







Course3_UnsupervisedLearning
Week 1
K-means clustering
cluster centroids
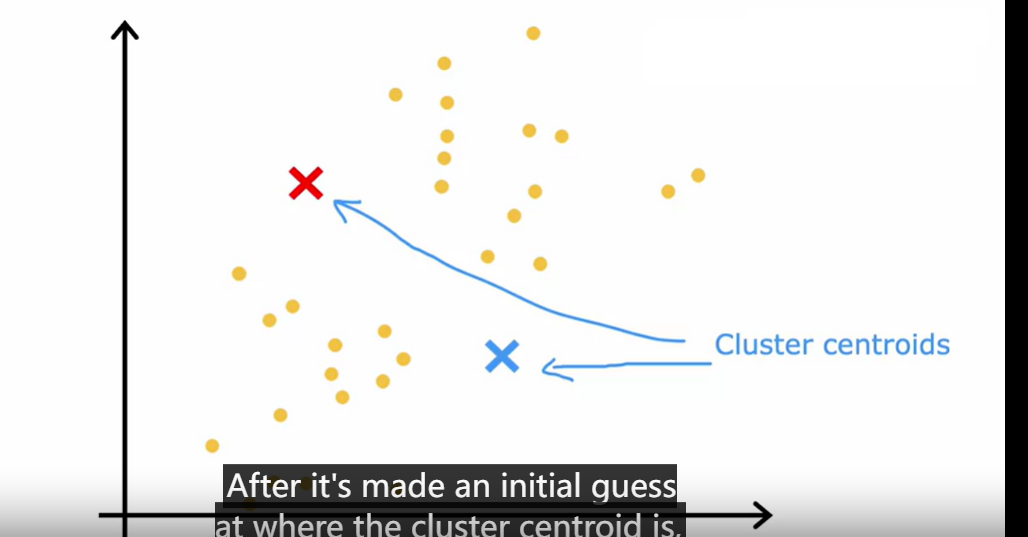
K-means alogrithm

K-means optimization objective


random initialization

elbow method
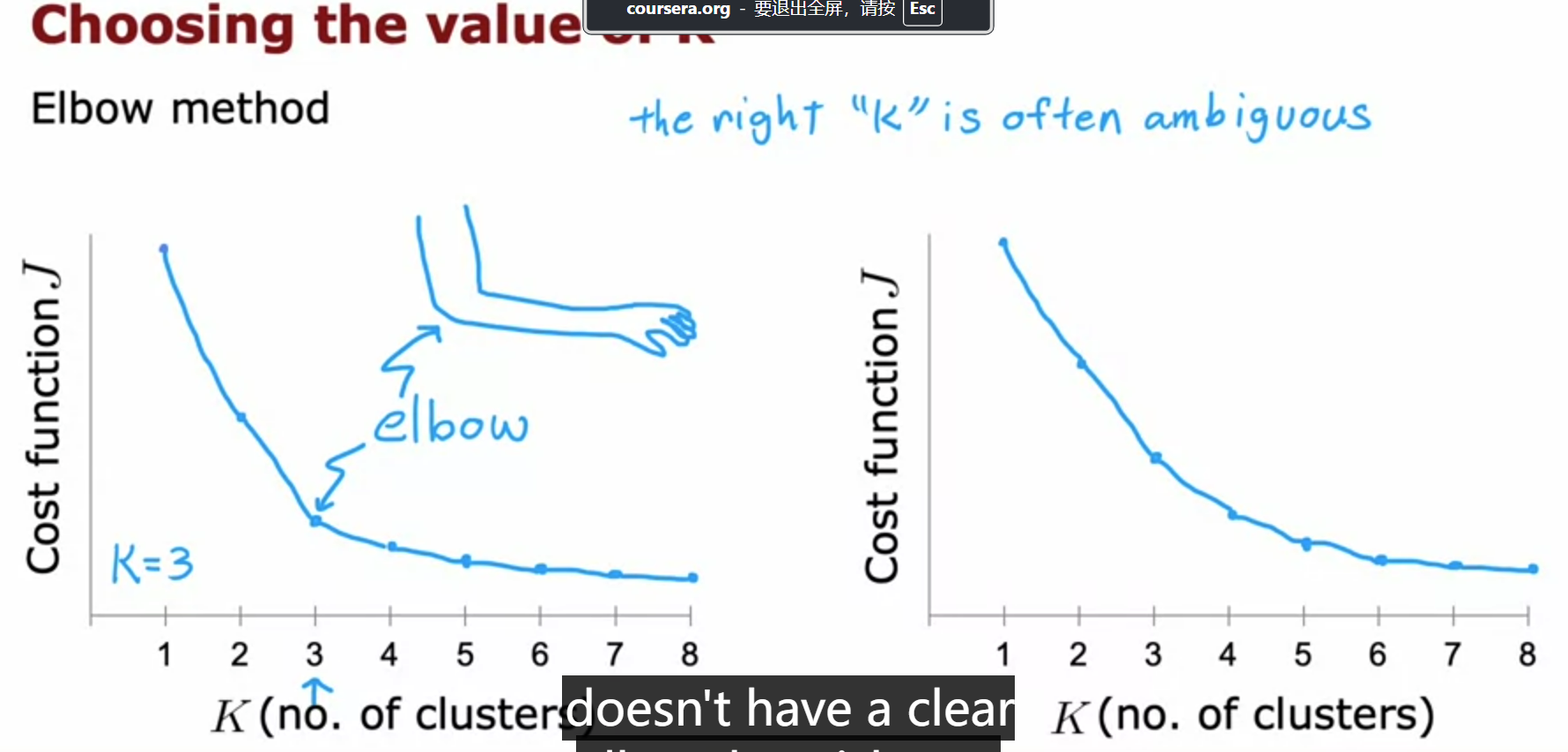
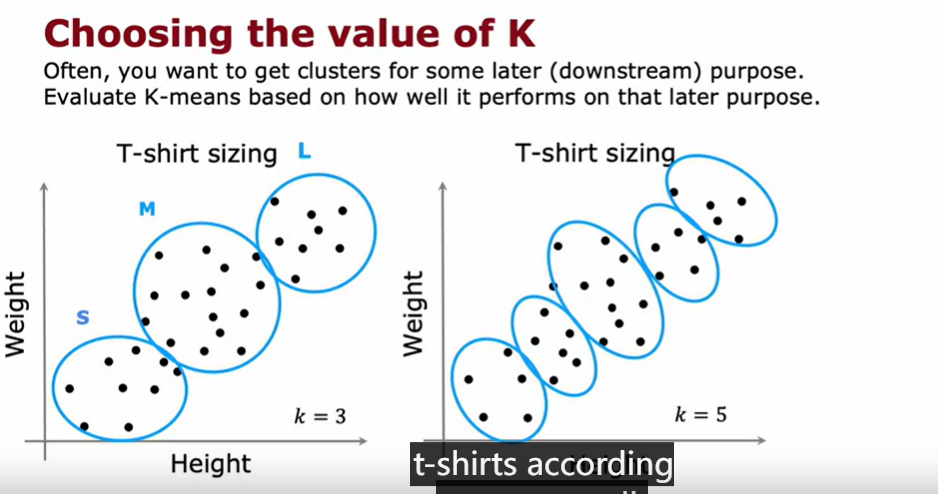
How to choose the value of K
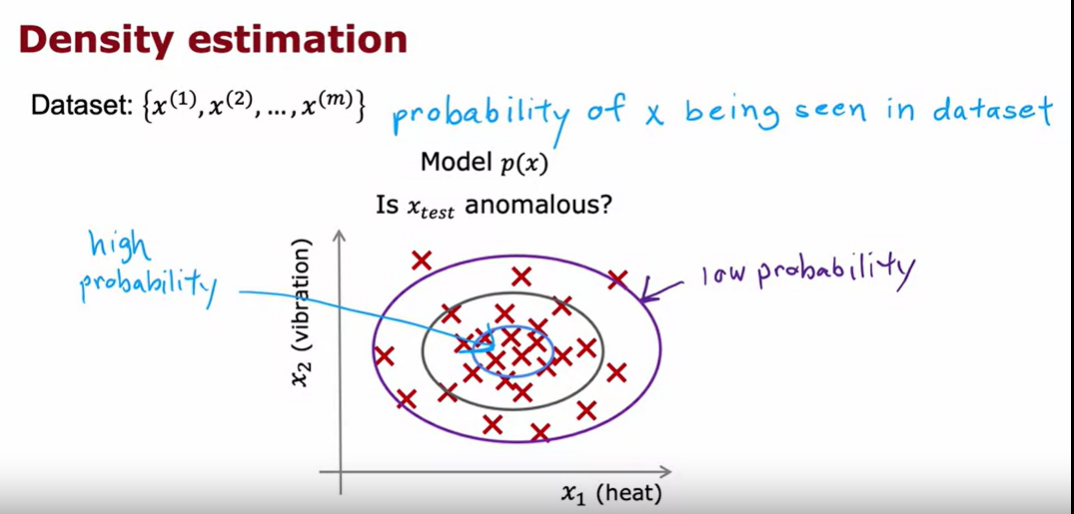
anomaly detection
density estimation
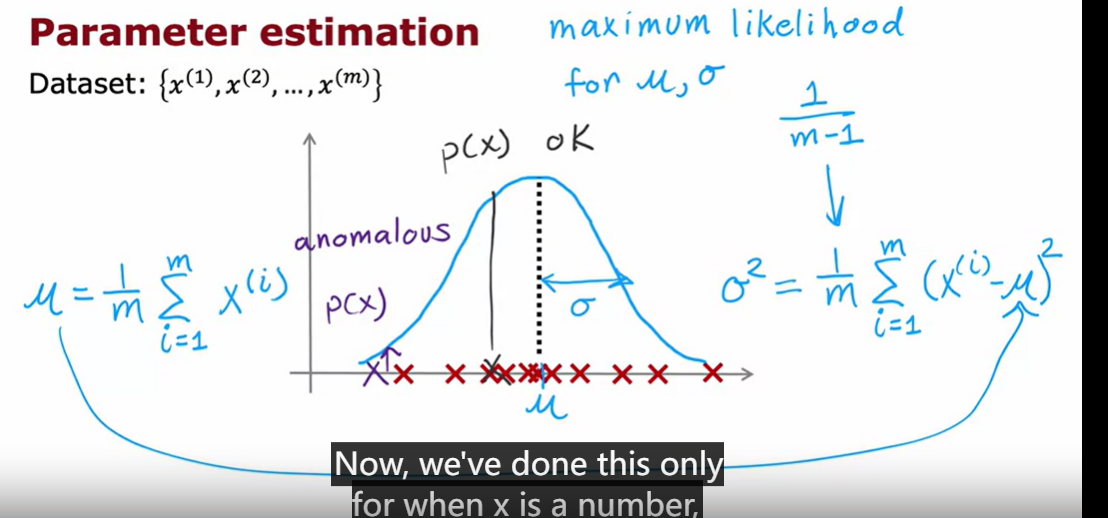

anomaly detection alogrithm

the real number evaluation

algorithm evaluation——回忆Course 2 的倾斜数据集的操作方法

how to choose from anomoly detection and supervised learning


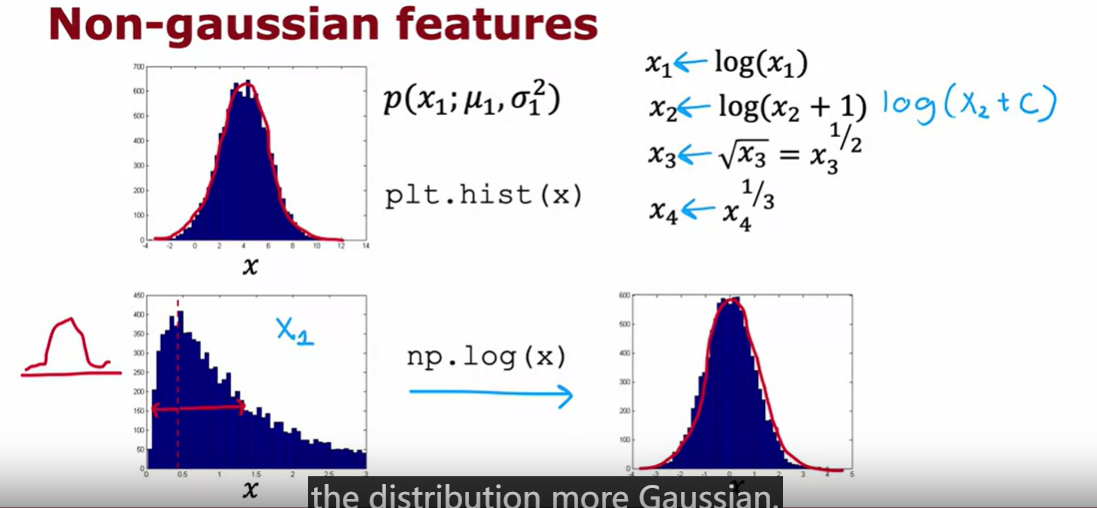
for anomaly detection, it is hard for the alogrithm to judge one feature useful or not. So it is important for anomaly detection to choose features carefully.
Week 2 recommondation system
what do we do if we have the features of the movie?

Cost function for recommendation


和上面的Cost function相比较一下——How to learn the features of the movie——We can actually learn the features for the given movie without these features externally being given

collaboritive filting alogrithm
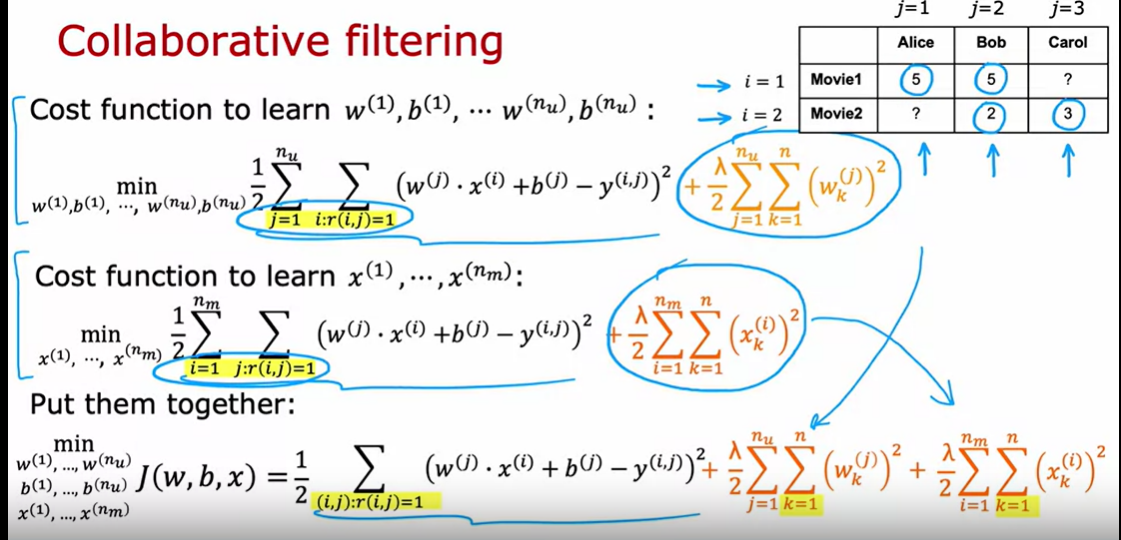
How to solve the cost function?

binary lable
cost function for binary application

mean normalization; ie. row normalization

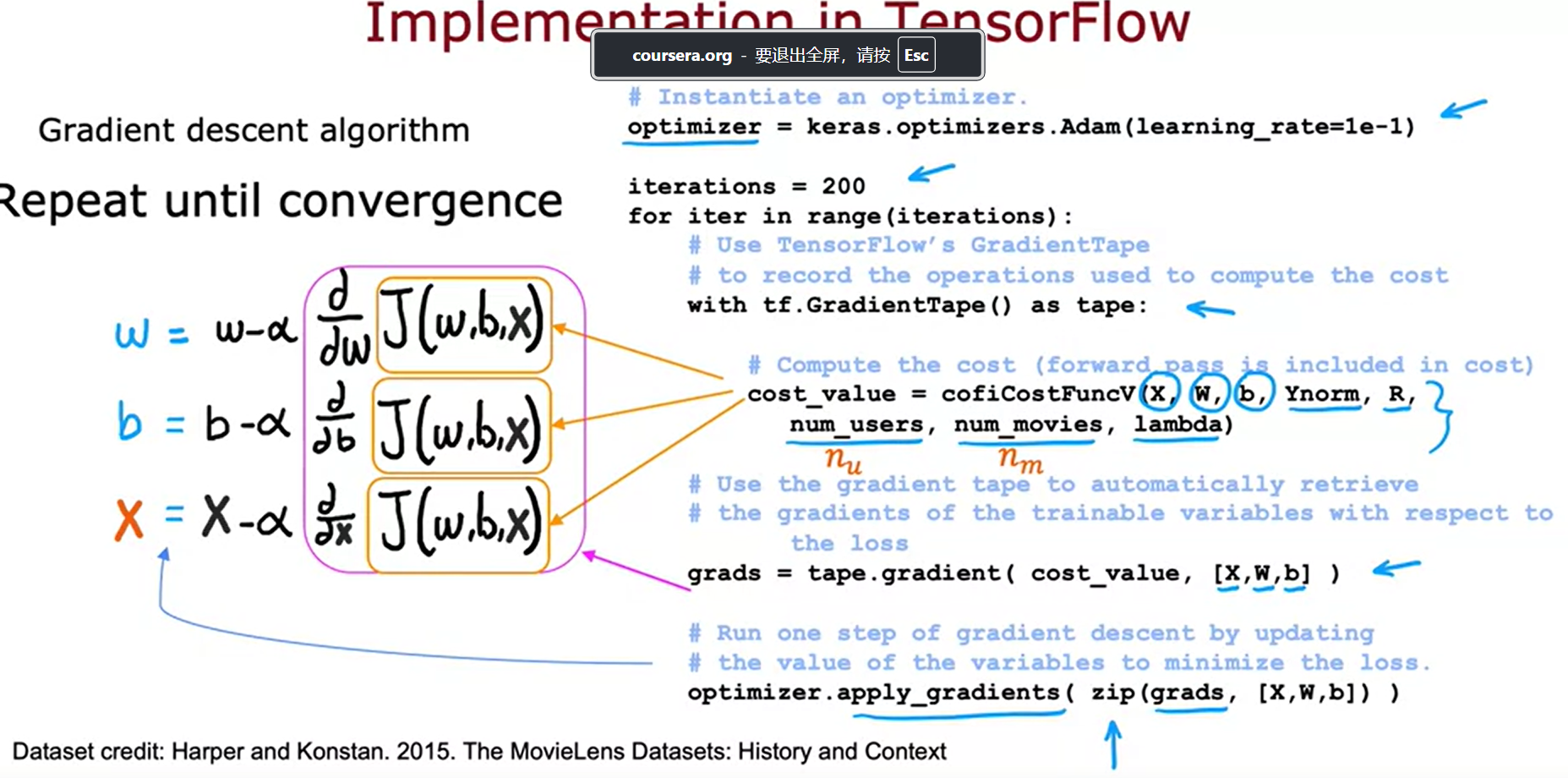
auto diff/grad
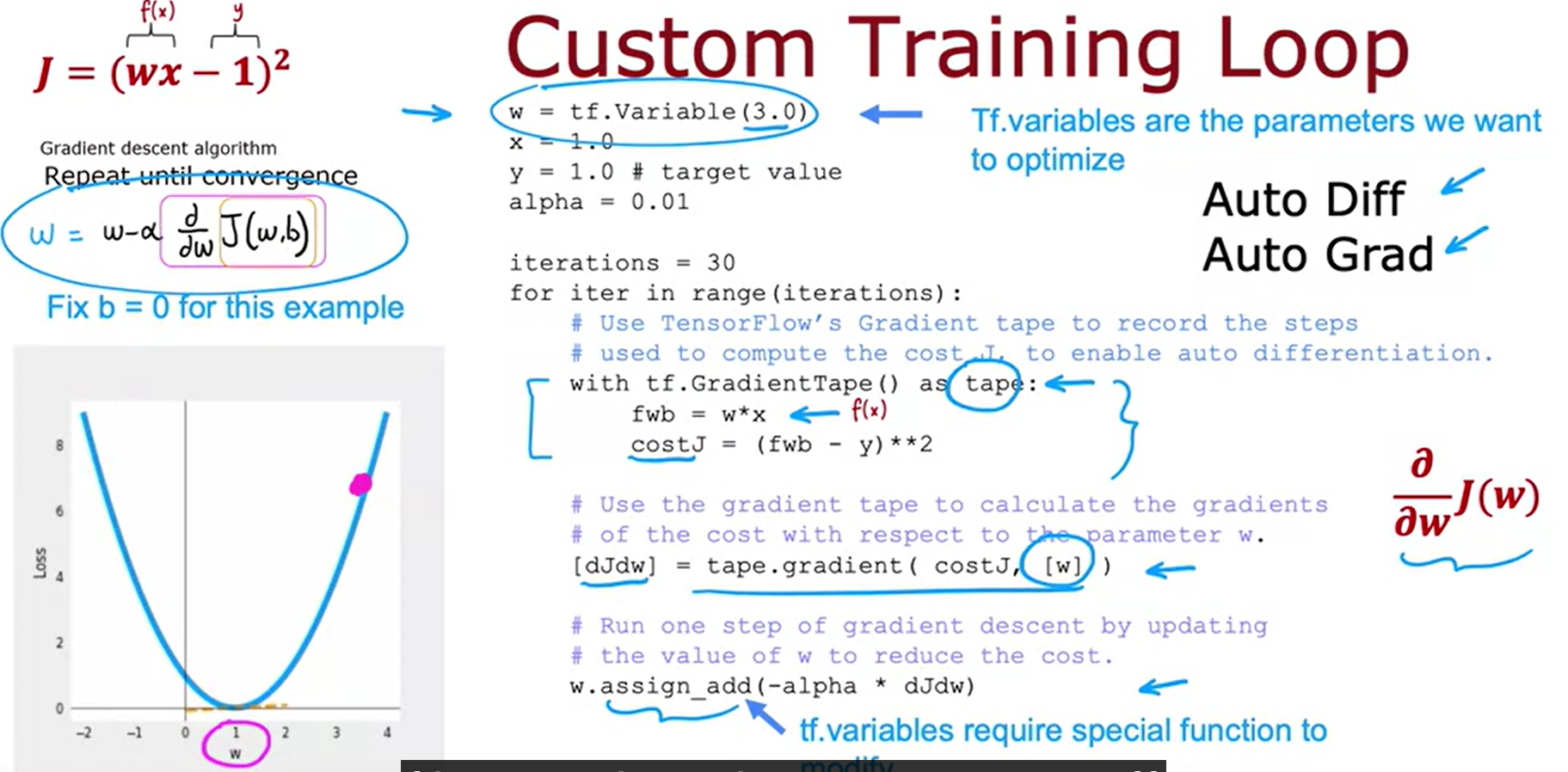
inplementation in Tensorflow for collaborative filtering system
find related items

limitations of collaborative filtering

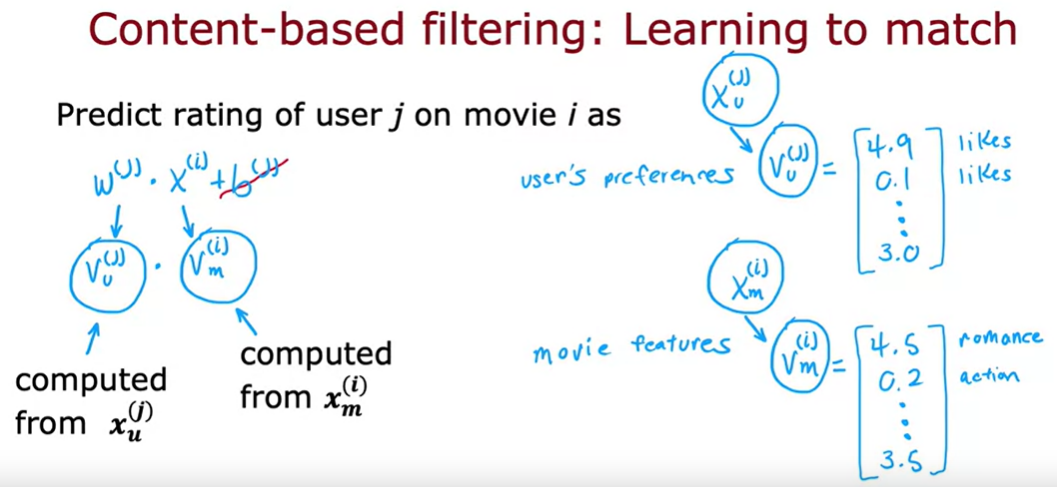
content-based filtering approach
collaborative filtering vs content-based filtering

content-based filtering : learn to match
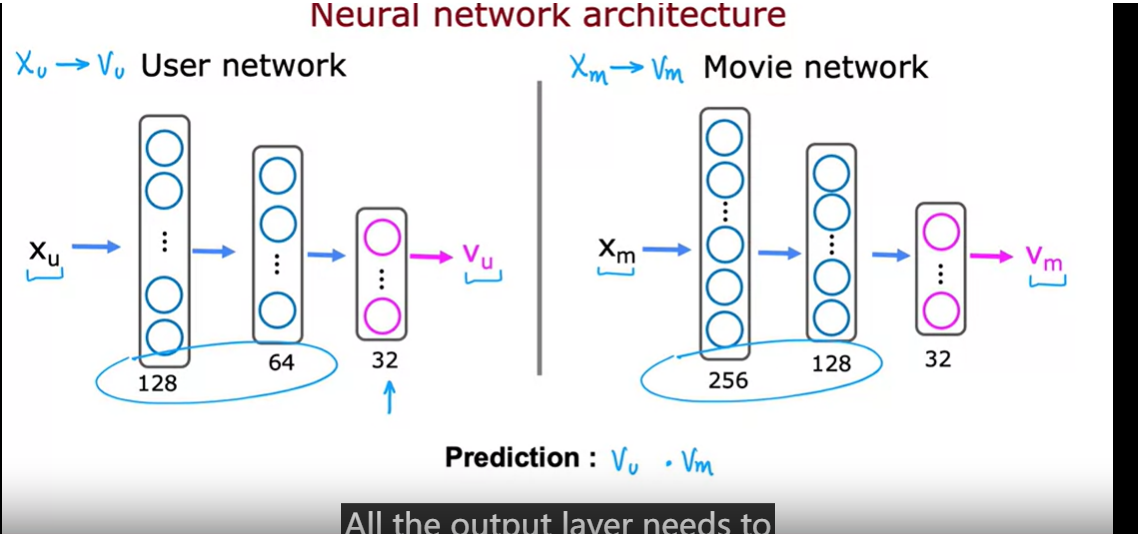
deep learning for content-based filtering
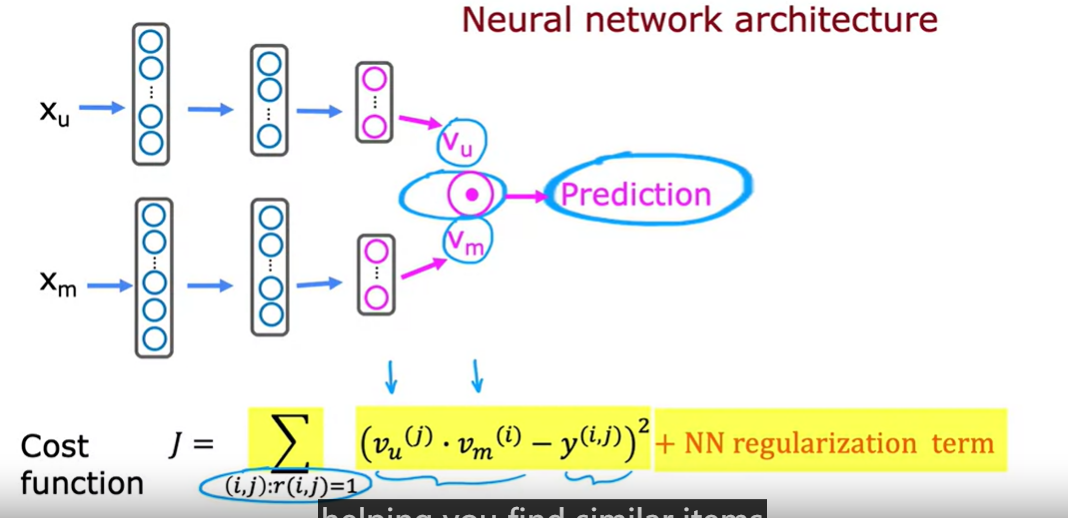
learned user and item vector

recommending from a large catalogue

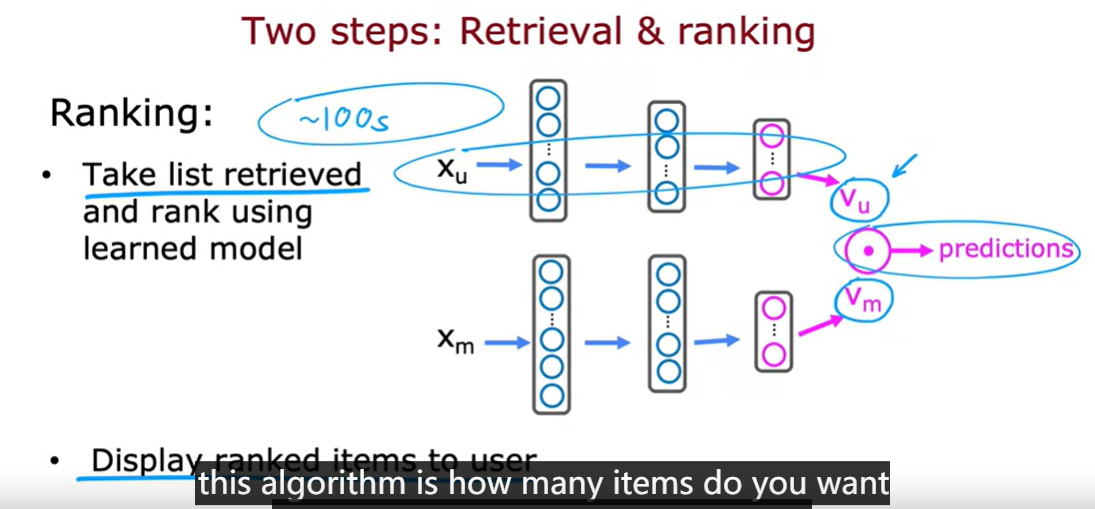
retrieval step

通过神经网络学习用户和物品的低维嵌入表示,并通过计算它们的点积来预测用户对物品的偏好
# GRADED_CELL
# UNQ_C1
num_outputs = 32
tf.random.set_seed(1)
user_NN = tf.keras.models.Sequential([
### START CODE HERE ###
tf.keras.layers.Dense(256, activation = 'relu'),
tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(num_outputs, activation = 'linear')
### END CODE HERE ###
])
item_NN = tf.keras.models.Sequential([
### START CODE HERE ###
tf.keras.layers.Dense(256, activation = 'relu'),
tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(num_outputs, activation = 'linear')
### END CODE HERE ###
])
# create the user input and point to the base network
input_user = tf.keras.layers.Input(shape=(num_user_features))
vu = user_NN(input_user)
vu = tf.linalg.l2_normalize(vu, axis=1)
# create the item input and point to the base network
input_item = tf.keras.layers.Input(shape=(num_item_features))
vm = item_NN(input_item)
vm = tf.linalg.l2_normalize(vm, axis=1)
# compute the dot product of the two vectors vu and vm
output = tf.keras.layers.Dot(axes=1)([vu, vm])
# specify the inputs and output of the model
model = tf.keras.Model([input_user, input_item], output)
model.summary()
这段代码构建了一个用于推荐系统的神经网络模型,具体地说,它是一个协同过滤模型,用于学习用户和物品的嵌入表示,并通过计算它们的点积来预测评分或匹配分数。下面是对代码的详细解释:
1. 设置输出维度和随机种子:
num_outputs = 32 tf.random.set_seed(1)
num_outputs: 定义模型的嵌入空间的维度,即用户和物品的嵌入向量的大小为 32。tf.random.set_seed(1): 设置随机种子以确保结果的可复现性。这会影响模型权重的初始化,使得每次运行时初始化相同。2. 构建用户嵌入网络(
user_NN):user_NN = tf.keras.models.Sequential([ tf.keras.layers.Dense(256, activation = 'relu'), tf.keras.layers.Dense(128, activation = 'relu'), tf.keras.layers.Dense(num_outputs, activation = 'linear') ])
tf.keras.models.Sequential(): 使用顺序模型来堆叠神经网络层。- 第一层: Dense 层,包含 256 个神经元,使用 ReLU 激活函数。
- 第二层: Dense 层,包含 128 个神经元,使用 ReLU 激活函数。
- 第三层: Dense 层,包含
num_outputs个神经元,使用线性激活函数。线性激活函数通常用于最后一层,以输出一个实数向量,这里表示用户的嵌入向量。3. 构建物品嵌入网络(
item_NN):item_NN = tf.keras.models.Sequential([ tf.keras.layers.Dense(256, activation = 'relu'), tf.keras.layers.Dense(128, activation = 'relu'), tf.keras.layers.Dense(num_outputs, activation = 'linear') ])
- 结构与
user_NN完全相同,只是输入数据不同。item_NN网络用于生成物品的嵌入表示。4. 创建用户输入和嵌入:
input_user = tf.keras.layers.Input(shape=(num_user_features)) vu = user_NN(input_user) vu = tf.linalg.l2_normalize(vu, axis=1)
tf.keras.layers.Input(): 定义输入层,shape=(num_user_features)表示输入的特征向量大小。user_NN(input_user): 将输入数据通过用户嵌入网络,生成用户的嵌入向量vu。tf.linalg.l2_normalize(vu, axis=1): 对用户嵌入向量进行 L2 正则化,使得每个向量的长度为 1。这有助于在计算点积时规范化向量的尺度。5. 创建物品输入和嵌入:
input_item = tf.keras.layers.Input(shape=(num_item_features)) vm = item_NN(input_item) vm = tf.linalg.l2_normalize(vm, axis=1)
- 与用户输入和嵌入处理类似,这里定义了物品输入
input_item,并通过物品嵌入网络item_NN生成物品嵌入向量vm,同样对其进行 L2 正则化。6. 计算用户和物品向量的点积:
output = tf.keras.layers.Dot(axes=1)([vu, vm])
tf.keras.layers.Dot(axes=1): 计算用户向量vu和物品向量vm之间的点积。点积用于衡量两个向量的相似性或匹配程度。这里的axes=1表示沿着每个向量的最后一个维度计算点积。7. 构建模型并总结:
model = tf.keras.Model([input_user, input_item], output) model.summary()
tf.keras.Model([input_user, input_item], output): 定义最终的模型,将用户输入和物品输入连接到输出点积结果。输入是[input_user, input_item],输出是它们的点积output。model.summary(): 打印模型的架构总结,显示每一层的输出形状和参数数量。总结:
这个模型的主要目标是通过神经网络学习用户和物品的低维嵌入表示,并通过计算它们的点积来预测用户对物品的偏好。通过 L2 正则化确保向量的单位长度,从而使得点积的结果主要由向量方向决定,而不是它们的尺度。模型构建完成后,可以通过训练使其学习用户与物品之间的关系,并最终用于推荐系统中。
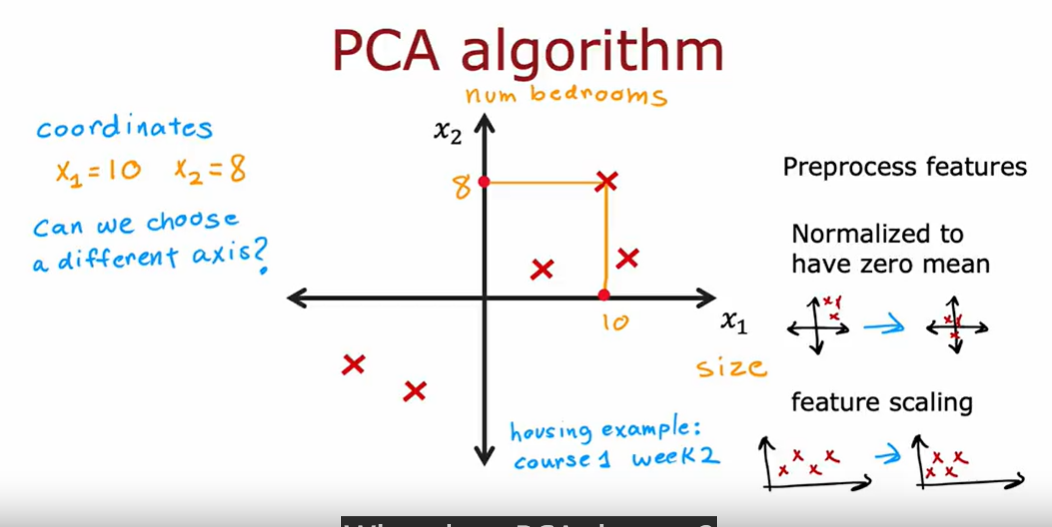
Principal component analysis
use fewer numbers to capture “size” feature

from 3d to 2d

preprocess data
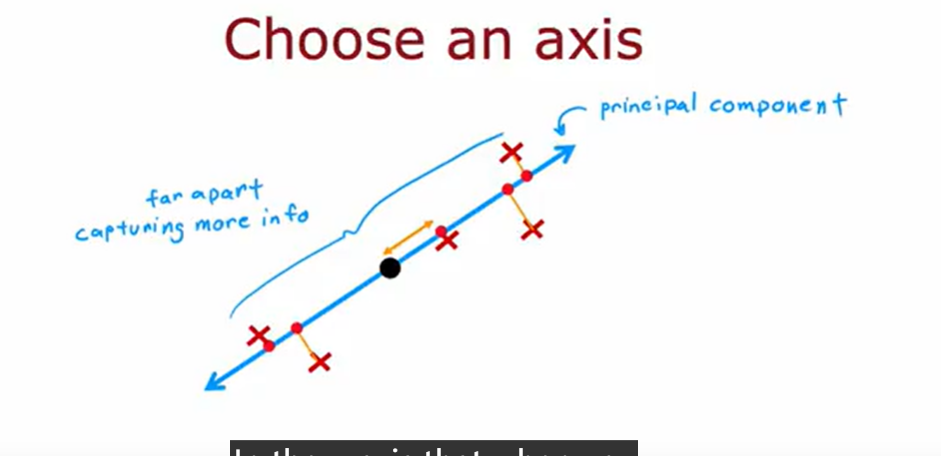
principle component
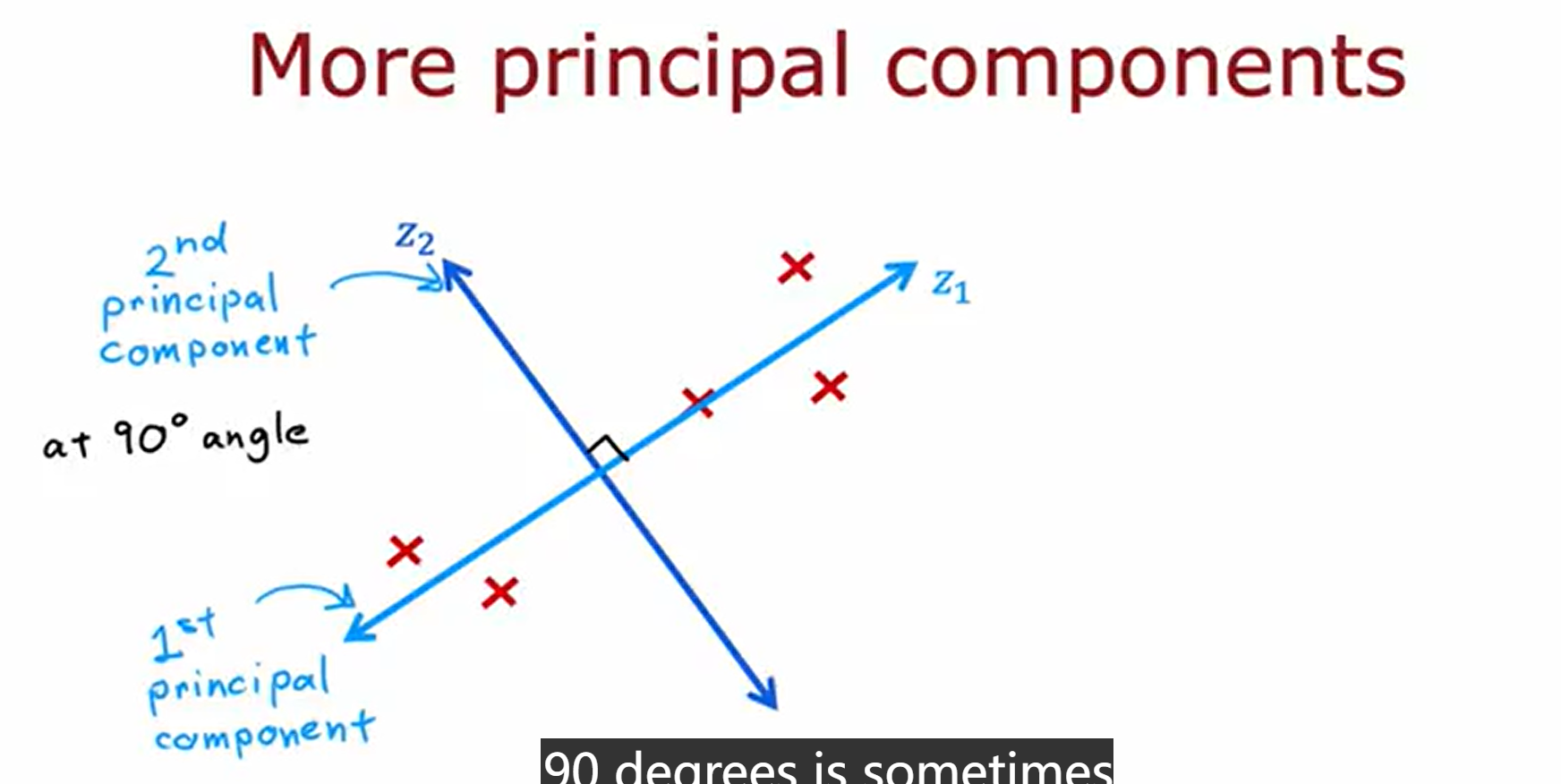
more principle component
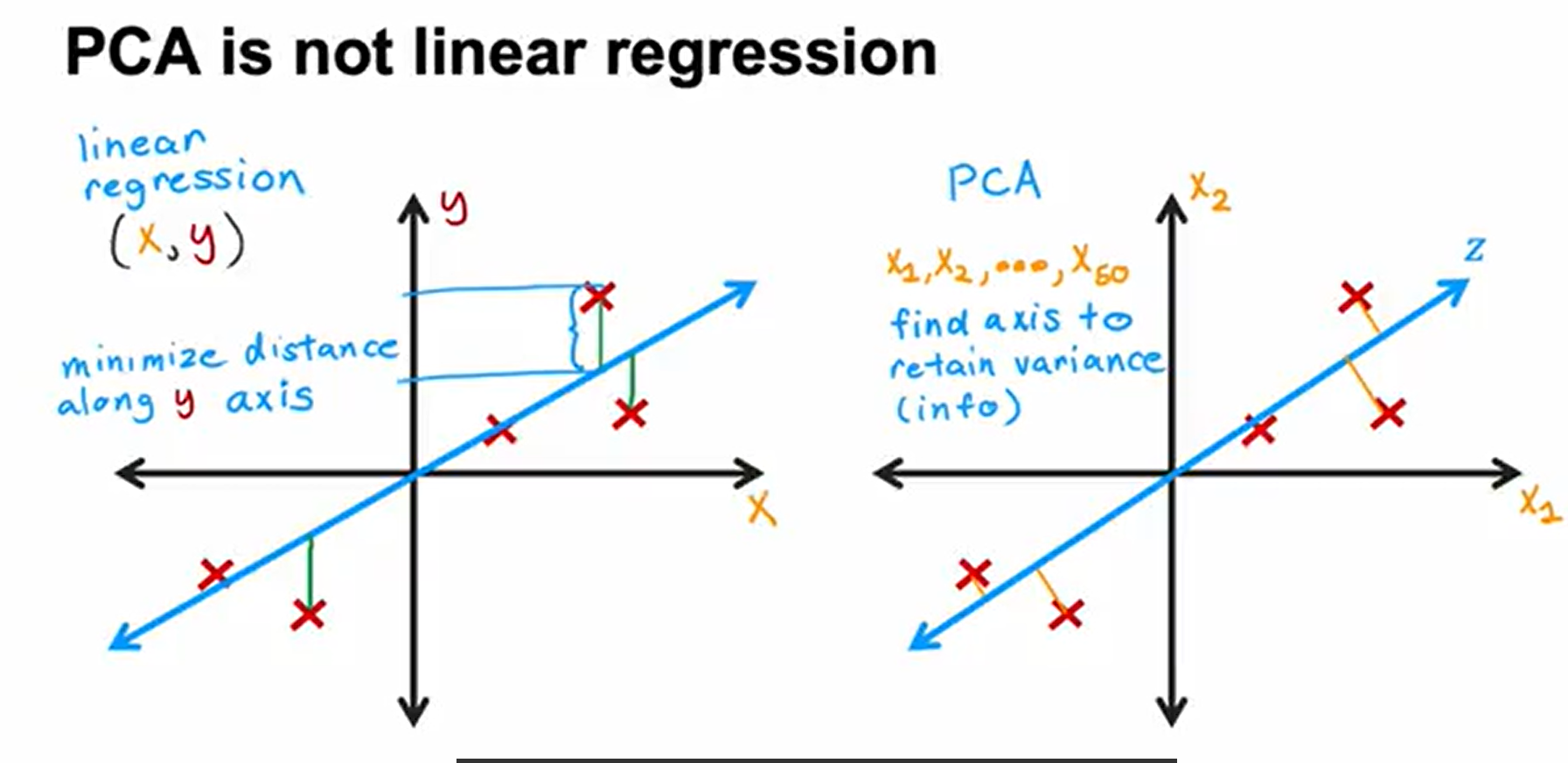
pca is not linear regression
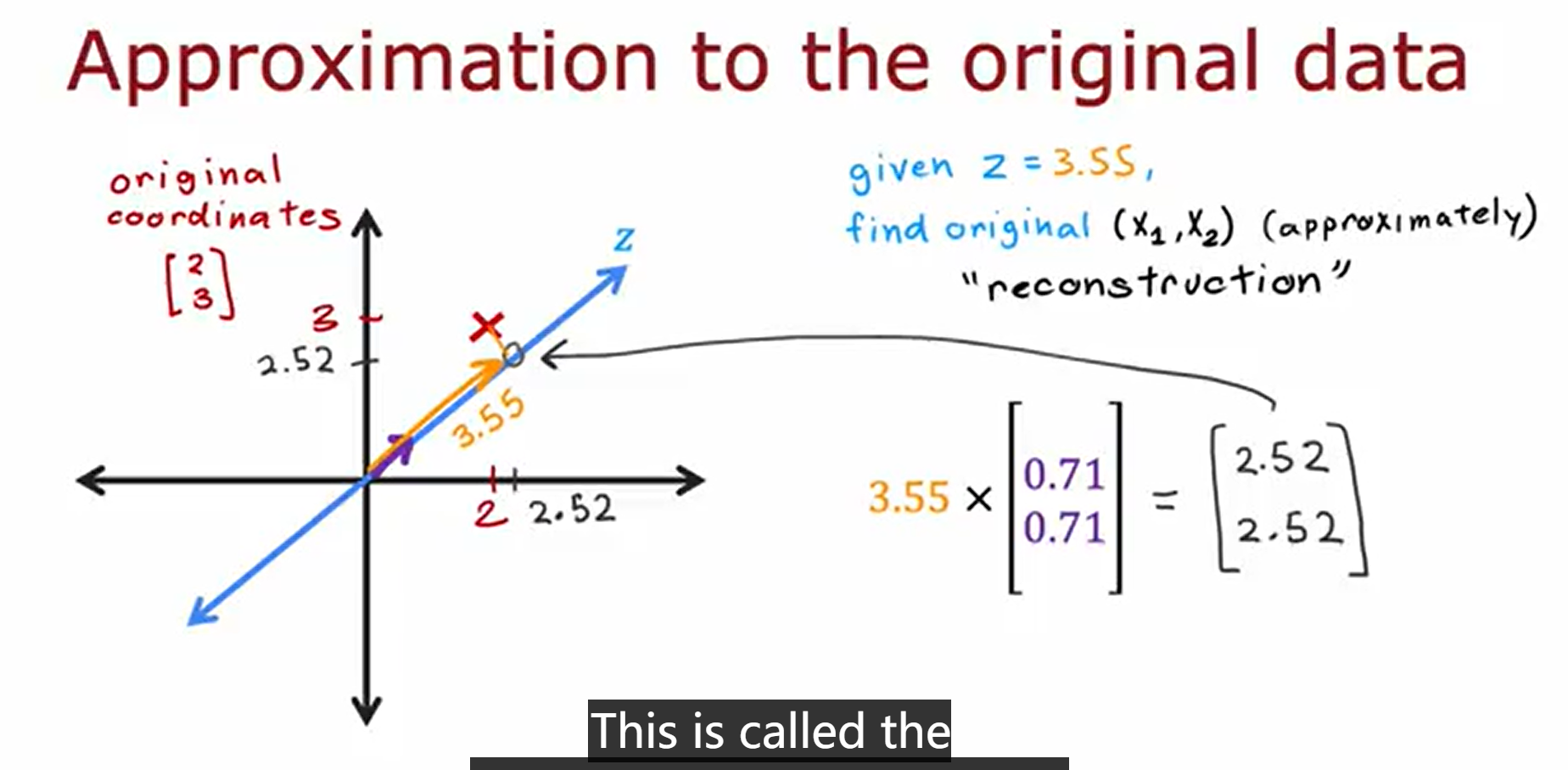
the reconstruction of PCA
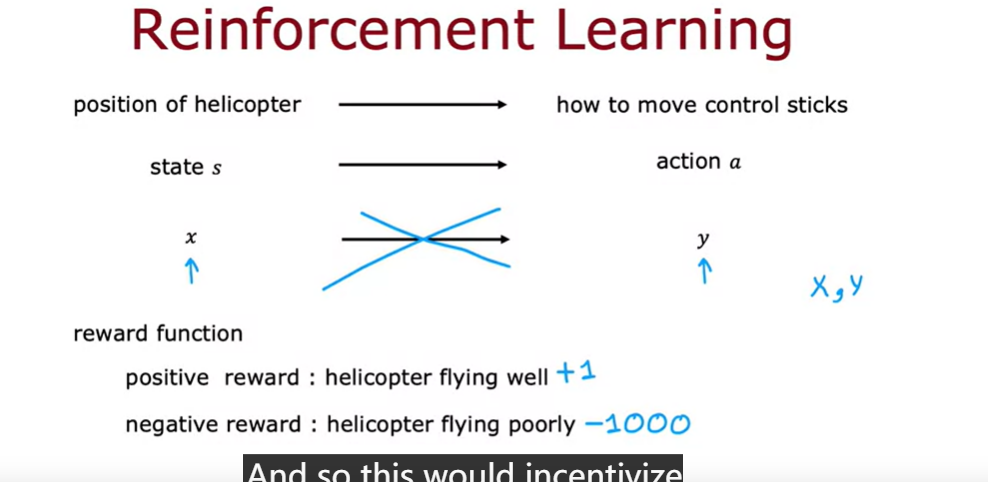
Week 3 reinforcement learning
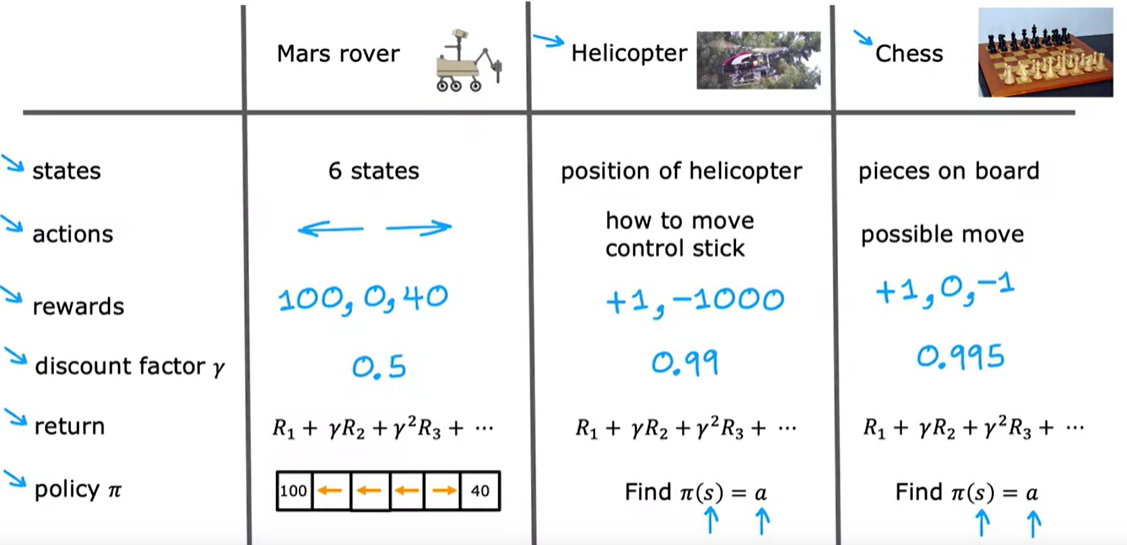
reward function
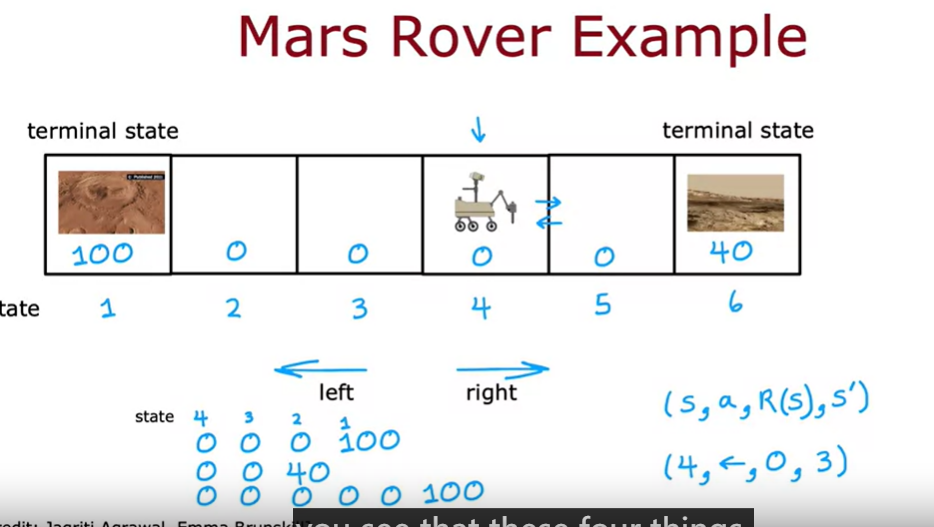
四元组
return && dicount factor

Policy

the concepts of the reinforcment learning
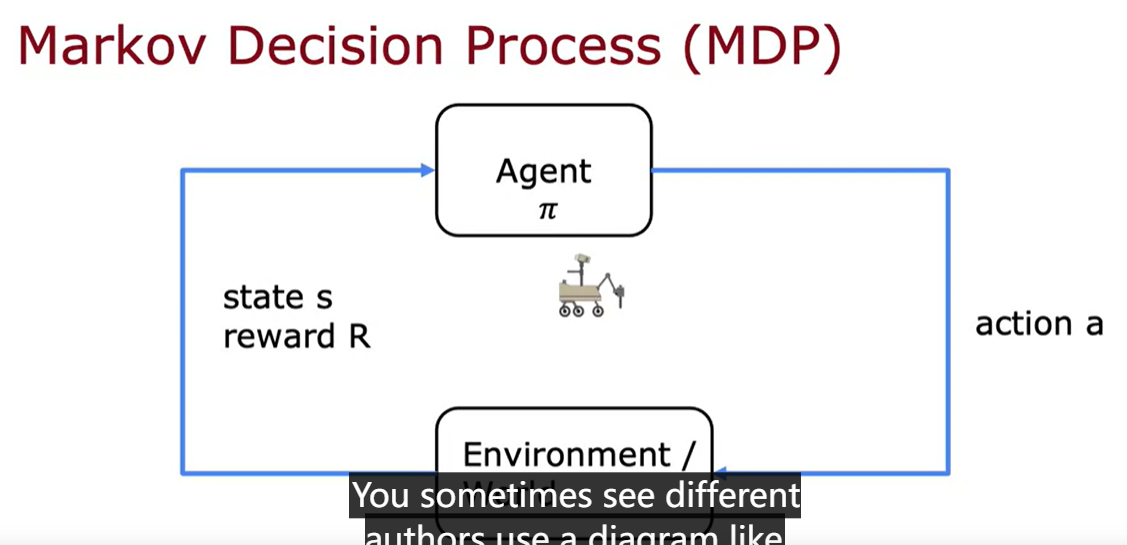
markov decision process
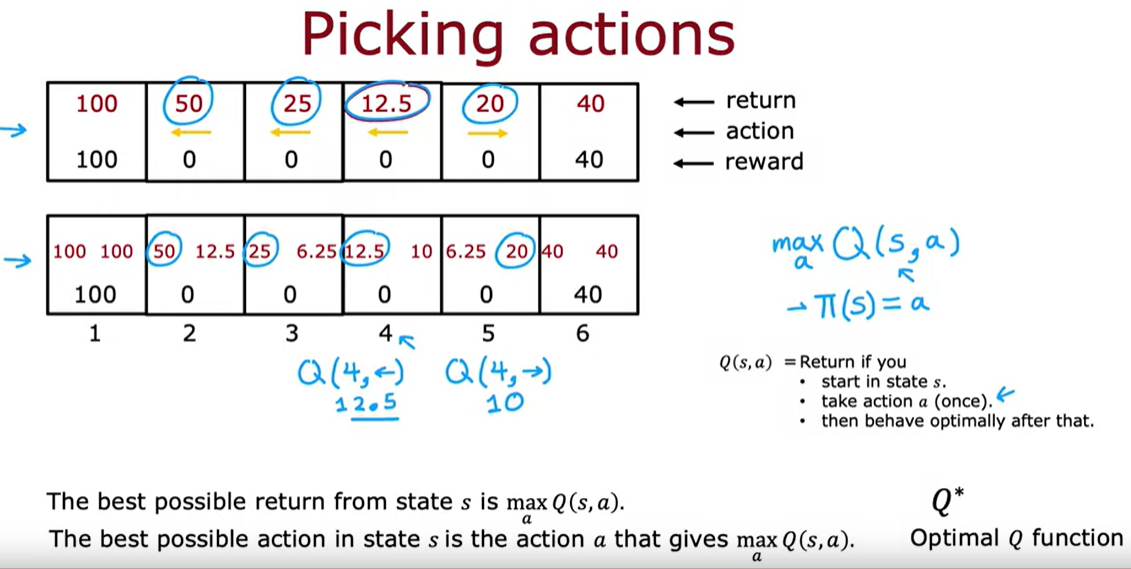
state action value function

Picking actions
bellman equation

stochastic environment
expected return

contineous state space

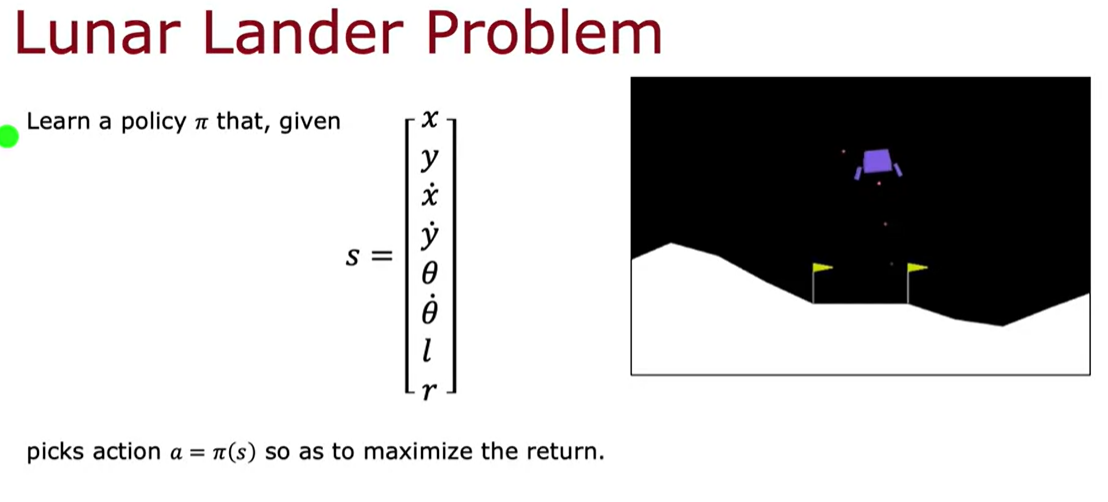
lunar lander problem
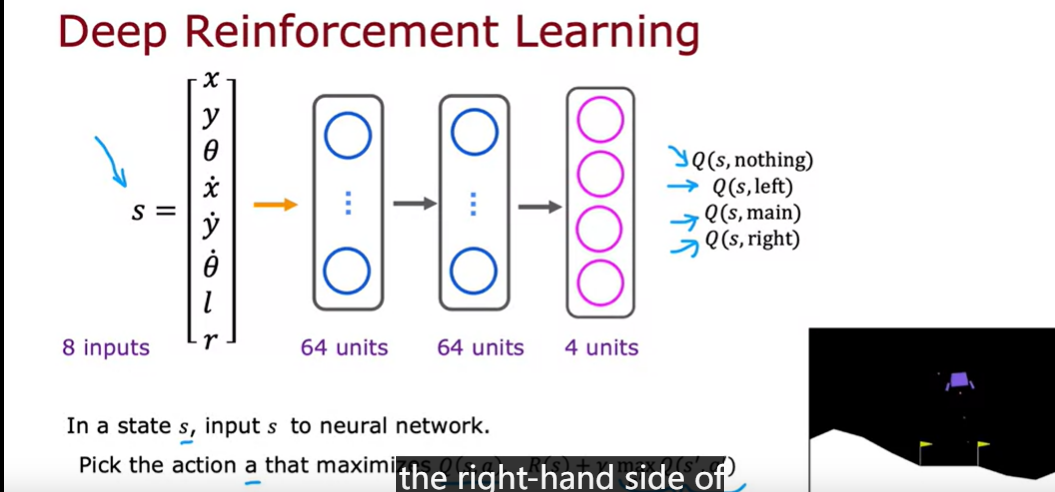
deep reinforcement learning
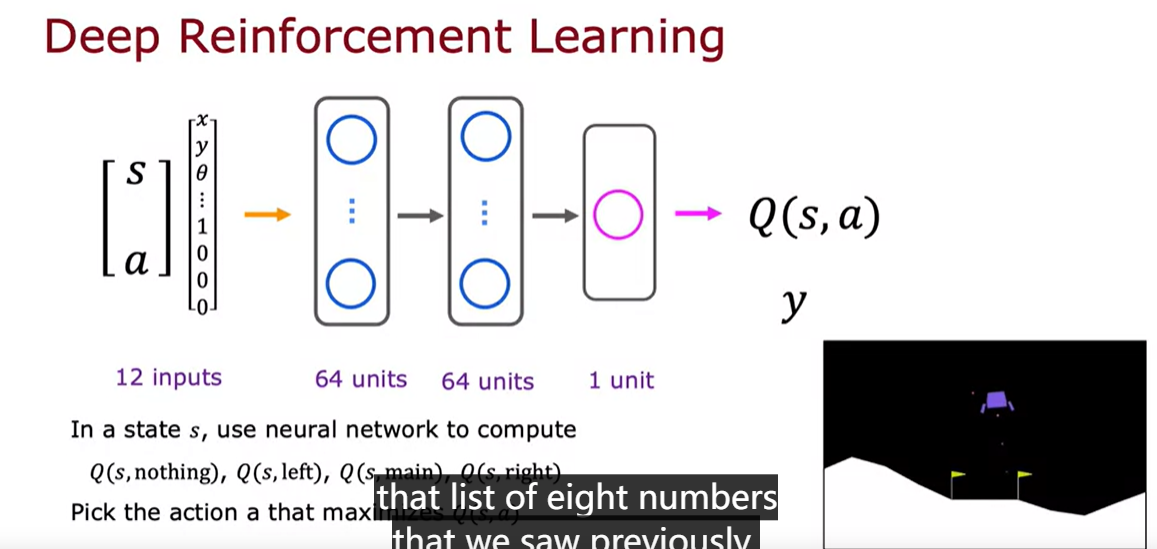
DQN(Deep Q network learning alogrithm

some refinements on the neuron network architecture
ϵ \epsilon ϵ - greedy policy
how to choose actions while still learning
explaitation && exploration

by the way , it it worth to notice that the reinforcement learning is more finicky than the supervised learning, which means if you choose a bad paramater, it may take much more time(10 times maybe) to train.
Mini-batch and soft updates
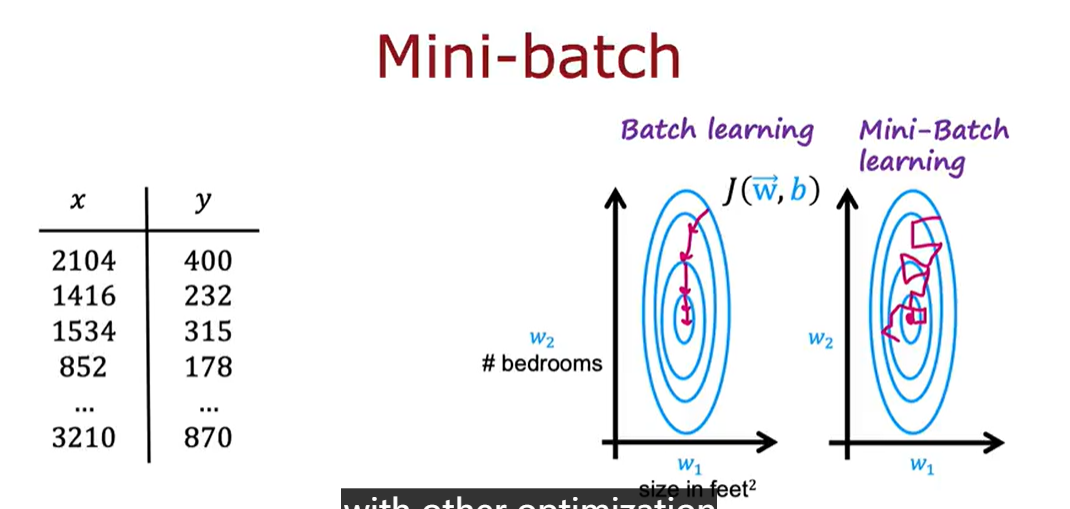
每次只取一个很大样本的一部分进行训练,从而极大加快了训练的速度。但是缺点也非常明显,就是它的整体的成本函数往往不会一直降低(如右上图)所示
minibatch in reinforcement leaning

soft update : make a gradual update to Q

limitations of reinforcement learning

target network

experience replay
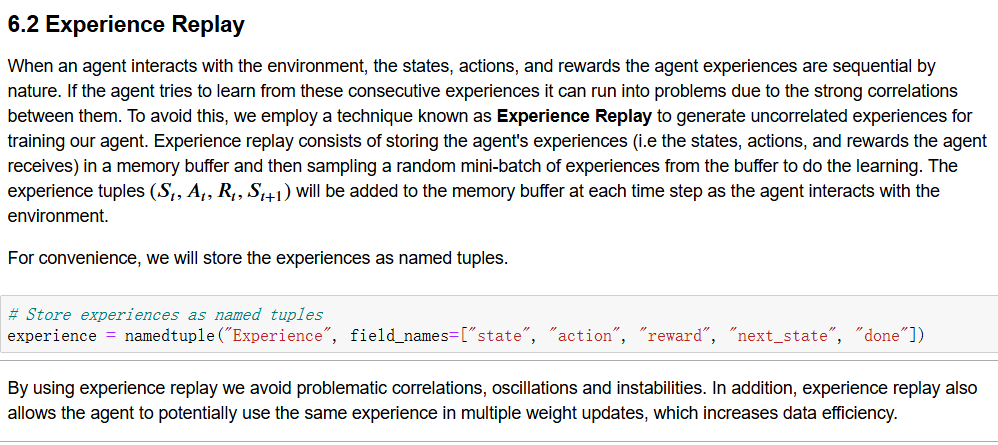
deep Q-learning Alogrithm with experience replay

终于学完了,哈哈哈哈哈哈哈!(已经精神失常了)
ate to Q
[外链图片转存中…(img-6vvmTQyT-1726294284614)]
limitations of reinforcement learning
[外链图片转存中…(img-km1lrUV5-1726294284615)]
target network
[外链图片转存中…(img-MkDm2yf5-1726294284615)]
experience replay
[外链图片转存中…(img-L4TkT2R6-1726294284615)]
deep Q-learning Alogrithm with experience replay
[外链图片转存中…(img-UExf8sQS-1726294284616)]
终于学完了,哈哈哈哈哈哈哈!(已经精神失常了)















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









