






今天给大家介绍一个强大的算法模型,Transformer
Transformer 模型是由 Vaswani 等人在 2017 年提出的一种用于自然语言处理的深度学习模型,特别擅长于处理序列到序列的任务,如机器翻译、文本生成等。
今天,我们主要从编码的角度来进行说明。
Transformer 模型架构
Transformer 模型由编码器(Encoder)和解码器(Decoder)两部分组成,每部分包含多个相同的层 (Layer) 堆叠而成。
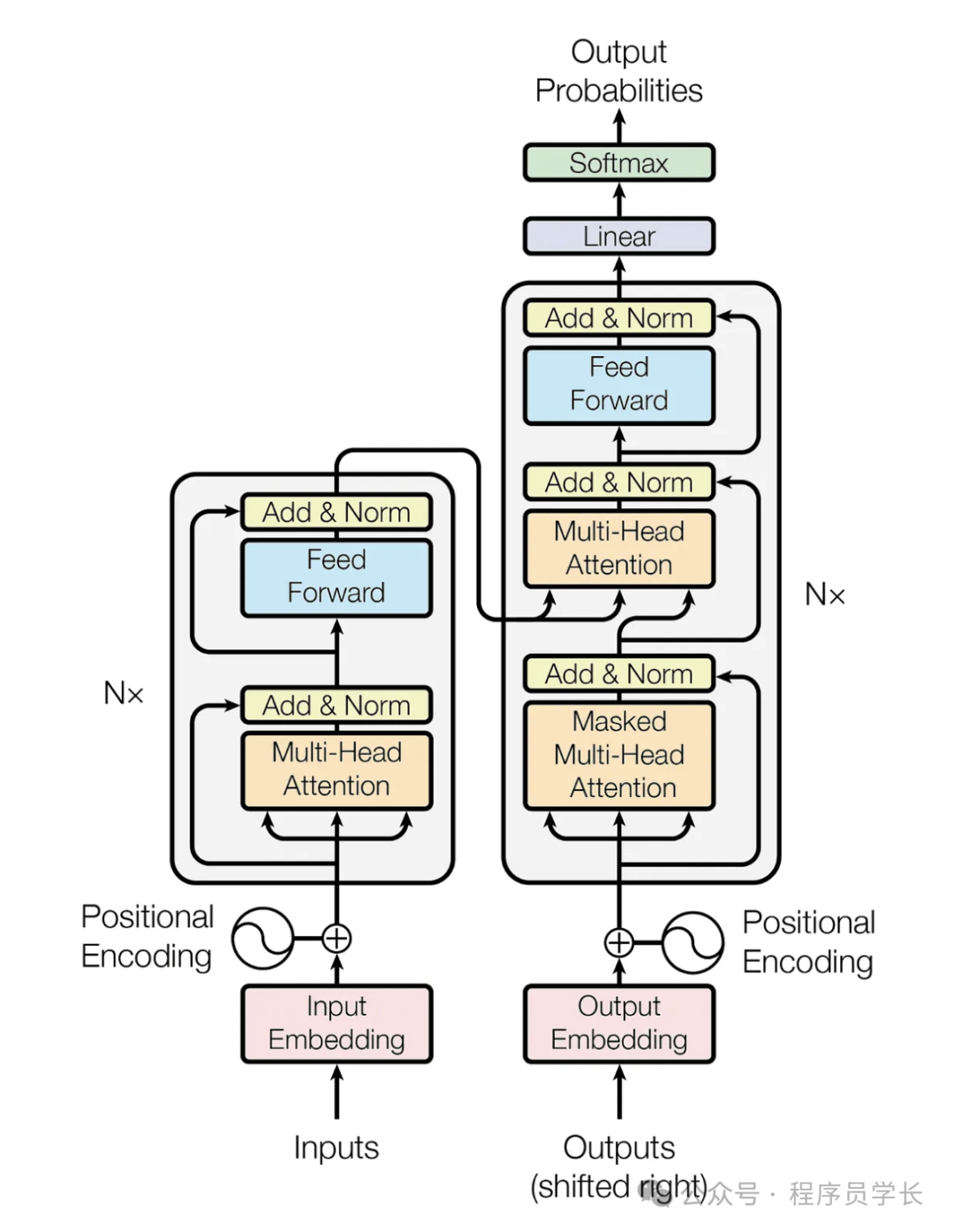
编码器
编码器由 N 个相同的层组成,每个层包括以下两个子层:
-
多头自注意力机制(Multi-Head Self-Attention Mechanism)
-
前馈神经网络(Feed-Forward Neural Network)
每个子层都采用残差连接 (Residual Connection) 和层归一化 (Layer Normalization)。
解码器
解码器也由 N 个相同的层组成,每个层包括以下三个子层:
-
多头自注意力机制(Masked Multi-Head Self-Attention Mechanism)
-
编码器-解码器注意力机制(Encoder-Decoder Attention Mechanism)
-
前馈神经网络(Feed-Forward Neural Network)
同样,每个子层都采用残差连接和层归一化。
Transformer 模型的主要组件
-
Token Embedding
将输入的离散单词转换为连续的向量表示。
-
位置编码
在输入序列中引入位置信息,因为 Transformer 本身没有顺序依赖,需要位置编码来帮助模型识别序列的顺序。
-
多头自注意力
计算 token 之间的注意力分数,使模型能够关注序列中的不同位置,从而捕捉全局信息。
-
前馈层
对每个位置的表示进行独立的线性变换和激活函数,以增强模型的表达能力。
-
编码器-解码器注意力机制
解码器中的每个位置可以关注编码器中的所有位置,从而将编码器的信息传递给解码器。
-
残差连接
在每个子层(子模块)的输入和输出之间添加一个快捷连接(skip connection),以避免梯度消失和梯度爆炸问题,使得训练更稳定。
代码演练
首先,我们导入必要的库
import numpy as np
import torch
import math
from torch import nn
import torch.nn.functional as F
嵌入将单词转换为 Embedding
class Embeddings(nn.Module):
def __init__(self, vocab_size, d_model):
super(Embeddings, self).__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.d_model = d_model
def forward(self, x):
return self.embed(x) * math.sqrt(self.d_model)
位置编码添加了有关序列顺序的信息。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_sequence_length):
super().__init__()
self.max_sequence_length = max_sequence_length
self.d_model = d_model
def forward(self, x):
even_i = torch.arange(0, self.d_model, 2).float()
denominator = torch.pow(10000, even_i/self.d_model)
position = (torch.arange(self.max_sequence_length)
.reshape(self.max_sequence_length, 1))
even_PE = torch.sin(position / denominator)
odd_PE = torch.cos(position / denominator)
stacked = torch.stack([even_PE, odd_PE], dim=2)
PE = torch.flatten(stacked, start_dim=1, end_dim=2)
return PE
多头自注意力层
def scaled_dot_product(q, k, v, mask=None):
d_k = q.size()[-1]
scaled = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k)
if mask is not None:
scaled = scaled.permute(1, 0, 2, 3) + mask
scaled = scaled.permute(1, 0, 2, 3)
attention = F.softmax(scaled, dim=-1)
values = torch.matmul(attention, v)
return values, attention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.qkv_layer = nn.Linear(d_model , 3 * d_model)
self.linear_layer = nn.Linear(d_model, d_model)
def forward(self, x, mask):
batch_size, sequence_length, d_model = x.size()
qkv = self.qkv_layer(x)
qkv = qkv.reshape(batch_size, sequence_length, self.num_heads, 3 * self.head_dim)
qkv = qkv.permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=-1)
values, attention = scaled_dot_product(q, k, v, mask)
values = values.permute(0, 2, 1, 3).reshape(batch_size, sequence_length, self.num_heads * self.head_dim)
out = self.linear_layer(values)
return out
前馈层使用 ReLu 激活函数和线性层。
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
层规范化
class LayerNormalization(nn.Module):
def __init__(self, parameters_shape, eps=1e-5):
super().__init__()
self.parameters_shape=parameters_shape
self.eps=eps
self.gamma = nn.Parameter(torch.ones(parameters_shape))
self.beta = nn.Parameter(torch.zeros(parameters_shape))
def forward(self, inputs):
dims = [-(i + 1) for i in range(len(self.parameters_shape))]
mean = inputs.mean(dim=dims, keepdim=True)
var = ((inputs - mean) ** 2).mean(dim=dims, keepdim=True)
std = (var + self.eps).sqrt()
y = (inputs - mean) / std
out = self.gamma * y + self.beta
return out
编码器由多个编码器层组成。
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, num_heads, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
self.norm1 = LayerNormalization(parameters_shape=[d_model])
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNormalization(parameters_shape=[d_model])
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, self_attention_mask):
residual_x = x.clone()
x = self.attention(x, mask=self_attention_mask)
x = self.dropout1(x)
x = self.norm1(x + residual_x)
residual_x = x.clone()
x = self.ffn(x)
x = self.dropout2(x)
x = self.norm2(x + residual_x)
return x
class SequentialEncoder(nn.Sequential):
def forward(self, *inputs):
x, self_attention_mask = inputs
for module in self._modules.values():
x = module(x, self_attention_mask)
return x
class Encoder(nn.Module):
def __init__(self,
d_model,
ffn_hidden,
num_heads,
drop_prob,
num_layers,
max_sequence_length,
language_to_index,
START_TOKEN,
END_TOKEN,
PADDING_TOKEN):
super().__init__()
self.sentence_embedding = SentenceEmbedding(max_sequence_length, d_model, language_to_index, START_TOKEN, END_TOKEN, PADDING_TOKEN)
self.layers = SequentialEncoder(*[EncoderLayer(d_model, ffn_hidden, num_heads, drop_prob)
for _ in range(num_layers)])
def forward(self, x, self_attention_mask, start_token, end_token):
x = self.sentence_embedding(x, start_token, end_token)
x = self.layers(x, self_attention_mask)
return x
多头交叉注意层
class MultiHeadCrossAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.kv_layer = nn.Linear(d_model , 2 * d_model)
self.q_layer = nn.Linear(d_model , d_model)
self.linear_layer = nn.Linear(d_model, d_model)
def forward(self, x, y, mask):
batch_size, sequence_length, d_model = x.size()
kv = self.kv_layer(x)
q = self.q_layer(y)
kv = kv.reshape(batch_size, sequence_length, self.num_heads, 2 * self.head_dim)
q = q.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
kv = kv.permute(0, 2, 1, 3)
q = q.permute(0, 2, 1, 3)
k, v = kv.chunk(2, dim=-1)
values, attention = scaled_dot_product(q, k, v, mask)
values = values.permute(0, 2, 1, 3).reshape(batch_size, sequence_length, d_model)
out = self.linear_layer(values)
return out
解码器由多个解码器层组成
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, num_heads, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
self.layer_norm1 = LayerNormalization(parameters_shape=[d_model])
self.dropout1 = nn.Dropout(p=drop_prob)
self.encoder_decoder_attention = MultiHeadCrossAttention(d_model=d_model, num_heads=num_heads)
self.layer_norm2 = LayerNormalization(parameters_shape=[d_model])
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.layer_norm3 = LayerNormalization(parameters_shape=[d_model])
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, x, y, self_attention_mask, cross_attention_mask):
_y = y.clone()
y = self.self_attention(y, mask=self_attention_mask)
y = self.dropout1(y)
y = self.layer_norm1(y + _y)
_y = y.clone()
y = self.encoder_decoder_attention(x, y, mask=cross_attention_mask)
y = self.dropout2(y)
y = self.layer_norm2(y + _y)
_y = y.clone()
y = self.ffn(y)
y = self.dropout3(y)
y = self.layer_norm3(y + _y)
return y
class SequentialDecoder(nn.Sequential):
def forward(self, *inputs):
x, y, self_attention_mask, cross_attention_mask = inputs
for module in self._modules.values():
y = module(x, y, self_attention_mask, cross_attention_mask)
return y
class Decoder(nn.Module):
def __init__(self,
d_model,
ffn_hidden,
num_heads,
drop_prob,
num_layers,
max_sequence_length,
language_to_index,
START_TOKEN,
END_TOKEN,
PADDING_TOKEN):
super().__init__()
self.sentence_embedding = SentenceEmbedding(max_sequence_length, d_model, language_to_index, START_TOKEN, END_TOKEN, PADDING_TOKEN)
self.layers = SequentialDecoder(*[DecoderLayer(d_model, ffn_hidden, num_heads, drop_prob) for _ in range(num_layers)])
def forward(self, x, y, self_attention_mask, cross_attention_mask, start_token, end_token):
y = self.sentence_embedding(y, start_token, end_token)
y = self.layers(x, y, self_attention_mask, cross_attention_mask)
return y
transformer 模型
class Transformer(nn.Module):
def __init__(self,
d_model,
ffn_hidden,
num_heads,
drop_prob,
num_layers,
max_sequence_length,
spn_vocab_size,
english_to_index,
spanish_to_index,
START_TOKEN,
END_TOKEN,
PADDING_TOKEN
):
super().__init__()
self.encoder = Encoder(d_model, ffn_hidden, num_heads, drop_prob, num_layers, max_sequence_length, english_to_ind, START_TOKEN, END_TOKEN, PADDING_TOKEN)
self.decoder = Decoder(d_model, ffn_hidden, num_heads, drop_prob,num_layers, max_sequence_length, spanish_to_ind, START_TOKEN, END_TOKEN, PADDING_TOKEN)
self.linear = nn.Linear(d_model, spn_vocab_size)
self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
def forward(self,
x,
y,
encoder_self_attention_mask=None,
decoder_self_attention_mask=None,
decoder_cross_attention_mask=None,
enc_start_token=False,
enc_end_token=False,
dec_start_token=False, # We should make this true
dec_end_token=False): # x, y are batch of sentences
x = self.encoder(x, encoder_self_attention_mask, start_token=enc_start_token, end_token=enc_end_token)
out = self.decoder(x, y, decoder_self_attention_mask, decoder_cross_attention_mask, start_token=dec_start_token, end_token=dec_end_token)
out = self.linear(out)
return out
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 40万+
40万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









