






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
快扫码领取!CVer学术星球春节优惠券来了!感谢大家的支持,现在赠送50元新用户优惠券(左图领取),7折+20元老用户续费券(右图领取),大家快扫码加入!蛇年坚持分享更新更优质的AI工作,全年不停更!最强助力你的科研和工作!

转载自:机器之心
本文一作孟维康是哈尔滨工业大学(深圳)与鹏城实验室联合培养的博士生,本科毕业于哈尔滨工业大学,主要研究方向是大规模基础模型的高效训练和推理算法研究。
通讯作者张正教授,哈尔滨工业大学(深圳)的长聘教授及博士生导师,教育部青年长江学者,广东特支计划青年珠江学者,深圳市优青。长期从事高效能多模态机器学习的研究,专注于高效与可信多模态大模型。
课题组:Big Media Intelligence (BMI) 欢迎校内外优秀学者的加入以及来访交流。
课题组主页:https://cszhengzhang.cn/BMI/

论文标题:PolaFormer: Polarity-aware Linear Attention for Vision Transformers
论文链接:https://arxiv.org/pdf/2501.15061
GitHub 链接:https://github.com/ZacharyMeng/PolaFormer
Huggingface 权重链接:https://huggingface.co/ZachMeng/PolaFormer/tree/main
尽管 Vision Transformer 及其变种在视觉任务上取得了亮眼的性能,但仍面临着自注意力机制时空间平方复杂度的挑战。为了解决这一问题,线性自注意力通过设计新的核函数替换标准自注意力机制中的 softmax 函数,使模型复杂度降低为线性。这篇论文中,研究者提出了一个新的「极性感知线性注意力」模块,使模型达到了更高的任务性能与计算效率。
具体来说,本工作从线性自注意力方法需要满足注意力权重矩阵的两个特性(即正值性和低信息熵)入手。首先,指出了现有的做法为了满足正值性,牺牲了 Q 矩阵和 K 矩阵元素中负值的缺陷,提出了极性感知的计算方式可以保证 Q 矩阵和 K 矩阵中所有元素可以平等地进行相似度的计算,使计算结果更准确,模型表示能力更强。其次,本文提出只要采用一族具有特殊性质的映射函数,就可以有效降低注意力权重分布的信息熵,并给出了数学上的证明。
大量的实验表明,本文提出的线性注意力模块可以直接替换现有 Vision Transformer 框架中的自注意力模块,并在视觉基础任务和 LRA 任务上一致地提升了性能。
引入
Transformer 模型已经在广泛的视觉任务中展现出亮眼的性能。其核心模块 —— 通过 softmax 归一化的点积自注意力机制,让 Transformer 模型可以有效地捕捉长距离依赖关系。然而,这带来了模型 O (N^2) 复杂度,在处理长序列视频或高分辨率图像时,会导致相当大的计算开销和显存占用。这限制了它们在资源受限环境中的效率,使得在这些场景下的实际部署变得困难。
线性注意力,作为一种更具可行性的解决方案使用核化特征映射替换 q,k 点积中的 Softmax 操作,有效地将时间和空间复杂度从 O (N²d) 降低到 O (Nd²)。尽管线性注意力在计算效率上有所提升,但在表达能力方面仍不及基于 Softmax 的注意力,我们的分析确定了造成这种不足的两个主要原因,它们都源于 Softmax 近似过程中的信息丢失:
负值丢失。依赖非负特征映射(如 ReLU)的线性注意力模型无法保持与原始 q,k 点积的一致性。这些特征映射仅保留了正 - 正交互作用,而关键的正 - 负和负 - 负交互作用则完全丢失。这种选择性表示限制了模型捕获全面关系范围的能力,导致注意力图的表达能力减弱和判别力降低。
注意力分布高信息熵。没有 softmax 的指数缩放,线性注意力会导致权重分布更加均匀且熵更低。这种均匀性削弱了模型区分强弱 q,k 对的能力,损害了其对重要特征的关注,并在需要精细细节的任务中降低了性能。
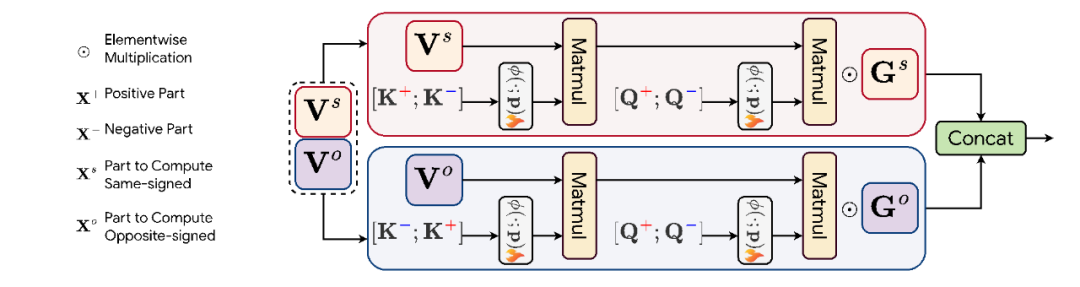
在这项工作中,作者提出了一种极性感知线性注意力(PolaFormer)机制,旨在通过纳入被忽略的负交互作用来解决先前线性注意力模型的局限性。与此同时,为了解决线性注意力中常见的注意力权重分布信息熵过高的问题,他们提供了数学理论基础,表明如果一个逐元素计算的函数具有正的一阶和二阶导数,则可以重新缩放 q,k 响应以降低熵。这些增强功能共同提供了一个更稳健的解决方案,以缩小线性化和基于 Softmax 的注意力之间的差距。
背景
标准自注意力机制的低效
考虑一个长度为 N、维度为 D 的序列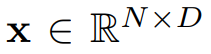 。该序列被分成 h 个头,每个头的维度是 d。在每个头中,不同位置的标记(token)共同被关注以捕获长距离依赖关系。输出可表示为
。该序列被分成 h 个头,每个头的维度是 d。在每个头中,不同位置的标记(token)共同被关注以捕获长距离依赖关系。输出可表示为
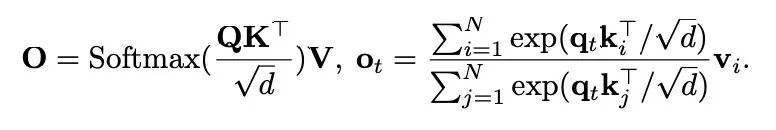
可见,自注意力的复杂度是 O (N2d)。这种复杂度使得自注意力机制在处理长序列时效率低下,导致计算成本急剧上升。目前,降低自注意力的复杂度的主要方法包括但不限于稀疏注意力、线性化注意力以及基于核的注意力等。
基于核的线性注意力
为了缓解标准自注意力机制的效率瓶颈,人们提出了基于核的线性注意力机制,该机制将相似度函数分解为特征映射的点积。按照 Linear Attention 工作里的符号,我们定义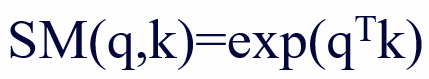 作为 softmax 核函数。从数学上讲,线性注意力的目标是使用 ϕ(q_i)ϕ(k_j)^T 来近似 SM (⋅,⋅),则注意力输出的第 t 行可以重写为:
作为 softmax 核函数。从数学上讲,线性注意力的目标是使用 ϕ(q_i)ϕ(k_j)^T 来近似 SM (⋅,⋅),则注意力输出的第 t 行可以重写为:
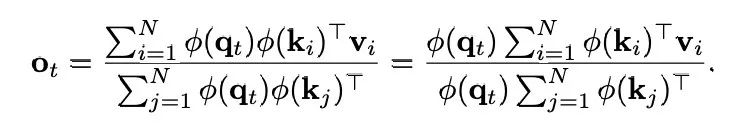
通过利用矩阵乘法的结合律,每个头的复杂度可以降低到 O (Nd’2),其中 d’是特征映射后的维度,与序列长度成线性关系。
方法概览
极性感知注意力
极性感知注意力背后的核心思想是为了解决现有线性注意力机制的局限性,这些机制通常会丢弃来自负成分的有价值信息。
PolaFormer 在处理负成分时,极性感知注意力将 query 和 key 向量分解为它们的正部和负部。这种分解允许机制分别考虑正相似度和负相似度对注意力权重的影响。具体来说,对于查询向量 q 和键向量 k,可以将它们分解为:
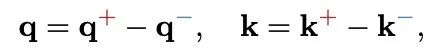
其中,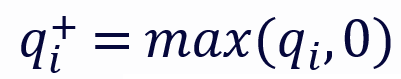 和
和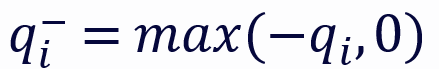 分别代表 q 的正部和负部,同理对于 k。
分别代表 q 的正部和负部,同理对于 k。
将这些分解代入 q 和 k 的内积中,可以得到:
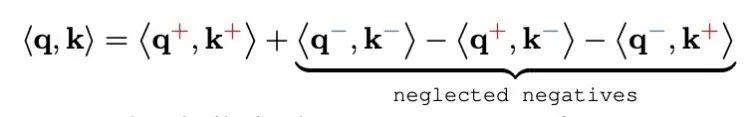
前两项捕捉了同号成分之间的相似性,而后两项则代表了异号成分之间的相互作用。之前的线性注意力方法,如基于 ReLU 的特征映射,通过将负成分映射到零来消除它们,这在近似 q,k 点积时会导致显著的信息丢失。
为了解决这个问题,极性感知注意力机制根据 q,k 的极性将它们分开,并独立计算它们之间的相互作用。注意力权重的计算方式如下:
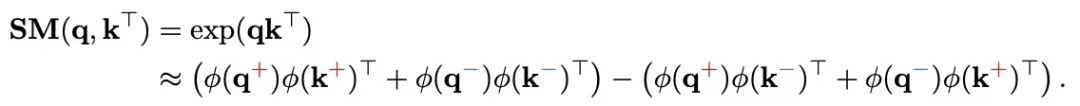
PolaFormer 根据极性明确地将 q,k 对分开,处理在内积计算过程中维度的同号和异号交互作用。这些交互作用在两个流中处理,从而能够更准确地重建原始的 softmax 注意力权重。为了避免不必要的复杂性,作者沿着通道维度拆分 v 向量,在不引入额外可学习参数的情况下处理这两种类型的交互作用。然后,将输出进行拼接,并通过一个可学习的符号感知矩阵进行缩放,以确保准确重建 q,k 关系。
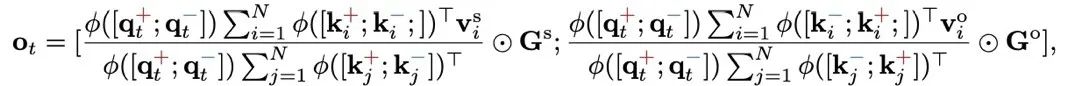
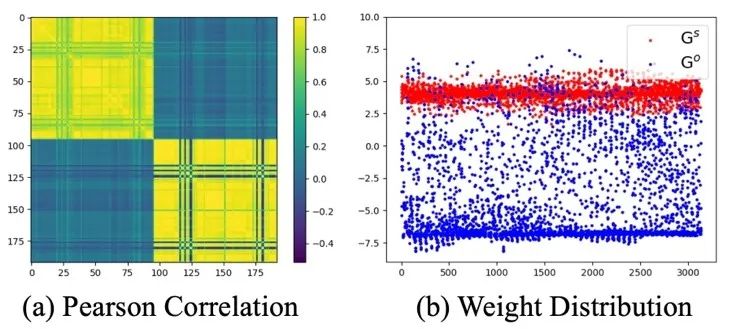
作者统计分析了两个 G 矩阵的特性,存在一个明显的负相关和价值差异。这证明了本文提出的可学习混合策略补偿了松弛减法操作所带来的影响。
用于降低信息熵的可学习幂函数
为了解决线性注意力中常见的注意力权重分布信息熵过高的问题,作者提供了数学理论基础,表明如果一个逐元素计算的函数具有正的一阶和二阶导数,则可以重新缩放 q,k 响应以降低熵。
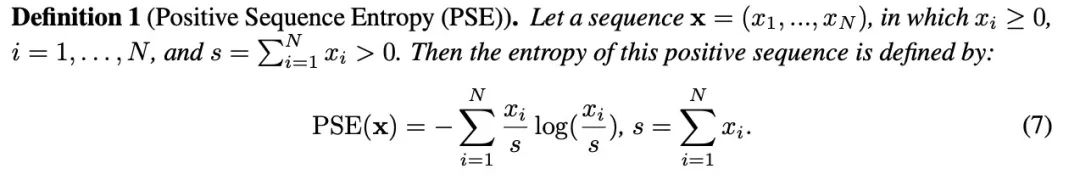

这一理论有助于阐明为什么先前的特征映射会提高信息熵,从而导致注意力分布过于平滑。为了简化,作者采用通道级可学习的幂函数进行重新缩放,这保留了 Softmax 中固有的指数函数的尖锐性。这使得模型能够捕获尖锐的注意力峰值,提高了其区分强弱响应的能力。与此同时,为了区分开不同通道之间的主次关系,作者设计了可学习的幂次来捕捉每个维度的不同重要性
最后,由于之前的理论工作已经表明,自注意力矩阵本质上是低秩的。这一特性在学习 v 向量时可能导致退化解,尤其是在本文的情况下,当需要紧凑的表示来容纳极性感知信息时。作者探索了各种技术来增加秩并进行了消融实验,比如 DWC 和 DCN。
实验结果
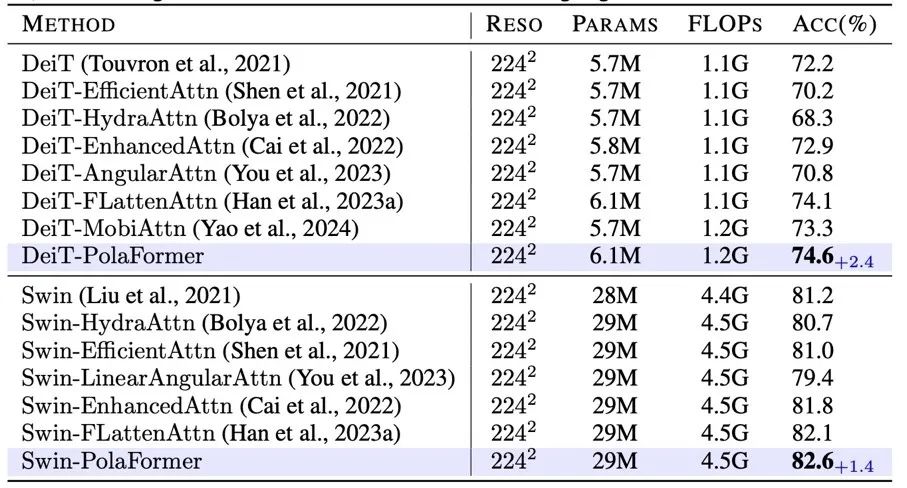
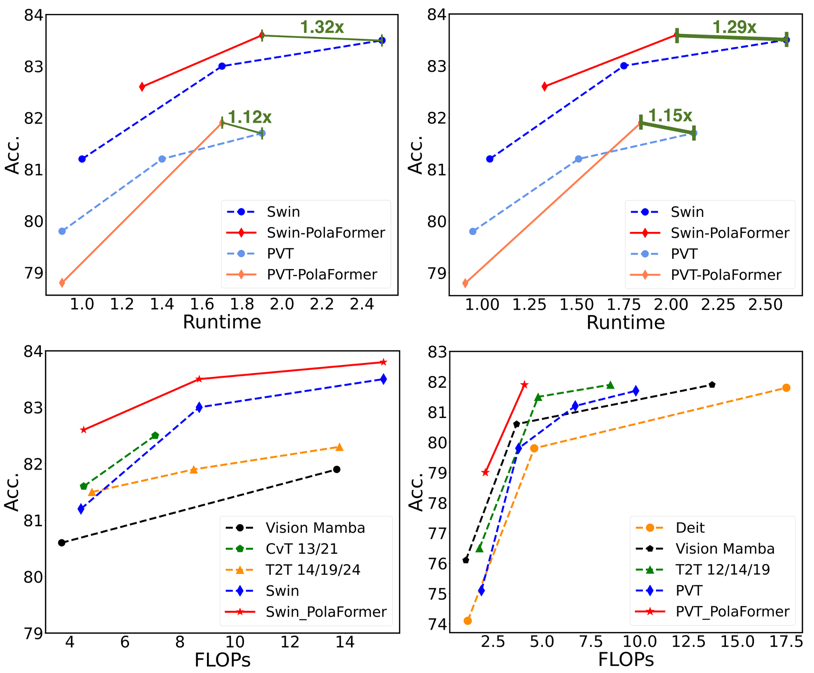
作者对模型在三个任务上进行了评估:图像分类、目标检测和实例分割,以及语义分割。作者将模型性能与之前的高效视觉模型进行了比较。此外,他们在 LRA 任务上评估了模型,便于与其他线性注意力模型进行对比。
首先,作者从头开始在图像分类任务上训练了模型。然后,他们在 ADE20K 数据集上对预训练模型进行微调,用于语义分割任务,还在 COCO 数据集上进行微调,用于目标检测任务。
结论
在本研究中,作者提出了 PolaFormer,这是一种具有线性复杂度的新型高效 Transformer,主要贡献如下:
本文指出现有方法负值忽略的问题,提出了极性感值的映射函数,让每个元素都参与到注意力的计算;
在理论上,作者提出并证明了存在一族逐元素函数能够降低熵,并采用了可学习的幂函数以实现简洁性和重新缩放。
此外,作者还使用了卷积来缓解由自注意力矩阵的低秩特性引起的退化解问题,并引入了极性感知系数矩阵来学习同号值和异号值之间的互补关系。
大家快扫码领取!CVer学术星球春节优惠券来了!为了感谢大家的支持,现在赠送50元新用户优惠券(左图),7折+20元老用户续费券(右图),蛇年坚持分享更新更优质的AI工作,寒假不停更!最强助力你的科研和工作!

何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









