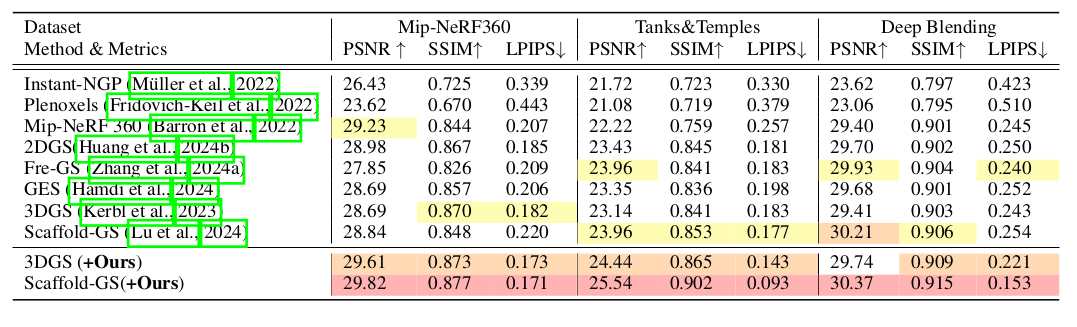
我们进行了大量实验,证明我们提出的方法能够在各种任务中将基于高斯的显式表示方法的新视图合成的 PSNR 提高约 1 dB。
介绍
对于无界场景或单个物体的写实渲染在工业和学术领域都具有重要价值,如多媒体生成、虚拟现实和自动驾驶等。传统的基于几何图元的表示方法(如网格和点云)通过高效的光栅化技术实现了实时渲染。尽管这种渲染机制具有较高的效率,但在呈现精细、准确的外观时,仍然存在模糊伪影和不连续性的问题。
相反,隐式表示和神经辐射场(NeRF)利用多层感知机(MLP)提高了渲染高保真几何结构的能力,保留了更多细节。然而,即使采用加速算法,推理效率仍然有限。
近年来,基于3D高斯的显式表示(如高斯点阵)凭借定制的光栅化技术,在渲染质量和效率上都达到了最新水平。这种训练策略通过每次迭代使用单个相机视角的样本进行训练,在NeRF中常见。然而,由于其显式特性,我们观察到这种单视角训练模式容易导致过拟合,不能精确呈现场景中的所有细节。
本文提出了一种通用优化方法MVGS,增强了基于高斯的显式方法的精度。我们的主要贡献是改变传统的单视角训练方式,提出多视角约束学习。在训练过程中,3D高斯通过多个视角的结构和外观联合学习,避免了过拟合问题。此外,我们提出了从低分辨率到高分辨率的cross-intrinsic guidance,低分辨率训练提供了多视角信息,有助于在高分辨率训练中雕刻更精细的细节。
为了提高多视角学习的效果,我们还提出了一种Cross-ray Densification策略,利用2D损失图引导3D高斯在重叠区域进行密集化,从而提高多视角下的重建性能。此外,当视角差异显著时,我们提出了多视角增强的密集化策略,鼓励3D高斯适应多视角信息,改善表现。
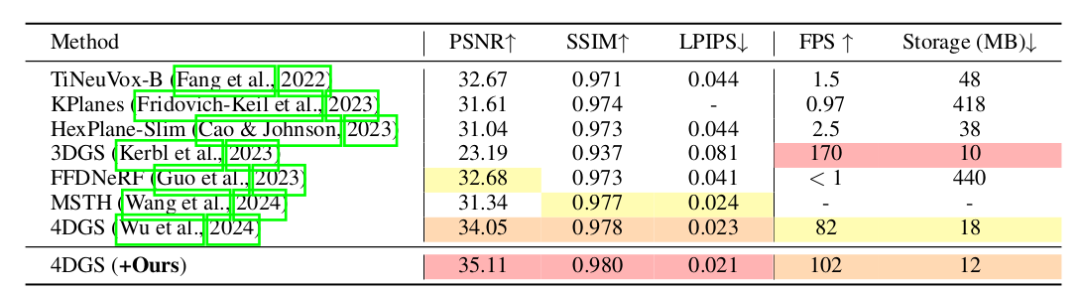
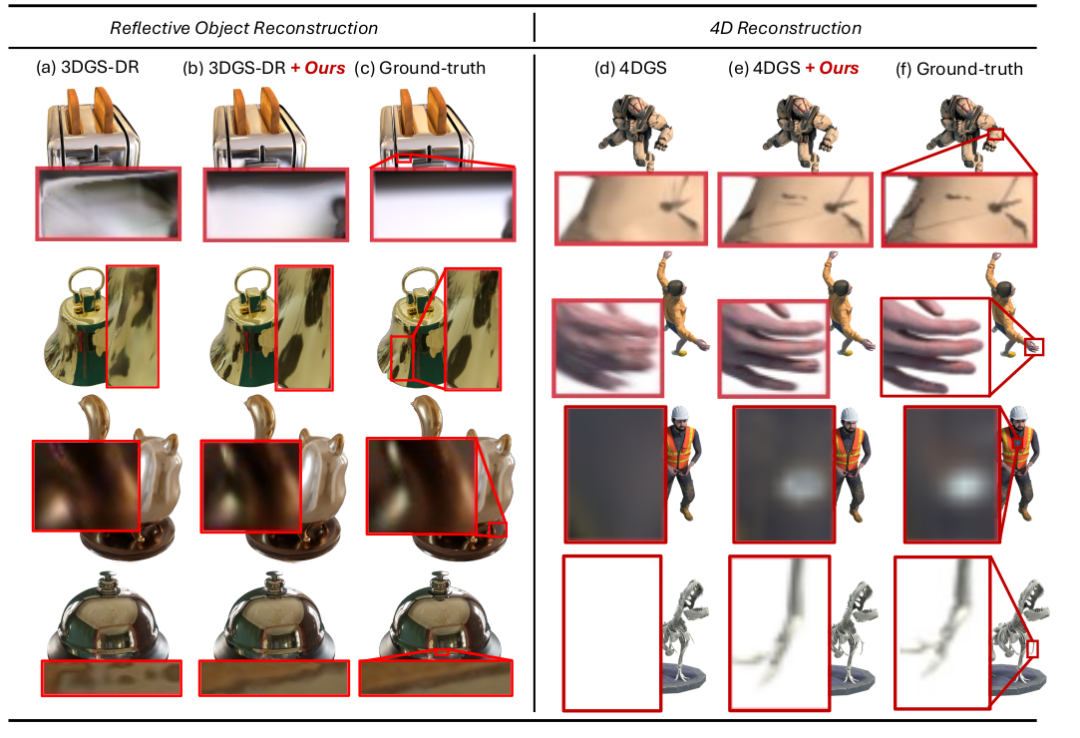
大量实验表明,我们的方法在各种任务上提升了基于高斯方法的新视角合成精度,包括一般物体重建、4D重建和大规模场景重建。实验结果显示,随着每轮优化中视角数量的增加,精度得到显著提升。
方法
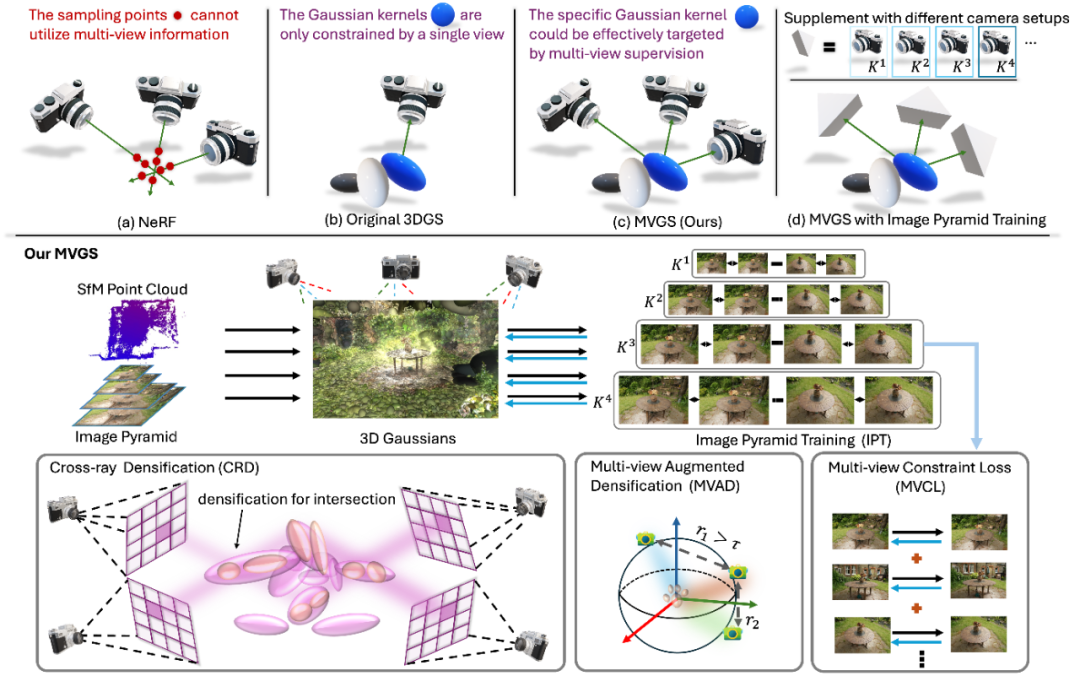
Gaussian Splatting 最近被提出用于实时的新视角合成和高保真 3D 几何重建。与 NeRF 和 NeuS 中采用的隐式表示(如 NeRF 中的密度场和 NeuS 中的 SDF)不同,Gaussian Splatting 利用了一组各自具有位置、颜色、协方差和不透明度的各向异性 3D 高斯函数来参数化场景。这种显式表示与之前的 NeRF 和 NeuS 方法相比,显著提高了训练和推理效率。
在渲染过程中,Gaussian Splatting 采用了基于点的体积渲染技术,类似于 NeRF。如图(a)所示,我们指出 NeRF 由于其点采样策略和隐式表示,无法在一个训练迭代中接收多视角监督。图像中像素 的视角依赖辐射 是通过混合沿着射线 的一组 3D 高斯来计算的。NeRF 使用采样器分配的点在辐射场中进行近似混合,而 3DGS 则通过栅格化与沿射线 的 个参数化核 进行精确混合。
假设第 个高斯 的属性分别由颜色 、不透明度 和协方差 描述,渲染的像素辐射 表示为
其中颜色 由透光率 加权。这里 表示高斯核的位置 与查询像素 之间的距离。 表示 3D 高斯的数量。
给定 对地真图像 及其对应的相机外参 和内参 ,即 ,3DGS 的目标是重建由多视角立体数据描述的 3D 模型。在训练策略方面,3DGS 遵循 NeRF 的惯例,即通过每次迭代的单视角监督来优化参数模型。关于训练,3DGS 通常通过每次迭代中的单视角信息监督进行优化,其中每次迭代中的监督是随机选择的 。因此,原始 3DGS 的损失函数可以相应地表示为:
其中, 和 分别表示平均绝对误差和 D-SSIM 损失。 表示部分 会在单视角监督模式下受到较大的梯度影响。实际上,超参数 用于控制这两个损失项之间的比例。
Multi-view Regulated Learning
考虑到隐式表示(例如 NeRF)依赖于预训练的采样器来近似最具置信度的混合点,多视角监督并不能保证相较于单视角训练的提升,特别是在采样器未经过充分训练时。显式定义的高斯核则不依赖于采样器进行分配,因此我们提出的多视角训练策略是可行的,其中大部分混合核 可以通过多视角加权梯度进行反向传播,从而克服某些视角的过拟合问题。
与原始的单视角迭代训练不同,我们提出了一种多视角约束的训练方法,以多视角监督的方式优化 3D 高斯。具体来说,在一次迭代中,我们采样 对监督图像和相机参数。因此,我们提出的在单次迭代中整合梯度的多视角约束学习可以表示为:
其中 表示在多视角训练中,每个视角的部分 3D 高斯 将受到大的梯度影响。与原始 3DGS 损失的唯一不同之处在于,我们提出的方法为优化一组 3D 高斯 提供了多视角约束。
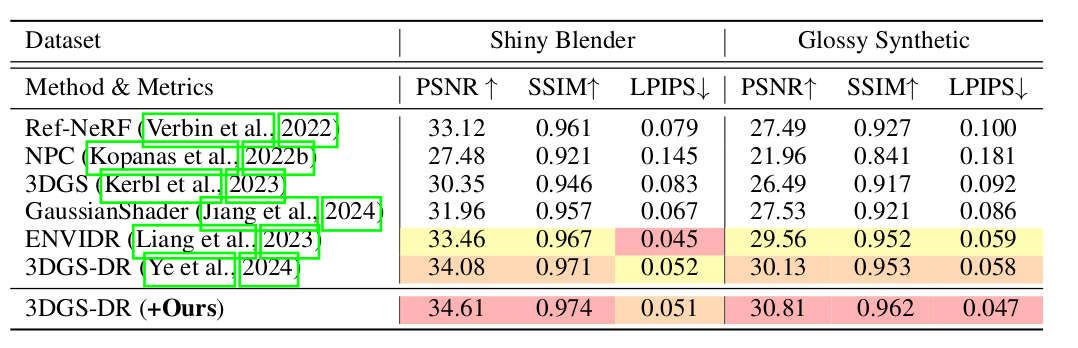
通过这种方式,优化每个高斯核 可能会受到多视角信息的调节,从而克服对某些视角的过拟合问题。此外,多视角约束使 3D 高斯能够学习并推导出视角依赖信息,如反射,因此我们的方法在反射场景的新视角合成中表现良好。
Cross-intrinsic Guidance
如方法图底部所示,受图像金字塔的启发,我们提出了一种粗到细的训练方案,使用不同的相机设置(即内参 ),通过简单地补充更多的光栅化平面来实现。具体来说,通过重新配置 中的焦距 和主点 ,可以构建一个具有降采样因子 的四层图像金字塔,如图(d) 所示经验上,设置 为 8 已足够容纳足够的训练图像进行多视角训练, 等于 1 意味着未应用降采样操作。对于每一层,我们有匹配的多视角设置 。特别地,较大的降采样因子允许容纳更多视角,从而提供更强的多视角约束。
在最初的三个训练阶段,我们只在每个阶段运行几千次迭代,而不完全训练模型。由于目标图像经过降采样,模型在这些早期阶段无法捕捉到细节。因此,我们将前三个训练阶段视为粗略训练。在粗略训练期间,整合更多的多视角信息对整个 3D 高斯施加更强的约束。在这种情况下,丰富的多视角信息为整个 3DGS 提供了全面的监督,并促进粗略纹理和结构的快速拟合。
一旦粗略训练完成,细致训练就会开始。由于先前的粗略训练阶段提供了 3DGS 的粗略结构,细致训练阶段只需细化和雕刻每个 3D 高斯的细节。特别是,粗略训练阶段提供了大量的多视角约束,并将所学习的多视角约束传递到接下来的细致训练中。该方案有效地增强了多视角约束,并进一步提高了新视角合成的性能。
Cross-ray Densification
由于体积渲染的特性以及3D高斯(3DGS)的显式表示,某些区域的3D高斯在渲染时对不同视角有显著影响。例如,当相机从不同姿态拍摄中心时,中央的3D高斯在渲染中至关重要。然而,找到这些区域并不简单,尤其是在三维空间中。我们提出了一种交叉射线密集化策略,从二维空间开始,然后自适应地在三维空间中搜索。具体而言,我们首先计算多个视角的损失图,然后使用大小为的滑动窗口定位包含最大平均损失值的区域。随后,我们从这些区域的顶点发射射线,每个窗口发射四条射线。接着,我们计算不同视角射线之间的交点。由于每个视角发射四条射线,这些交点可以形成多个立方体。这些立方体是包含显著3D高斯的重叠区域,在为多个视角进行渲染时发挥着重要作用。因此,我们在这些重叠区域中进一步密集化更多的3D高斯,以促进多视角监督的训练。该策略依赖于准确搜索包含对多个视角具有高度重要性的3D高斯的重叠区域。首先,我们选择损失引导,因为它突出了每个视角需要改进的低质量区域。其次,射线投射技术使我们能够定位包含一组对这些视角贡献显著的3D高斯的三维区域。基于准确的位置,这些区域中的3D高斯被视为多视角联合优化的关键。因此,我们在这些区域内密集化这些3D高斯,以提高这些视角的重建性能。
Multi-view Augmented Densification
为了实现快速收敛、避免局部最小值并学习细粒度的高斯核,同时在不同视角之间的差异显著时,我们提出了一种多视角增强密集化策略。具体而言,我们的策略基于原始3D高斯(3DGS)的密集化策略,并使用预定义阈值β来确定哪些3D高斯应进行密集化。如图所示,我们首先识别训练视角是否存在显著差异。我们不直接使用原始相机的平移,而是将采样视角的相机平移标准化到单位球体。这种方法使我们的策略适应各种场景。然后,计算每个相机与其他相机之间的相对平移距离 ,其中距离的数量n为M^2 - M,假设我们有M个训练视角。在我们的多视角增强密集化中,我们有一个自适应标准可以表示为:
其中H(·)是Heaviside函数,当输入大于或等于0时返回1。τ是预定义的超参数。通过这种方式,当每个视角之间的差异变大时,3D高斯的密集化程度也会增强。因此,我们提出的多视角增强密集化策略使得3D高斯能够更好地适应每个视角,并捕捉更细致的细节。
实验效果

何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba和3DGS交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、3DGS微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、3DGS+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









