






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

作者:科技猛兽 | 转载自:极市平台
导读
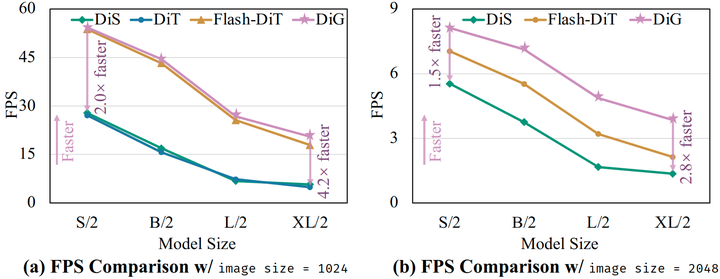
在相同的模型尺寸下,DiG-XL/2 比基于 Mamba 的扩散模型在 1024 的分辨率下快 4.2 倍,在 2048 的分辨率下比带有 CUDA 优化的 FlashAttention2 的 DiT 快 1.8 倍。这些结果都证明了其优越性能。
本文目录
1 DiG:使用门控线性注意力机制的高效可扩展 Diffusion Transformer
(来自华科,字节跳动)
1 DiM 论文解读
1.1 DiG:一种轻量级 DiT 架构
1.2 门控线性注意力 Transformer
1.3 扩散模型
1.4 Diffusion GLA 模型
1.5 DiG Block 架构
1.6 复杂度分析
1.7 实验结果
太长不看版
Diffusion Transformer 模型面临的一个问题是计算复杂度与序列长度呈二次方关系,这不利于扩散模型的缩放。本文通过门控线性注意力机制 (Gated Linear Attention) 的长序列建模能力来应对这个问题,来提升扩散模型的适用性。
本文提出的模型称为 Diffusion Gated Linear Attention Transformers (DiG),是一种基于门控线性注意力机制和 DiT[1]的简单高效的扩散 Transformer 模型。除了比 DiT 更好的性能外,DiG-S/2 的训练速度比 DiT-S/2 高 2.5 倍,并在 1792 的分辨率节省 75.7% 的 GPU 显存。此外,作者分析了 DiG 在各种计算复杂度下的可扩展性。结果是随着模型的缩放,DiG 模型始终表现出更优的 FID。作者还将 DiG 与其他次 subquadratic-time 的扩散模型进行了比较。在相同的模型尺寸下,DiG-XL/2 比基于 Mamba 的扩散模型在 1024 的分辨率下快 4.2 倍,在 2048 的分辨率下比带有 CUDA 优化的 FlashAttention2 的 DiT 快 1.8 倍。这些结果都证明了其优越性能。
本文做了哪些具体的工作
提出了 Diffusion GLA (DiG),通过分层扫描和局部视觉感知进行全局视觉上下文建模。DiG 使用线性注意力 Transformer 来实现 diffusion backbone。
DiG 在训练速度和 GPU 显存成本方面都表现出更高的效率,同时保持与 DiT 相似的建模能力。具体而言,DiG 比 DiT 快 2.5 倍,并在 1792×1792 的分辨率中节省 75.7% 的 GPU 显存,如图1所示。
作者在 ImageNet 数据集上进行了广泛的实验。结果表明,与 DiT 相比,DiG 表现出可扩展的能力并实现了卓越的性能。在大规模长序列生成的背景下,DiG 有望成为下一代 Backbone。
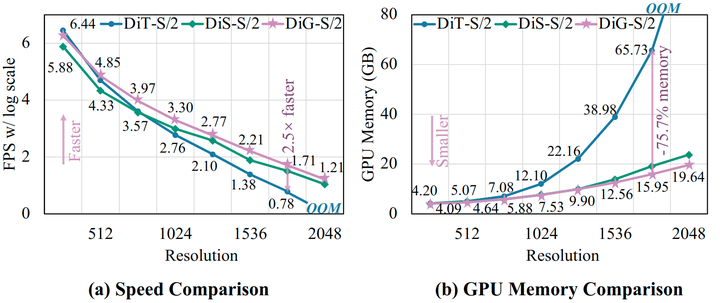
1 DiG:使用门控线性注意力机制的高效可扩展 Diffusion Transformer
论文名称:DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention (Arxiv 2024.05)
论文地址:
http://arxiv.org/pdf/2405.18428
代码链接:
http://github.com/hustvl/DiG
1.1 DiG:一种轻量级 DiT 架构
扩散模型以其生成高质量的图像生成能力而闻名。随着采样算法的快速发展,主要技术根据其 Backbone 架构演变为2个主要类别:基于 U-Net 的方法[2]和基于 ViT 的方法[3]。基于 U-Net 的方法继续利用卷积神经网络 (CNN) 架构,其分层特征建模能力有利于视觉生成任务。另一方面,基于 ViT 的方法结合注意力机制。由于其出色的性能与可扩展性,基于 ViT 的方法已被用作最先进的扩散工作中的 Backbone,包括 PixArt、Sora、Stable Diffusion 3 等。然而,基于 ViT 的架构的 Self-attention 机制与输入序列长度呈二次方关系,使得它们在处理长序列生成任务 (例如高分辨率图像生成、视频生成等) 时资源消耗较大。最近的架构 Mamba[4]、RWKV[5]和 Gated Linear Attention Transformer (GLA)[6],试图通过集成 RNN 类的架构,以及硬件感知算法来提高长序列处理效率。其中,GLA 将依赖于数据的门控操作和硬件高效的实现结合到线性注意力 Transformer 中,显示出具有竞争力的性能,但吞吐量更高。
受 GLA 在自然语言处理领域的成功的启发,作者将这种成功从语言生成转移到视觉内容生成领域,即使用高级线性注意力设计可扩展且高效的 Diffusion Backbone。然而,使用 GLA 进行视觉生成面临两个挑战,即单向扫描建模和缺乏局部信息。为了应对这些挑战,本文提出了 Diffusion GLA (DiG) 模型,该模型结合了一个轻量级的空间重定向和增强模块 (Spatial Reorient & Enhancement Module, SREM),用于分层扫描方向控制和局部感知。扫描方向包含四个基本模式,并使序列中的每个 Patch 能够感知沿纵横方向的其他 Patch。此外,作者还在 SREM 中加入了深度卷积 (DWConv),使用很少的参数为模型注入局部信息。
1.2 门控线性注意力 Transformer
Gated Linear Attention Transformer (GLA) 结合依赖于数据的门控机制和线性注意力, 实现了卓越的循环建模性能。给定输入 ( 是序列长度, 是维度),GLA 计算 Query、Key 和 Value 向量:
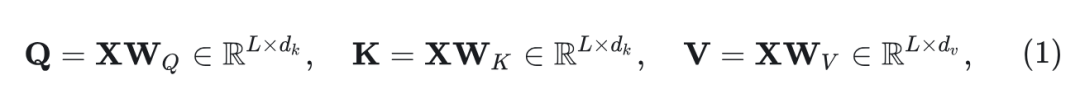
式中 是线性投影权重。 和 是维度数。接下来, GLA 计算门控矩阵 ,如下所示:
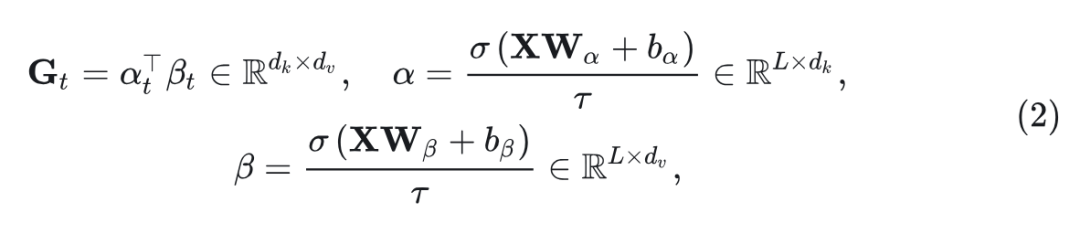
其中 是 token 的索引, 是 sigmoid 函数, 是偏置项, 是温度项。如图3所示, 最终输出 如下:
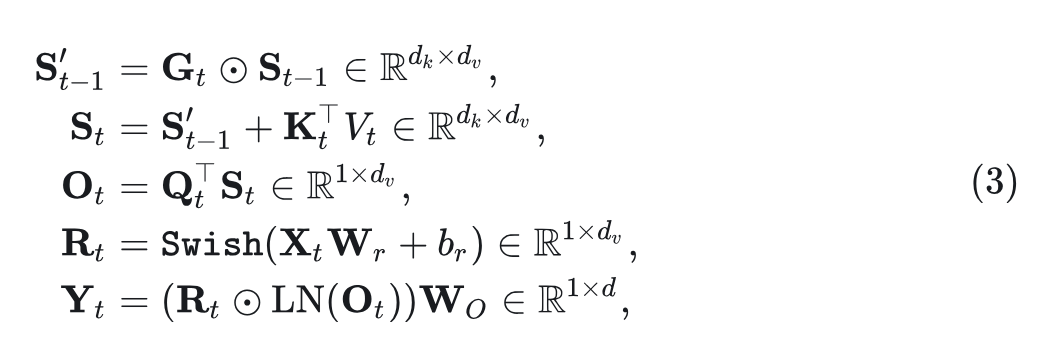
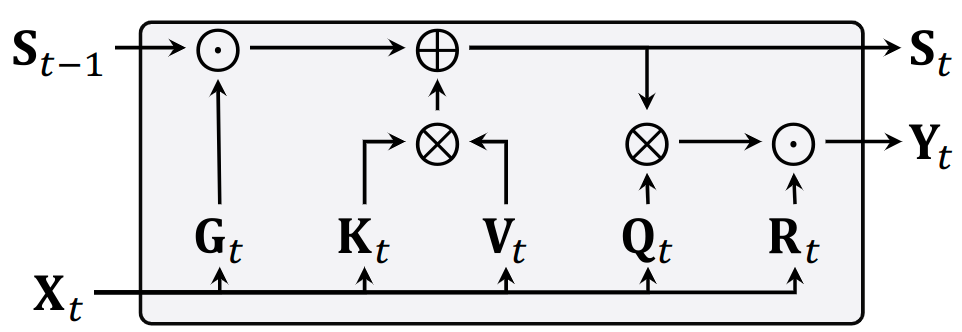
其中, Swish 是 Swish 激活函数, 是逐元素乘法运算。在接下来的部分中, 使用 来指代输入序列的门控线性注意力计算。
1.3 扩散模型
DDPM[7]通过迭代去噪输入将噪声作为输入和采样图像。DDPM 的前向过程是随机过程,其中初始图像 逐渐被噪声破坏,最后转化为更简单、噪声主导的状态。前向噪声过程可以表示如下:
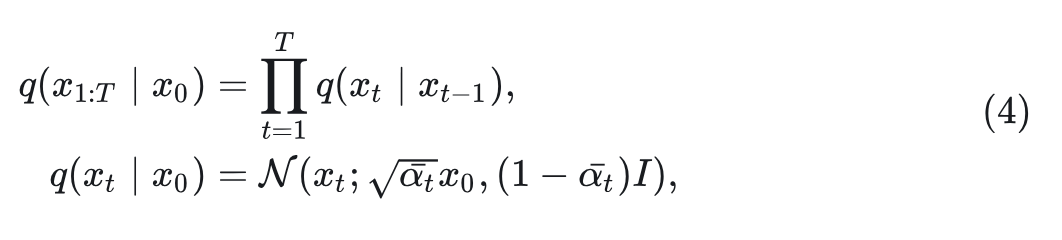
其中 是从时间 到 的噪声图像序列。然后, DDPM 使用可学习的 和 恢复原始图像的反向过程:
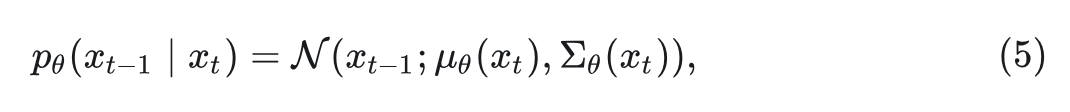
其中, 是去噪模型的参数, 使用 variational lower bound 在观测数据 的分布下训练:
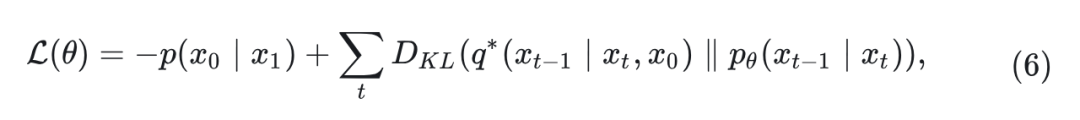
其中, 是总的损失函数。为了进一步简化 DDPM 的训练过程, 研究人员将 重参数化为噪声预测网络 , 使 与真实高斯噪声 之间的均方误差损失 做最小化:
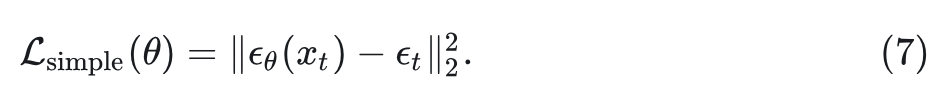
然而, 为了训练能够学习反向过程协方差 Σ𝜃 的扩散模型, 就需要优化完整的 𝐷𝐾𝐿 项。本文作者遵循 DiT 训练网络, 其中使用损失 𝐿simple 来训练噪声预测网络 𝜖𝜃, 并使用全损失 𝐿 来训练协方差预测网络 Σ𝜃 。
1.4 Diffusion GLA 模型
本文提出了 Diffusion GLA (DiG),一种用于生成任务的新架构。本文的目标是尽可能忠实于标准的 GLA 架构,以保持其缩放能力和高效率的特性。GLA 的概述如图 3 所示。
标准 GLA 一般用于一维序列的因果语言建模。为了适配图像的 DDPM 训练, 本文遵循 ViT 架构的实践。DiG 以 VAE 编码器的输出的空间表征 作为输入。对于 的图像, VAE 编码器的空间表征 的形状为 。DiG 随后通过 Patchify 层将空间输入转换为 token 序列 , 其中 为序列的长度, 为空间表示通道数, 为图像补丁的大小, 因此 的减半将使得 变为 4 倍。接下来, 将 线性投影到维度为 的向量上, 并将基于频率的位置嵌入 添加到所有投影 token 中, 如下所示:
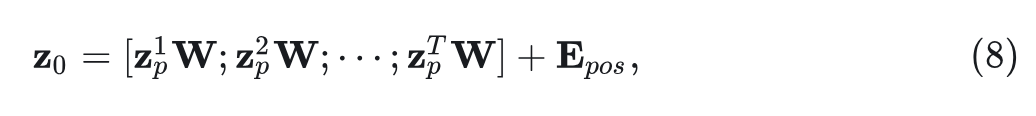
其中 是 的第 个 Patch, 是可学习的投影矩阵。至于噪声时间步 和类标签 等条件信息, 作者分别采用多层感知 (MLP) 和嵌入层作为 timestep embedder 和 label embedder。
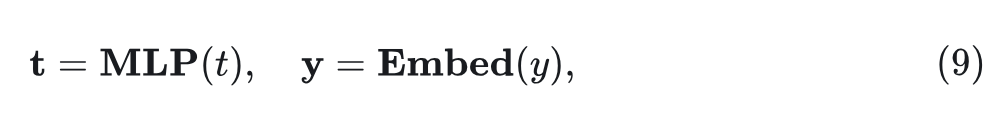
其中 是 time Embedding, 是 label Embedding。然后, 作者将令牌序列 发送到 DiG 编码器的第 层, 得到输出 。最后, 对输出标记序列 进行归一化, 并将其馈送到线性投影头以获得最终预测的噪声 和预测的协方差 , 如下所示:
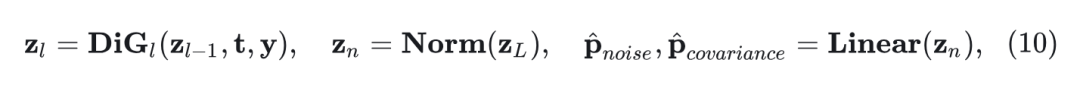
其中, 是第 个扩散 Block, 是层数, Norm 是归一化层。 和预测的协方差 与输入空间表示具有相同的形状, 即 。
1.5 DiG Block 架构
原始的 GLA Block 以循环格式处理输入序列,这只能对 1-D 序列进行因果建模。本文提出的 DiG 的 Block 架构集成了一种空间重定向和增强模块 (Spatial Reorient & Enhancement Module, SREM),用于控制逐层扫描方向。DiG Block 架构如下图4所示。
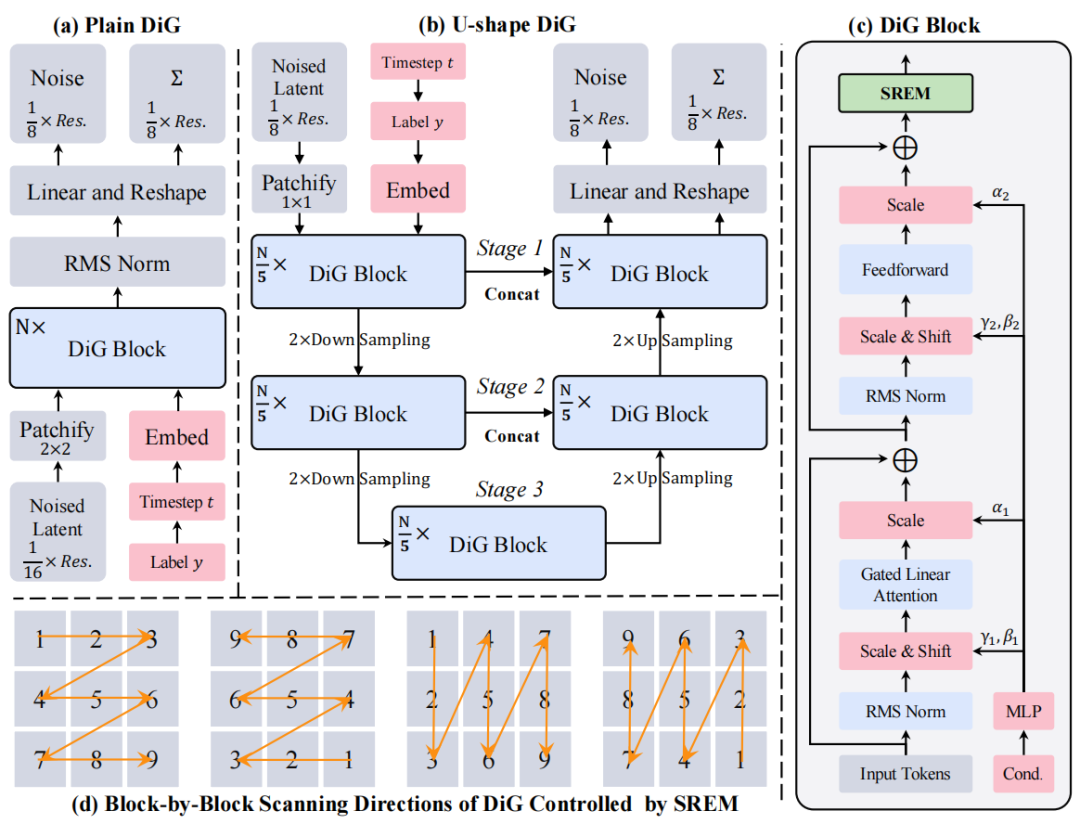
作者通过调整回归自适应层范数 (adaLN) 参数来启动门控线性注意 (GLA) 和前馈网络 (FFN)。

然后,作者把序列改为 2D 的形状,并使用一个轻量级的 3×3 深度卷积来感知局部空间信息。但使用传统的 DWConv2d 初始化会导致收敛速度慢,因为卷积权重分散在周围。为了解决这个问题,作者提出了 Identity 初始化,将卷积核中心设置为1,将周围其他设置为0。最后,每两个块执行转置 2D token 矩阵,并翻转展平的序列,来控制下一个 Block 的扫描方向。如图4右侧所示,每层只处理一个方向的扫描。
1.6 复杂度分析
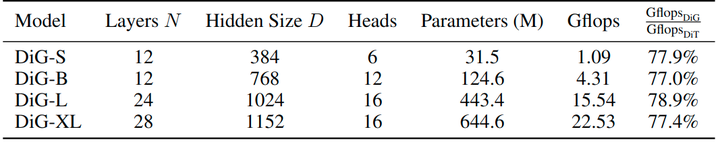
DiG 架构共有4种尺寸,分别是 DiG-S, DiG-B, DiG-L, 和 DiG-XL,配置如下图6所示。其参数量从 31.5M 到 644.6M,计算量从 1.09GFLOPs 到 22.53GFLOPs。值得注意的是,与相同大小的基线模型 (即 DiT) 相比,DiG 只消耗 77.0% 到 78.9% 的 GFLOPs。
GPU 包含两个重要的组件, 即高带宽内存 (HBM) 和 SRAM。HBM 具有更大的内存大小, 但 SRAM 具有更大的带宽。为了以并行形式充分利用 SRAM 和建模序列, GLA 将整个序列拆分为许多块, 可以在 SRAM 上完成计算。定义块的尺寸为 𝑀, 训练复杂度是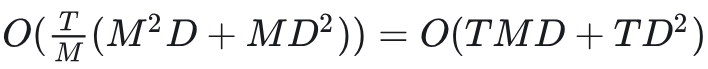 𝑂(𝑇𝑀(𝑀2𝐷+𝑀𝐷2))=𝑂(𝑇𝑀𝐷+𝑇𝐷2) 。当 𝑇<𝐷 时, 略小于传统注意力机制的计算复杂度 𝑂(𝑇2𝐷) 。此外, DiT Block 中的 Depth-wise 卷积和高效矩阵运算也保证了效率。
𝑂(𝑇𝑀(𝑀2𝐷+𝑀𝐷2))=𝑂(𝑇𝑀𝐷+𝑇𝐷2) 。当 𝑇<𝐷 时, 略小于传统注意力机制的计算复杂度 𝑂(𝑇2𝐷) 。此外, DiT Block 中的 Depth-wise 卷积和高效矩阵运算也保证了效率。
1.7 实验结果
作者使用 ImageNet 进行 class-conditional 图像生成任务的训练,分辨率为 256×256。作者使用水平翻转作为数据增强,使用Frechet Inception Distance (FID)、Inception Score、sFID 和 Precision/Recall 来衡量生成性能。
使用恒定学习率为 1e-4 的 AdamW 优化器。遵循 DiT 的做法在训练期间对 DiG 权重进行指数移动平均 (EMA),衰减率为 0.9999。使用 EMA 模型生成图像。对于 ImageNet 的训练,使用现成的预训练的 VAE。
如下图7所示,作者分析了所提出的空间重定向和增强模块 (SREM) 的有效性。作者将 DiT-S/2 作为基线方法。原始的 DiG 模型只有 causal modeling,计算量和参数量都很少。但是因为缺乏全局上下文,因此 FID 很差。作者首先向 DiG 添加双向扫描,并观察到了显著的改进,证明了全局上下文的重要性。而且,使用 Identity 初始化的 DWConv2d 也可以大大提高性能。DWConv2d 的实验证明了 Identity 初始化和局部信息的重要性。最后一行的实验表明,完整的 SREM 可以实现最佳的性能,且同时关注局部和全局上下文。
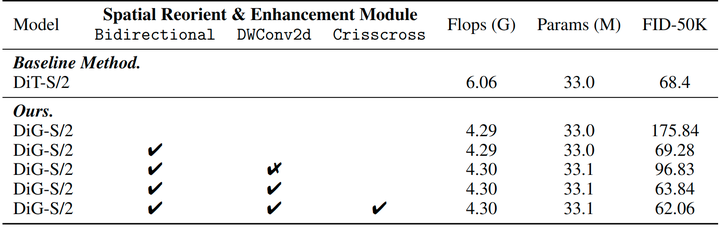
缩放模型尺寸
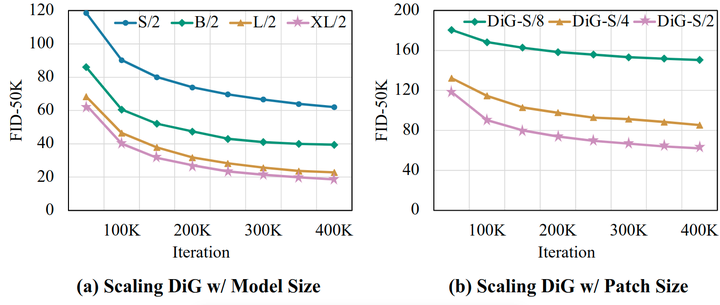
作者研究了 DiG 在 ImageNet 上的四种不同模型尺度之间的缩放能力。如图 8(a) 所示,随着模型从 S/2 扩展到 XL/2,性能有所提高。结果表明了 DiG 的缩放能力,以及作为基础扩散模型的潜力。
Patch Size 的影响
作者在 ImageNet 上训练了 Patch Size 从 2、4 和 8 不等的 DiG-S。如图 8(b) 所示,通过减少 DiG 的 Patch Size,可以在整个训练过程中观察到明显的 FID 优化。因此,最佳性能需要更小的 Patch Size 和更长的序列长度。与 DiT 基线相比,DiG 在处理长序列生成任务方面更有效。
作者将所提出的 DiG 与基线方法 DiT 进行比较,二者具有相同的超参数,结果如下图9所示。所提出的 DiG 在 400K 训练迭代的4个模型尺度上优于 DiT。此外,与以前的最先进方法相比,classifier-free guidance 的 DiG-XL/2-1200K 也显示出具有竞争力的结果。
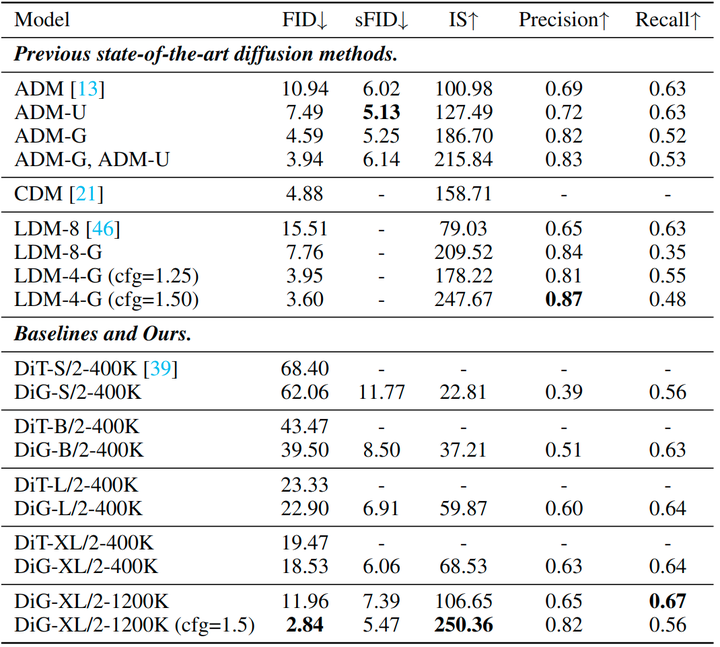
图10展示了从 DiG-XL/2 中采样的结果,这些结果来自 ImageNet 训练的模型,分辨率为 256×256。结果表明,DiG 生成结果的正确的语义和精确的空间关系。

参考
^Scalable Diffusion Models with Transformers
^Denoising Diffusion Probabilistic Models
^An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
^Mamba: Linear-Time Sequence Modeling with Selective State Spaces
^RWKV: Reinventing RNNs for the Transformer Era
^abGated Linear Attention Transformers with Hardware-Efficient Training
^Denoising Diffusion Probabilistic Models
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









