






Transformer的基本结构

Transformer模型结构
与seq2seq模型类似,Transformer是一种编码器-解码器结构的模型
Transformer的过程——编码器(Encoder)

Encoder步骤1
对于encoder,第一步是将所有的输入词语进行Embedding,然后将其与维度相同的位置向量组合(相加)
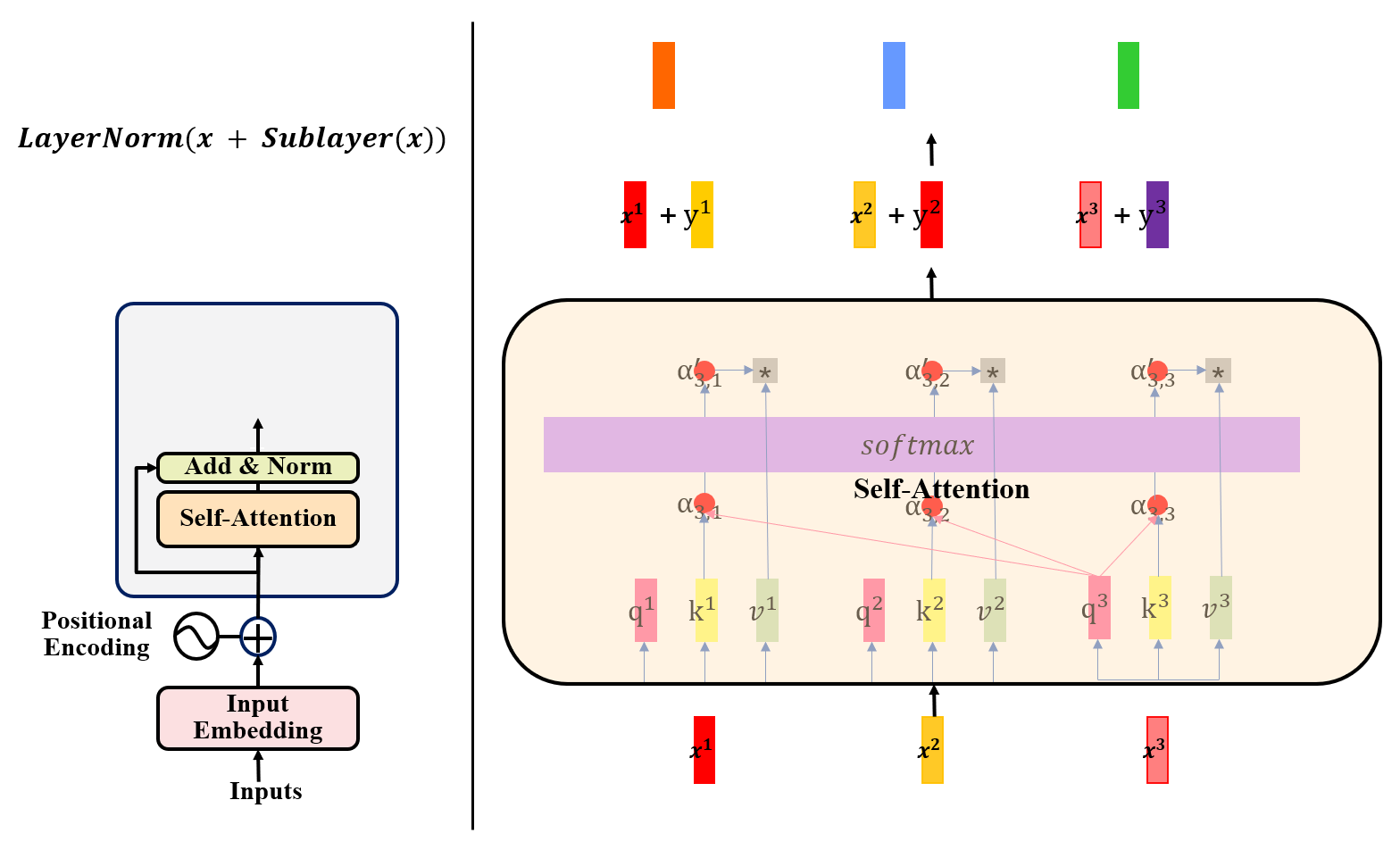
Encoder步骤2
在第二步中,将第一步得到的向量通过self-attention层,得到输出向量。在得到输出向量后,我们可以看到,在self-attention层后还包含着一个残差网络与LayerNorm操作。
这里残差网络的原理我们不做细致讨论。从实际操作的角度来看,其就是将自注意力层处理后的向量加上自注意力层处理前的向量:也就是H(x)=F(x)+x,H(x)是残差网络的结果,F(x)代表是自注意力机制。
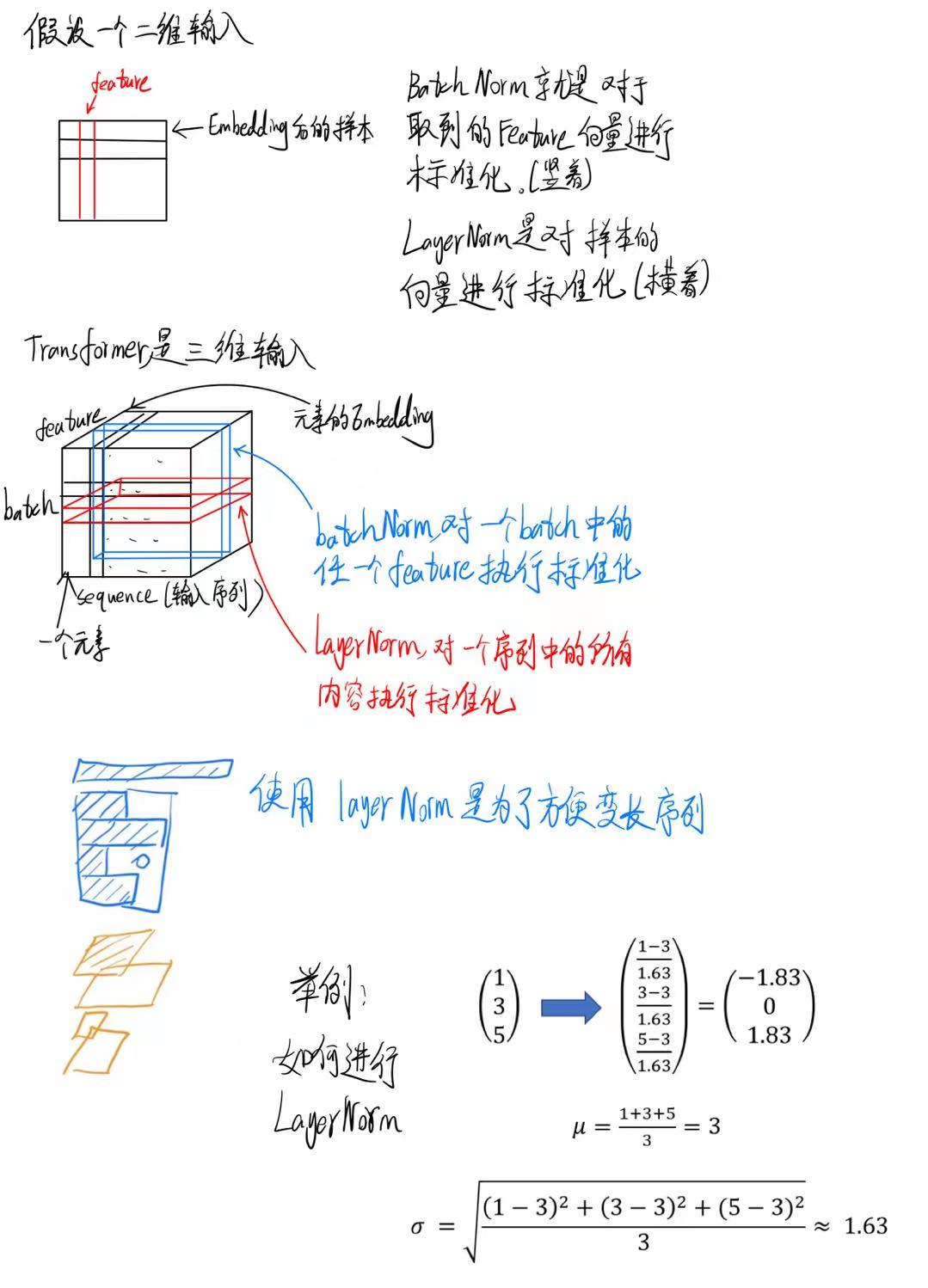
LayerNorm的操作
以上展示的是LayerNorm的操作。
在经过该步骤后,便是非常常规的操作:
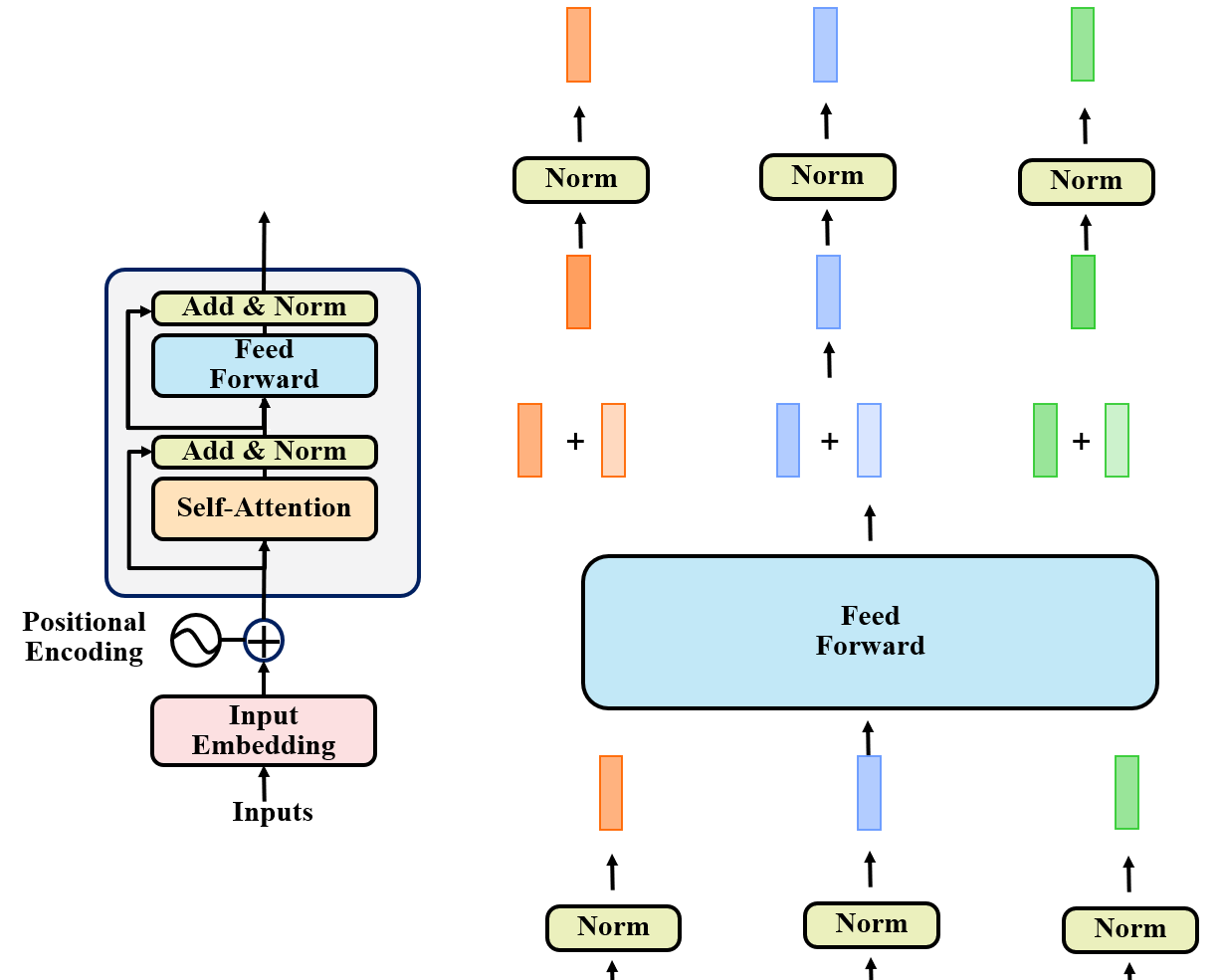
Encoder步骤3
将LayerNorm输出的向量,经过全连接层,然后再经过一个残差网络以及LayerNorm,便可得到一个Encoder的输出。
Transformer的过程——解码器(Decoder)
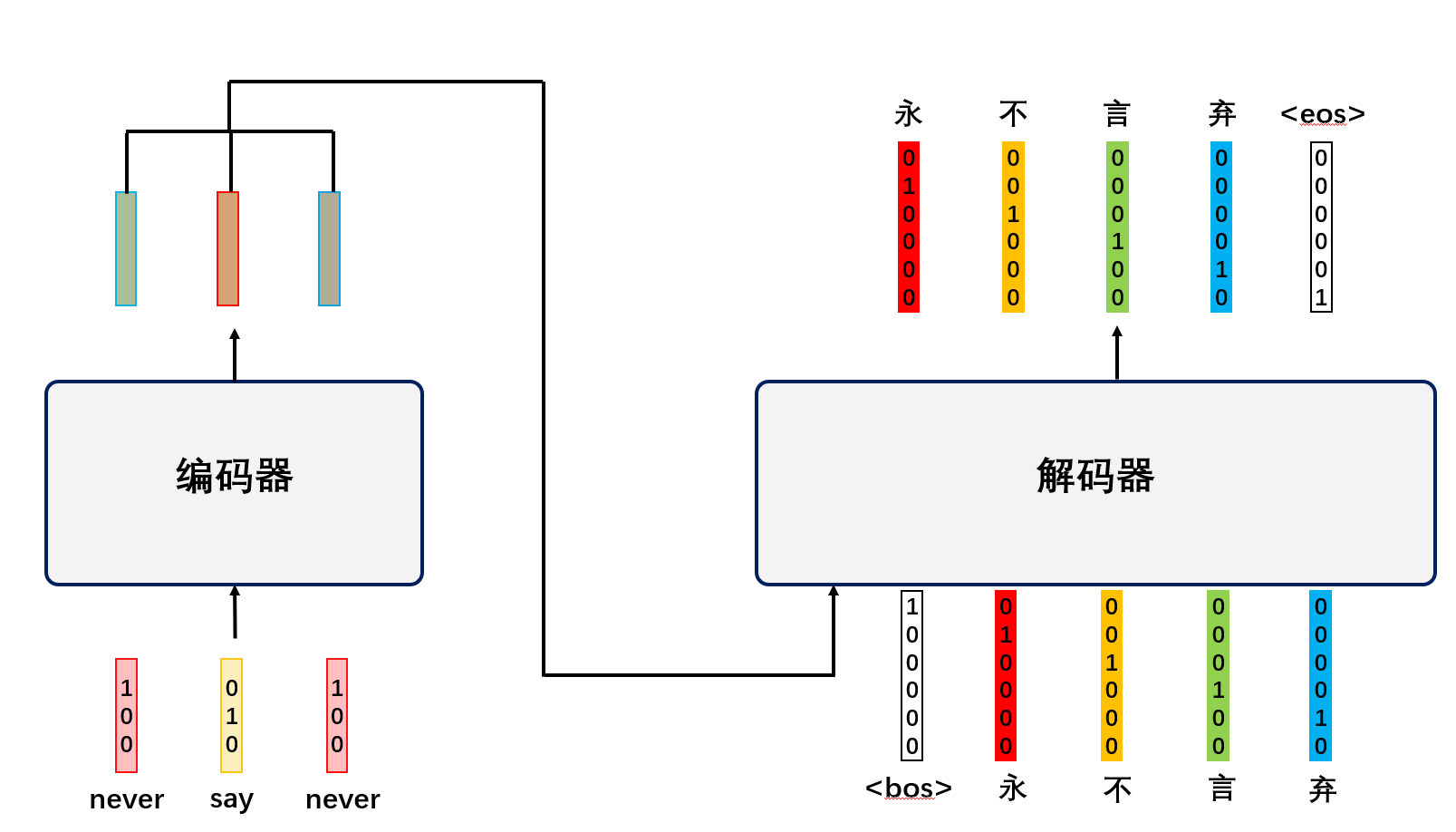
解码器整体流程1
在详细讨论Decoder前,我们需要注意到,Transformer的解码器是一个自回归的机制,也就是说,解码器的输出会作为其下一个输入。

解码器整体流程2
由于解码器所用知识与编码器类似,如Embedding,位置编码,再次不做赘述。
如上图,整体来看,在解码器通过开始符号<bos>以及其预测出来的“永不”后,经过一些操作,预测出“言”,以此类推,在下一个阶段,就是通过“<bos>永不言”来预测下一个输出。
在这个过程中,解码器使用了Masked Self-attention,下面来进行解释。
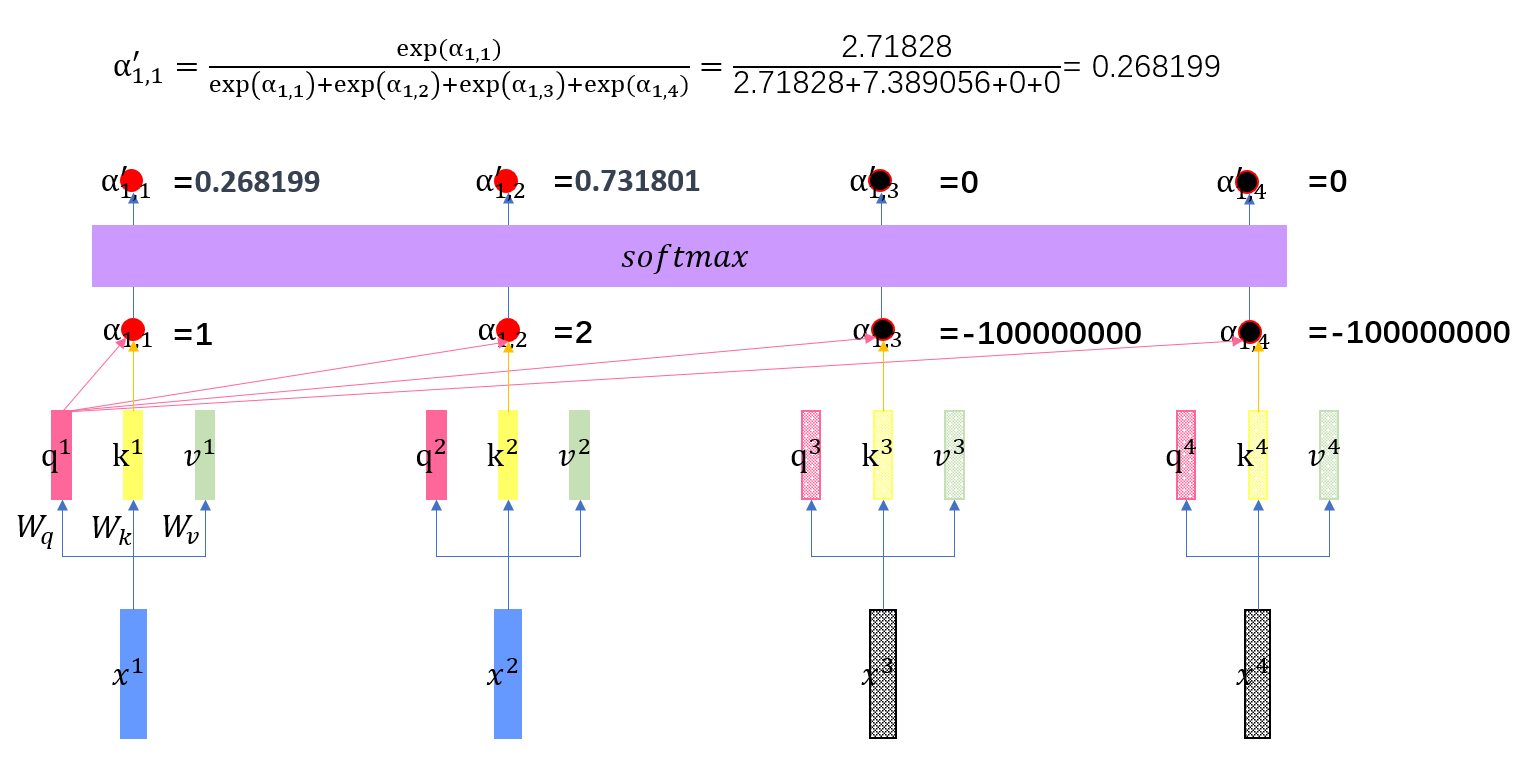
解码器步骤1
对于乱码部分的注意力分数,我们设置为一个非常小的数,使得其e指数接近0,设置后再计算注意力分数,得到以及预测出来部分之间的相互注意力得分。
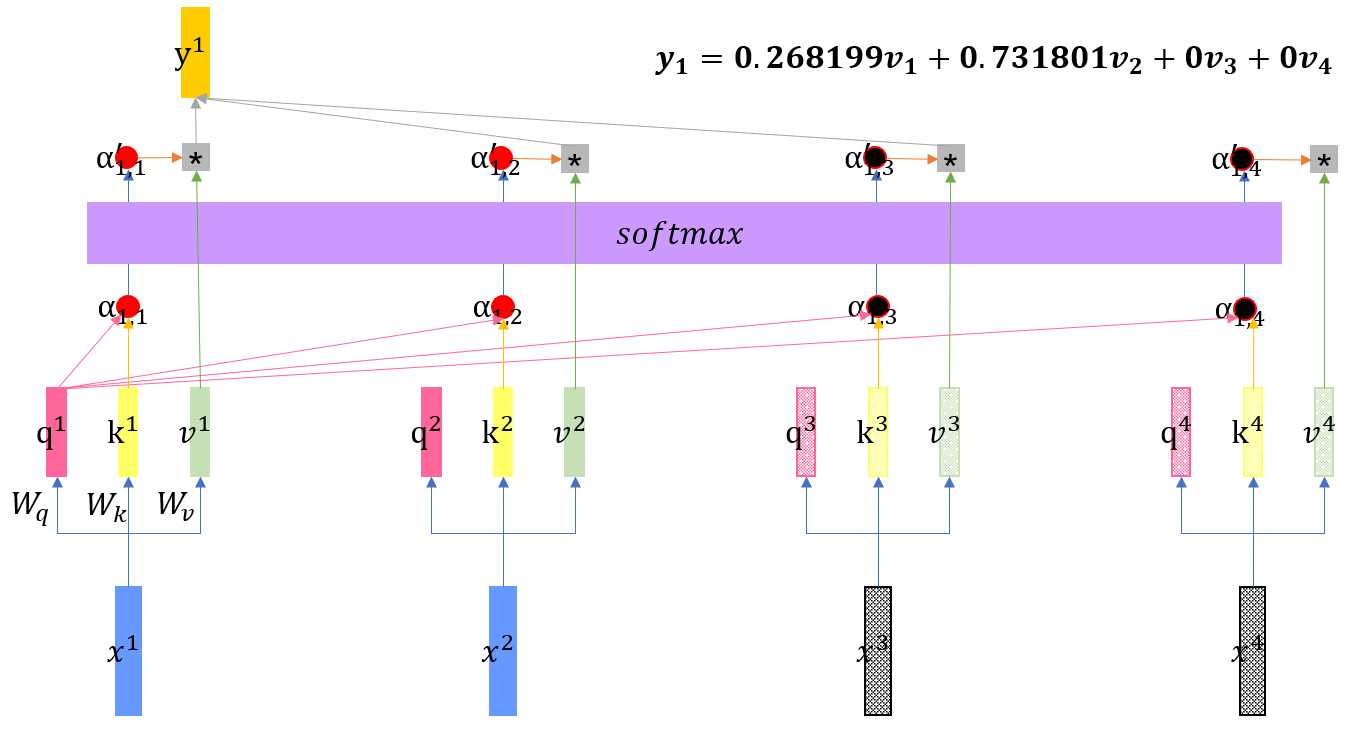
解码器步骤2
得到注意力得分后,与编码器类似,计算向量y。
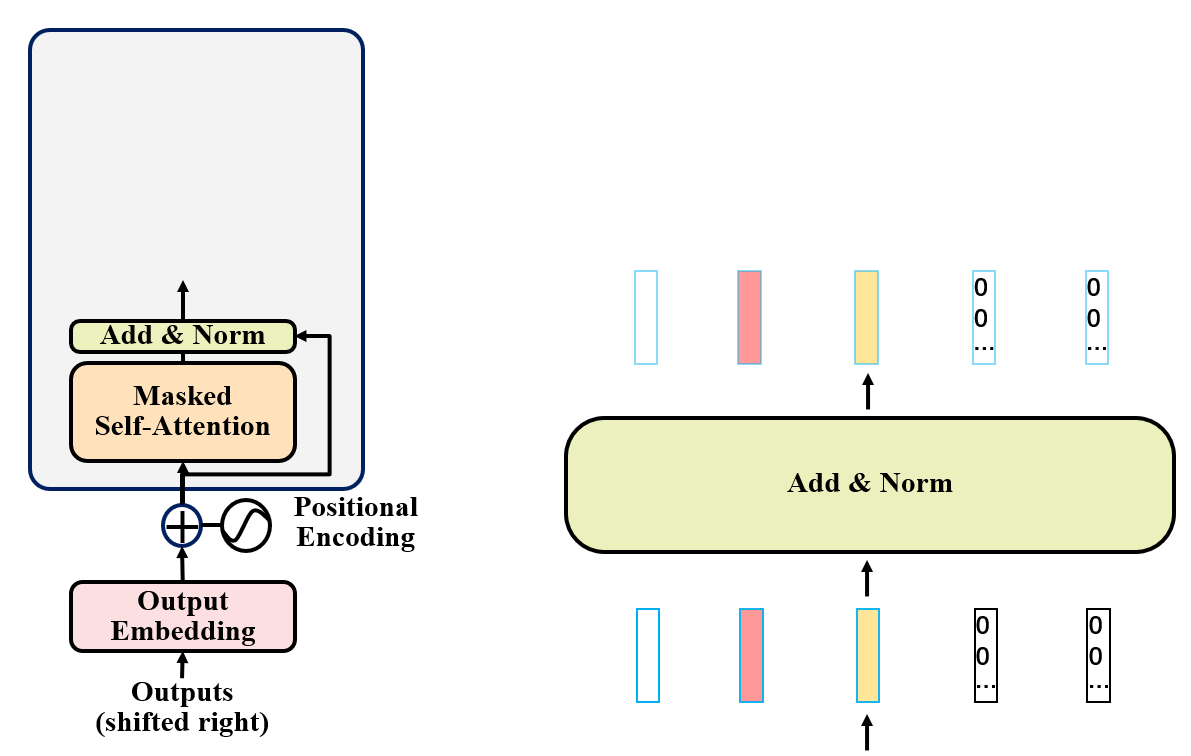
解码器步骤3
得到向量y后,与编码器类似,使用残差网络,并计算LayerNorm。
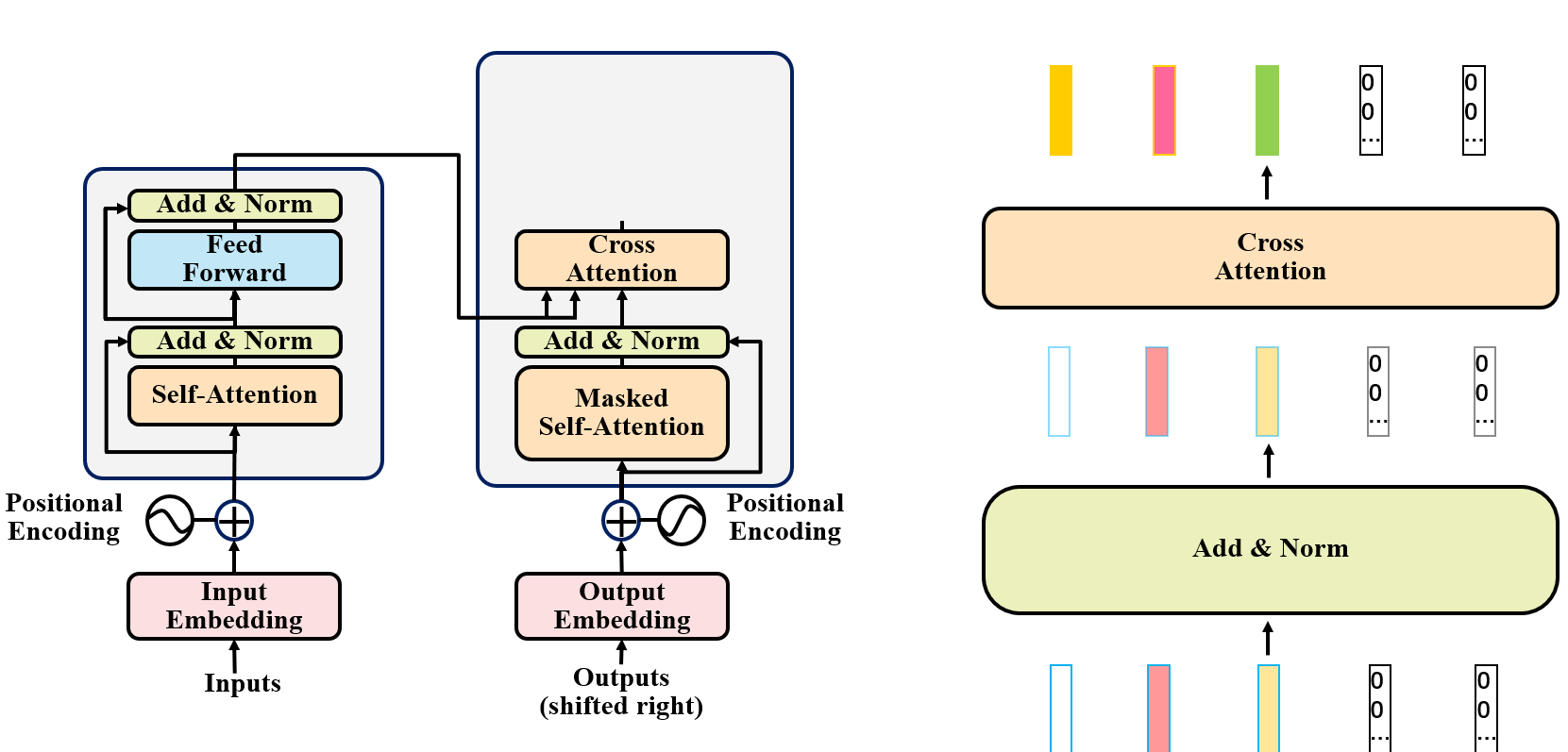
解码器步骤4
在此之上,与编码器不同的是,我们使用输出的向量,与编码器的输出向量计算一个Cross-Attention,下面我们解释Cross-Attention的含义。
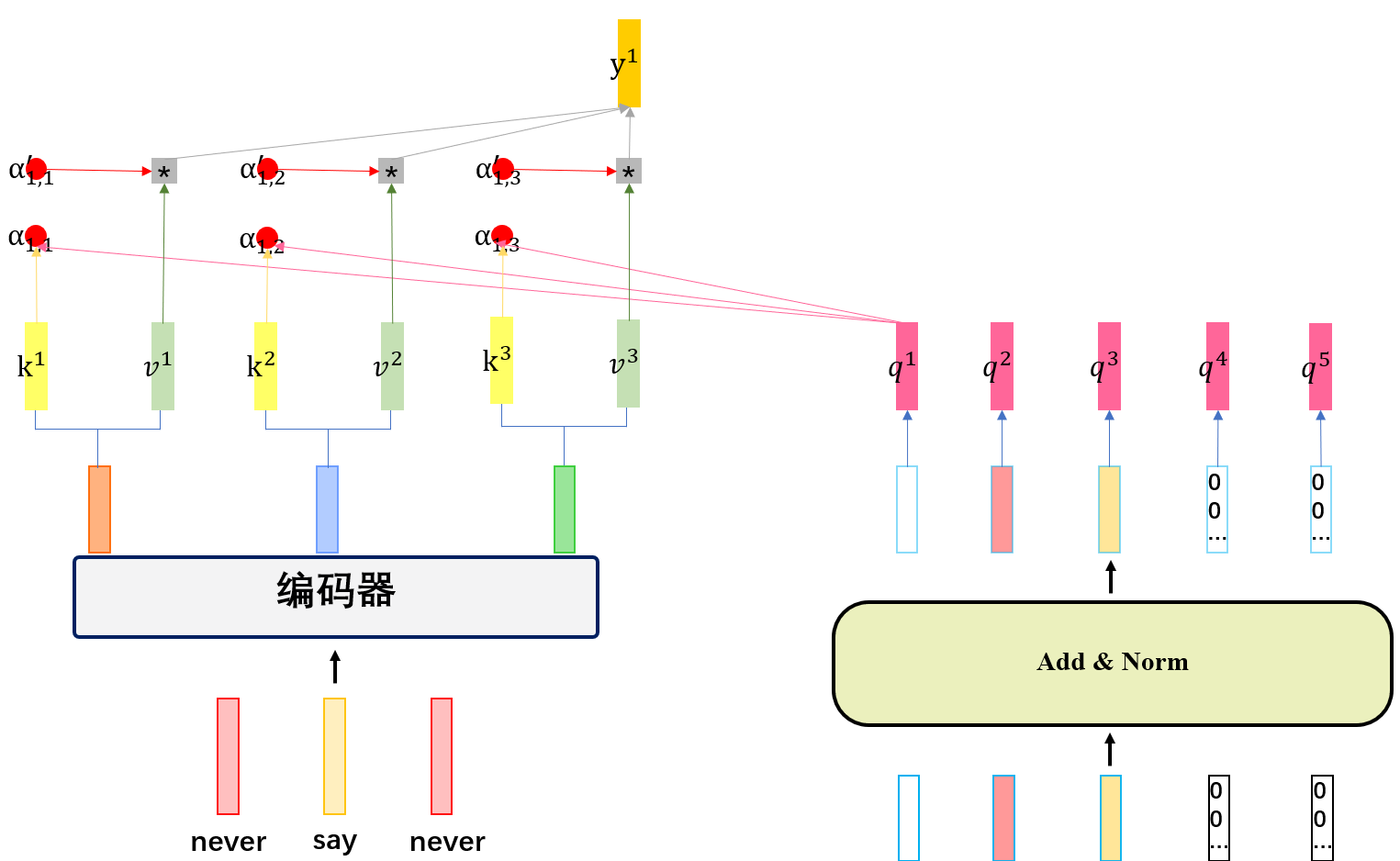
解码器步骤5——Cross-attention
这里可以看出,cross-attention是将上一步中,解码器Add&Norm的输出向量,乘以Wq矩阵,得到q(query)向量,再和编码器最后一层的输出向量的k向量做内积得到注意力分数,再与编码器最后一层的输出向量的v向量相乘得到y向量,也就是cross-attention的输出。
截至到这里,所有的复杂问题基本全部结束了,后面的内容都是相关知识点的重复。
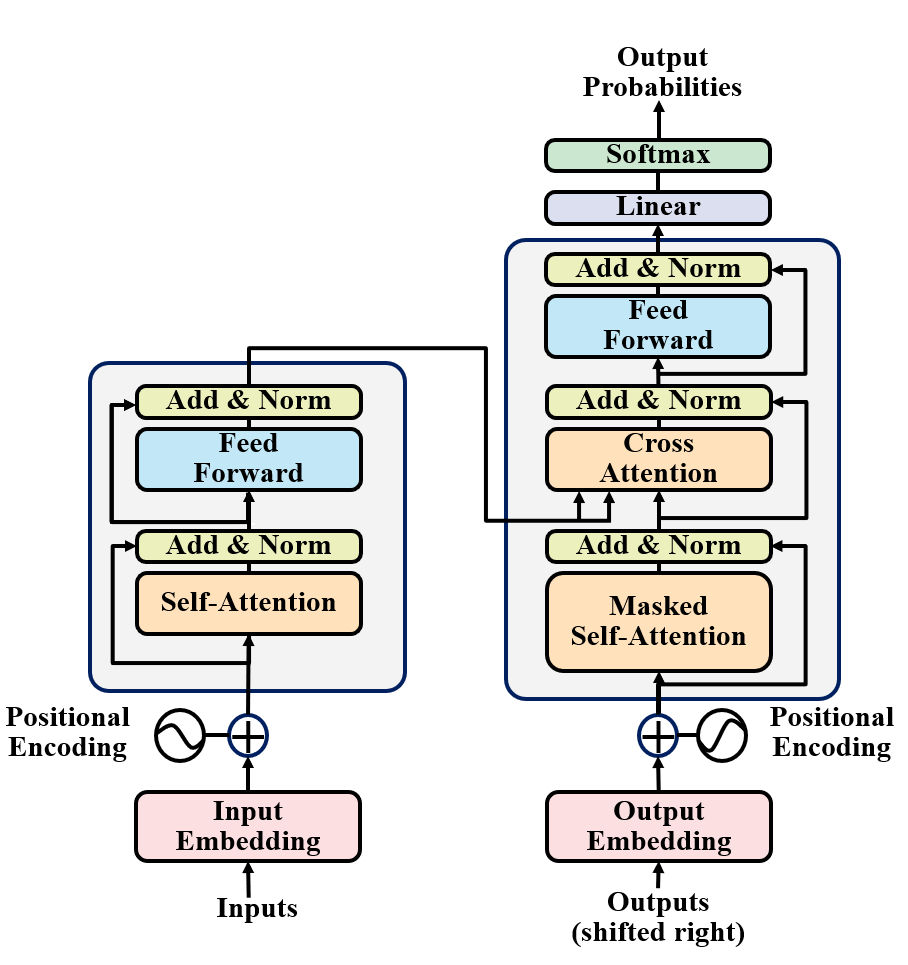
Transformer整体结构
最后,简要提及一下Decoder部分的Softmax层。
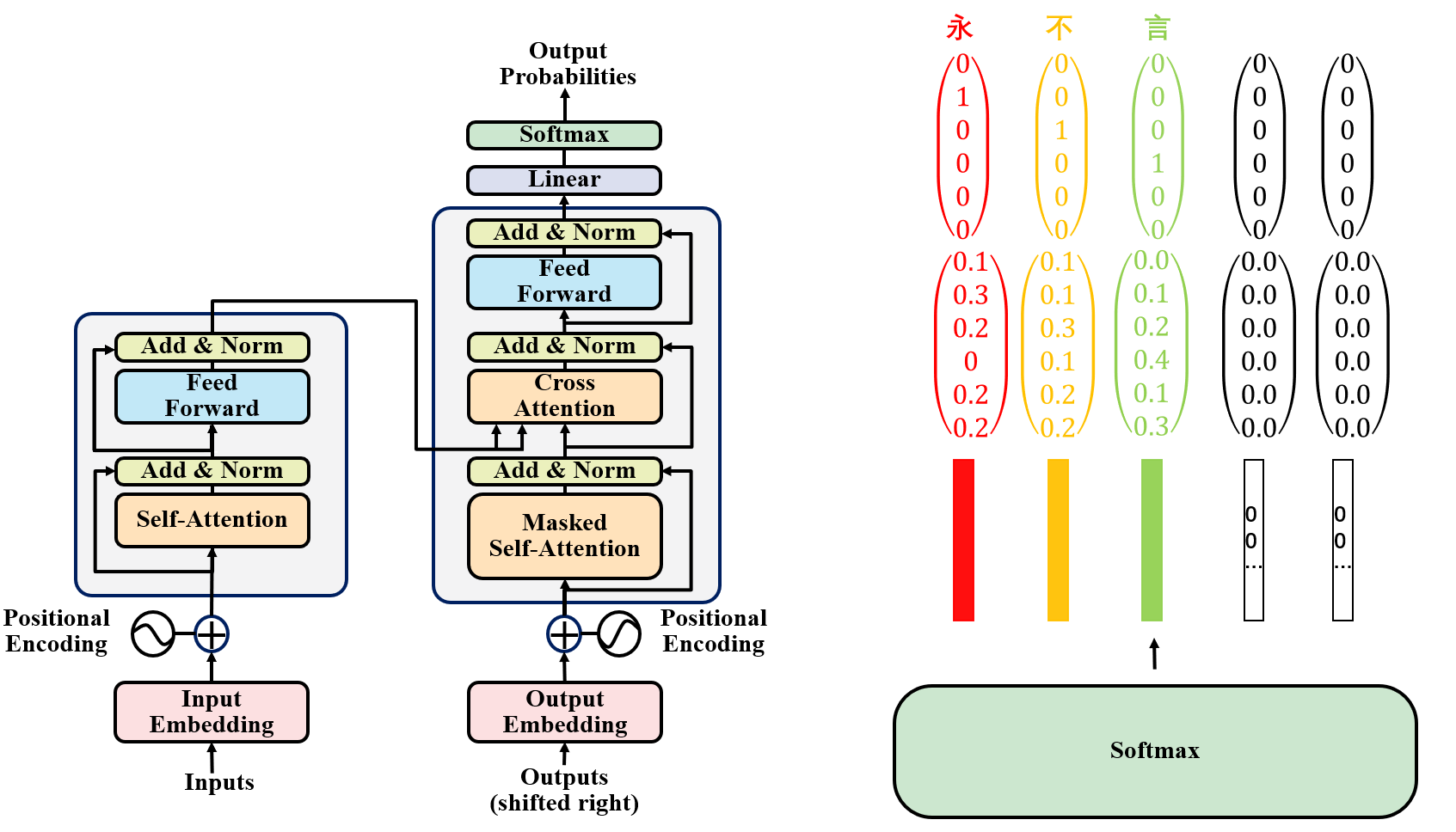
Softmax层的输出是一系列概率向量,再经过如argmax函数的处理,可以得到类似于one-hot的编码向量,从而得到最终的预测结果,再依次类推,自回归,翻译完全文。
以上就是Transformer的全部内容。
在此特别感谢b站的up主:【Attention、Transformer公式推导和矩阵变化】 https://www.bilibili.com/video/BV1q3411U7Hi/?share_source=copy_web&vd_source=54a003f2fe57290ef9f347426cdb53c9
【Transformer论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1pu411o7BE/?share_source=copy_web&vd_source=54a003f2fe57290ef9f347426cdb53c9
















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











