







slearn model evaluation:quantifying the quality of predictions
3个办法:
1)estimator score method
2)scoring parameters :using cross-validation
cross-validation大概的意思是:对于原始数据我们要将其一部分分为train data,一部分分为test data。train data用于训练,test data用于测试准确率。在test data上测试的结果叫做validation error。将一个算法作用于一个原始数据,我们不可能只做出随机的划分一次train和test data,然后得到一个validation error,就作为衡量这个算法好坏的标准。因为这样存在偶然性。我们必须好多次的随机的划分train data和test data,分别在其上面算出各自的validation error。这样就有一组validation error,根据这一组validation error,就可以较好的准确的衡量算法的好坏。
最主要的函数是如下函数:**sklearn.cross_validation.cross_val_score**。他的调用形式是scores = cross_validation.cross_val_score(clf, raw data, raw target, cv=5, score_func=None)
还有一个比较有用的函数是**train_test_split**。。。功能:从样本中随机的按比例选取train data和test data。调用形式为:X_train, X_test, y_train, y_test = cross_validation.train_test_split(train_data, train_target, test_size=0.4, random_state=0)。test_size是样本占比。如果是整数的话就是样本的数量。random_state是随机数的种子。不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
3)metric functions:
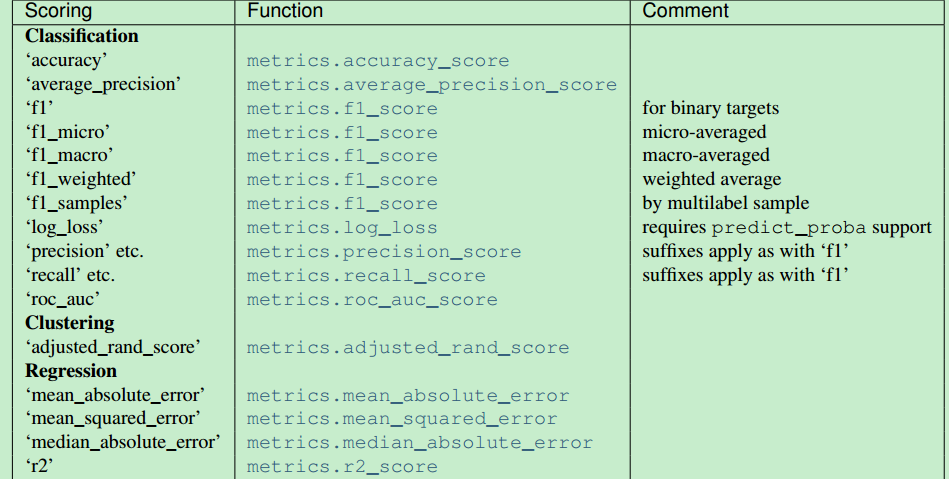
metrics 主要函数:
1、precision_recall_curve 含义:the precision is intuitively the ability of the classifier not to label as positive a sample that is negative. the recall is intuitively the ability of the classifier to find all the positive samples.
2、classification_report 含义:build a text report showing the main classification metrics 调用方式 :print(classification_report(y_true,y_pred,target_names=target_names))















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









