








 超级会员免费看
超级会员免费看

 本文详细介绍了KMeans算法的学习过程,包括实验目的、原理、环境配置,以及模型创建、使用和评价的步骤。通过Python实现,讨论了KMeans的聚类过程和不同距离公式,并提供了数据读取、规整化处理和模型预测的实例。
本文详细介绍了KMeans算法的学习过程,包括实验目的、原理、环境配置,以及模型创建、使用和评价的步骤。通过Python实现,讨论了KMeans的聚类过程和不同距离公式,并提供了数据读取、规整化处理和模型预测的实例。
机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
文章目录
一、实验目的
学习sklearn模块中的KMeans算法
二、实验原理
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为

2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
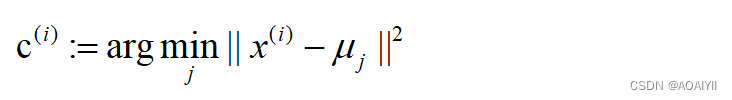
对于每一个类j,重新计算该类的质心
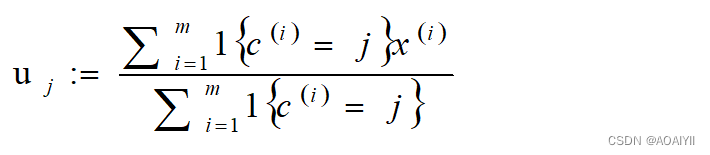
K是我们事先给定的聚类数,c(i)代表样例i与k个类中距离最近的那个类,c(i)的值是1到k中的一个。质心uj代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为c(i),这样经过第一步每一个星星都有了所

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











