







1.算法简介
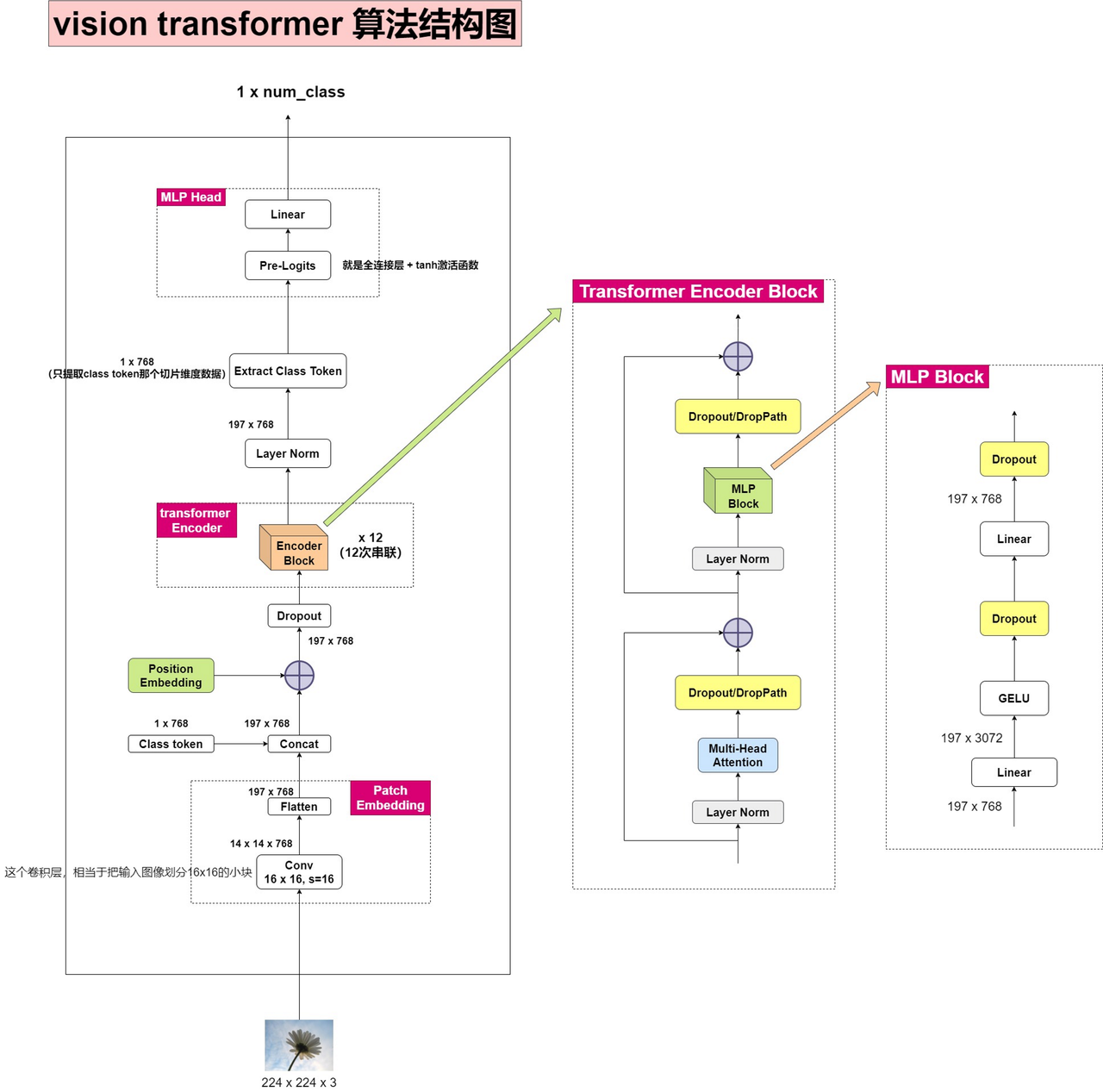
本文主要对VIT算法原理进行简单梳理,下图是一个大佬整理的网络整体的流程图,清晰明了,其实再了解自注意力机制和多头自注意力机制后,再看VIT就很简单了
受到NLP领域中Transformer成功应用的启发,ViT算法尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法将整幅图像拆分成小图像块,将图像块转换为类似于NLP中的Sequence后再执行TransFormer操作。
参考链接:一文带你掌(放)握(弃)ViT(Vision Transformer)(原理解读+实践代码)
参考链接:Vision Transformer (ViT):图像分块、图像块嵌入、类别标记、QKV矩阵与自注意力机制的解析
参考链接:ViT(vision transformer)原理快速入门
参考链接:逐步解析Vision Transformer各细节
2.图像分块和Embedding
这一步是为了后面的TransFormer操作对数据进行预处理,将图像转换为Sequence的形式。
2.1原理简介
(1)如图所示,输入图像为224*224*3的图像,将其分割为大小等于16*16的图像块,图像块数量为224*224/16*16=196。

(2)图像分块后再将其展平为一个序列,序列的shape为:196*16*16*3

(3)为了实现最后的分类任务,需要添加一个Class Token的信息(图中橙色部分),则输入序列变为197*16*16*3

(4)生成特定通道的sequence
经过上述步骤处理后,每个图像块的维度是 16 ∗ 16 ∗ 3 16*16*3 16∗16∗3,而我们实际需要的向量维度是D,因此我们还需要对图像块进行 Embedding。这里 Embedding的方式非常简单,只需要对每个 16 ∗ 16 ∗ 3 16*16*3 16∗
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









