






首先,官话: Transformer 模型是由 Vaswani 等人在 2017 年提出的一种新型神经网络架构,用于解决序列到序列的任务,比如机器翻译、文本生成等。它的核心思想是通过「注意力机制」来捕捉序列中的依赖关系,而不依赖传统的循环神经网络(RNN)。
其次,这是重点(划重点): 给大家用一个很简单的方式来解释Transformer。
Transformer 是一种不依赖于顺序处理序列数据的新型模型,它利用注意力机制在处理每个词时关注整个序列中的其他词,从而捕捉全局的依赖关系。这使得它在处理长序列时比传统的循环神经网络更有效、更快速。
举一个例子,句子翻译:
假设我们要把英文句子 “I am a student” 翻译成中文 “我是学生”。下面是如何一步一步进行的。
1. 输入序列
输入序列是英文句子 “I am a student”。我们将这个句子送入模型。
2. 编码器处理
编码器的任务是理解输入的英文句子。我们可以把它想象成一个特别聪明的阅读员。
-
第一步:词向量表示:
-
每个词 “I”、“am”、“a” 和 “student” 都会被转换成一个向量(一个包含数字的列表),这些向量代表了词的意义。
-
第二步:自注意力机制:
-
编码器会看整个句子,计算每个词和其他词之间的关系。
-
比如,它会理解 “I” 和 “am” 是紧密相关的,“student” 和 “a” 也是相关的。
-
第三步:多层处理:
-
编码器由多层组成,每层都会重复上面的自注意力机制,然后更新每个词的向量表示。
-
经过多层处理,编码器对每个词的理解会越来越深刻,最后得到一组新的词向量,这些向量包含了整个句子的上下文信息。
3. 解码器生成
解码器的任务是生成翻译后的中文句子。可以把它想象成一个翻译员。
-
第一步:生成第一个词:
-
解码器先看编码器的输出(即英文句子的向量表示),然后生成第一个中文词,比如 “我”。
-
解码器会用一个特殊的开始标记来启动翻译过程。
-
第二步:结合已生成的词和编码器的输出:
-
解码器不仅看编码器的输出,还会结合已经生成的中文词。
-
假设我们已经生成了 “我”,解码器会结合 “我” 和编码器的输出,决定下一个词是什么。
-
第三步:自注意力机制和交互注意力机制:
-
解码器也有自己的自注意力机制,用来理解已生成词之间的关系,比如 “我” 和 “是” 的关系。
-
同时,解码器还会使用交互注意力机制,结合编码器的输出,理解英文句子和已生成的中文词的关系。
-
第四步:逐词生成:
-
逐步生成下一个词,比如生成 “是” 后,解码器结合 “我”、“是” 和编码器的输出,再生成 “学生”。
-
最终,解码器生成完整的中文句子 “我是学生”。
主要构件
到这里,大家应该已经有了一个初步的理解了。
上面提到了编码器(Encoder) 和 解码器(Decoder),是 Transformer 两个主要部分。每个部分又包含多个相同的层。
下面的解释,大家应该是很容易理解了:
1. 编码器(Encoder):
-
负责读取输入序列并生成特征表示。
-
每层编码器包含两个子层:
-
多头自注意力机制(Multi-Head Self-Attention):关注输入序列中不同位置的依赖关系。
-
前馈神经网络(Feed-Forward Neural Network):对每个位置的特征进行独立处理。
2. 解码器(Decoder):
-
根据编码器的输出和前面的解码器输出,生成最终序列。
-
每层解码器包含三个子层:
-
多头自注意力机制:关注解码器中之前位置的依赖关系。
-
编码器-解码器注意力机制:结合编码器的输出与当前解码器的输入。
-
前馈神经网络:对每个位置的特征进行独立处理。
注意力机制
注意力机制是 Transformer 的核心,它允许模型在处理当前词语时「关注」输入序列中与其相关的其他词语,从而捕捉更全局的依赖关系。自注意力机制通过计算每个词与其他词的「相关性」(也叫注意力分数),然后对这些相关性进行加权求和,从而得到每个词的新表示。
原理详解
好的,我们将更详细地探讨Transformer模型的每一部分,包括自注意力机制、多头注意力机制、位置编码、编码器和解码器的结构以及具体的公式推导。
1. 自注意力机制(Self-Attention Mechanism)
计算注意力分数
自注意力机制的核心在于计算序列中每个元素与其他元素的关系,这通过以下步骤完成:
1. 线性变换生成查询、键和值矩阵:
对于输入序列 (形状为 ),通过线性变换得到查询矩阵 、键矩阵 和值矩阵 :
其中 是可学习的参数矩阵,形状均为 。
2. 计算注意力分数:
注意力分数是通过点积计算得到的:
这里的 是一个缩放因子,防止点积值过大导致softmax的梯度消失。
3. 应用softmax函数:
对注意力分数应用softmax函数,得到注意力权重:
4. 计算加权和:
最后,用注意力权重对值矩阵 进行加权求和,得到最终的输出:
2. 多头注意力机制(Multi-Head Attention)
多头注意力机制允许模型关注不同位置的信息子空间,通过并行计算多个注意力头,并将它们的输出结合在一起:
1. 并行计算多个注意力头:
对输入序列 进行 次自注意力计算,每次计算使用不同的线性变换参数:
2. 连接注意力头的输出:
将 个注意力头的输出连接起来:
3. 线性变换多头输出:
对连接后的输出进行线性变换,得到最终的多头注意力输出:
3. 位置编码(Positional Encoding)
由于Transformer没有内置的序列顺序信息,必须通过位置编码来引入位置信息。位置编码通常通过正弦和余弦函数生成:
其中 是序列中的位置, 是维度索引。
4. 编码器(Encoder)
编码器由多层堆叠的自注意力层和前馈神经网络层组成。
自注意力层
每一层的自注意力机制如上所述,计算如下:
前馈神经网络层
前馈神经网络层包括两个线性变换和一个激活函数(如ReLU):
5. 解码器(Decoder)
解码器结构与编码器类似,但多了一个编码-解码注意力层。
自注意力层
与编码器的自注意力层相同。
编码-解码注意力层
这个层的计算考虑到了编码器的输出:
这里的 和 来自编码器的输出, 来自解码器的输入。
前馈神经网络层
与编码器中的前馈神经网络层相同。
6. 训练与优化
Transformer模型通常通过以下损失函数和优化方法进行训练:
-
损失函数: 交叉熵损失函数(Cross-Entropy Loss)用于计算预测序列与目标序列之间的误差。
-
优化方法: 常用Adam优化器,并结合学习率调度策略(如学习率预热和衰减)。
7. 公式总结
这里,再给大家总结一下~
1. 自注意力:
2. 多头注意力:
3. 位置编码:
4. 前馈神经网络:
通过这些公式和结构,Transformer模型能够高效地处理序列数据,并捕捉长距离依赖关系,极大地提升了自然语言处理任务的性能。
完整案例
这里,咱们完成一个 利用Transformer进行机器翻译 的简易项目。
数据集介绍
我们将使用一个简单的中英文平行语料库来训练Transformer模型。这些数据可以从公开的多语言数据集(如Tatoeba项目)中获取。
示例数据:
中文: 你好吗? 英文: How are you?
算法流程
1. 数据预处理:
-
分词、标记化、构建词汇表。
-
转换成模型输入格式。
2. 模型构建:
- 使用Transformer架构,包括编码器和解码器。
3. 训练模型:
-
定义损失函数和优化器。
-
训练模型,监控损失。
4. 模型评估:
-
使用验证集评估模型性能。
-
绘制训练损失和验证损失曲线。
5. 翻译句子:
- 使用训练好的模型翻译新句子。
完整代码
使用TensorFlow和Keras来实现Transformer进行机器翻译。
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np # 数据预处理 # 示例数据 data = [ ("你好", "Hello"), ("你好吗?", "How are you?"), ("谢谢", "Thank you"), ("再见", "Goodbye"), ] def preprocess_sentence(sentence): sentence = sentence.lower().strip() sentence = " ".join(sentence) return sentence input_texts = [] target_texts = [] for src, tgt in data: input_texts.append(preprocess_sentence(src)) target_texts.append('<start> ' + preprocess_sentence(tgt) + ' <end>') # 构建词汇表 input_vocab = sorted(set("".join(input_texts))) target_vocab = sorted(set(" ".join(target_texts).split(" "))) input_vocab_size = len(input_vocab) + 1 target_vocab_size = len(target_vocab) + 1 input_token_index = dict([(char, i + 1) for i, char in enumerate(input_vocab)]) target_token_index = dict([(word, i + 1) for i, word in enumerate(target_vocab)]) max_encoder_seq_length = max([len(txt) for txt in input_texts]) max_decoder_seq_length = max([len(txt.split(" ")) for txt in target_texts]) encoder_input_data = np.zeros((len(input_texts), max_encoder_seq_length), dtype="float32") decoder_input_data = np.zeros((len(input_texts), max_decoder_seq_length), dtype="float32") decoder_target_data = np.zeros((len(input_texts), max_decoder_seq_length, target_vocab_size), dtype="float32") for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)): for t, char in enumerate(input_text): encoder_input_data[i, t] = input_token_index[char] for t, word in enumerate(target_text.split(" ")): decoder_input_data[i, t] = target_token_index[word] if t > 0: decoder_target_data[i, t - 1, target_token_index[word]] = 1.0 # 构建Transformer模型 from tensorflow.keras.layers import Input, Embedding, LSTM, Dense from tensorflow.keras.models import Model # 定义编码器 encoder_inputs = Input(shape=(None,)) encoder_embedding = Embedding(input_vocab_size, 256)(encoder_inputs) encoder_lstm = LSTM(256, return_state=True) encoder_outputs, state_h, state_c = encoder_lstm(encoder_embedding) encoder_states = [state_h, state_c] # 定义解码器 decoder_inputs = Input(shape=(None,)) decoder_embedding = Embedding(target_vocab_size, 256)(decoder_inputs) decoder_lstm = LSTM(256, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states) decoder_dense = Dense(target_vocab_size, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs) # 定义模型 model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # 编译模型 model.compile(optimizer='rmsprop', loss='categorical_crossentropy') # 训练模型 history = model.fit( [encoder_input_data, decoder_input_data], decoder_target_data, batch_size=64, epochs=100, validation_split=0.2 ) # 绘制训练损失和验证损失曲线 plt.plot(history.history['loss'], label='Train Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.legend() plt.show() # 翻译新句子 def decode_sequence(input_seq): states_value = encoder_model.predict(input_seq) target_seq = np.zeros((1, 1)) target_seq[0, 0] = target_token_index['<start>'] stop_condition = False decoded_sentence = '' while not stop_condition: output_tokens, h, c = decoder_model.predict([target_seq] + states_value) sampled_token_index = np.argmax(output_tokens[0, -1, :]) sampled_word = target_vocab[sampled_token_index - 1] decoded_sentence += ' ' + sampled_word if (sampled_word == '<end>' or len(decoded_sentence.split(" ")) > max_decoder_seq_length): stop_condition = True target_seq = np.zeros((1, 1)) target_seq[0, 0] = sampled_token_index states_value = [h, c] return decoded_sentence # 构建编码器和解码器模型 encoder_model = Model(encoder_inputs, encoder_states) decoder_state_input_h = Input(shape=(256,)) decoder_state_input_c = Input(shape=(256,)) decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c] decoder_outputs, state_h, state_c = decoder_lstm( decoder_embedding, initial_state=decoder_states_inputs) decoder_states = [state_h, state_c] decoder_outputs = decoder_dense(decoder_outputs) decoder_model = Model( [decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states) # 测试翻译 for seq_index in range(len(input_texts)): input_seq = encoder_input_data[seq_index: seq_index + 1] decoded_sentence = decode_sequence(input_seq) print('-') print('Input sentence:', input_texts[seq_index]) print('Decoded sentence:', decoded_sentence)
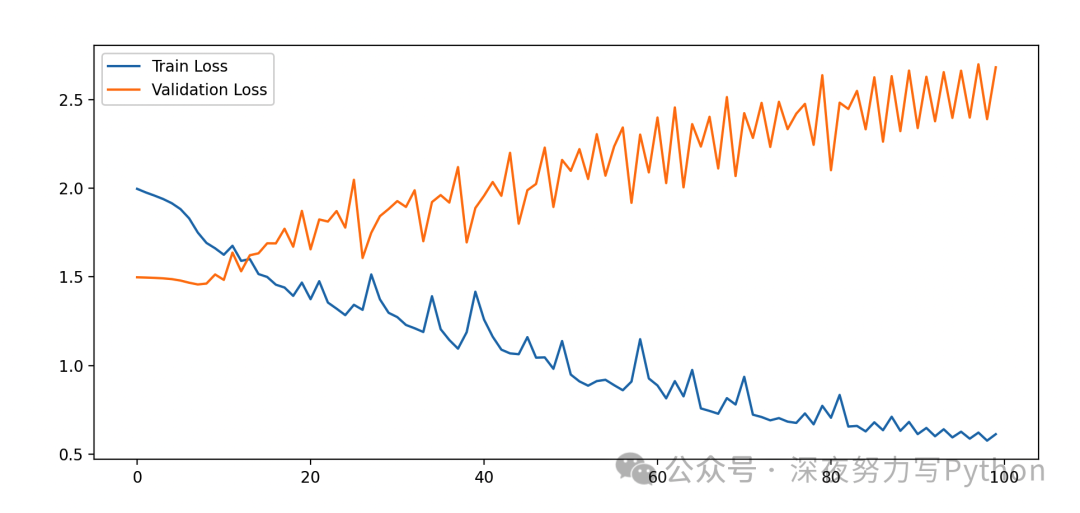
整个代码,大家可以根据注释读懂。
算法优化点
1. 增加数据量:使用更大规模的平行语料库,提高模型的泛化能力。
2. 调整模型架构:增加Transformer层数、调整每层的隐藏单元数量。使用多头注意力机制增强模型性能。
3. 超参数调整:调整学习率、batch size等超参数,使用网格搜索或贝叶斯优化。
4. 正则化技术:使用dropout、L2正则化等方法防止过拟合。
5. 优化训练过程:使用更高级的优化器(如Adam)。增加训练轮数,使用学习率衰减策略。
6. 数据增强:使用数据增强技术,如回译(back-translation)等,增强训练数据的多样性。
通过这些优化,可以进一步提高Transformer模型的机器翻译性能。
最后
以上,整个是一个完整的LSTM时间序列预测的案例,包括数据预处理、模型构建、训练、评估和可视化。大家在自己实际的实验中,根据需求进行进一步的调整和优化。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









