







Returns in *device the current device for the calling host thread.
Parameters:
device - Returns the device on which the active host thread executes the device code.
Returns:
cudaSuccess
cudaError_t cudaSetDevice ( int device )
Sets device as the current device for the calling host thread.
Any device memory subsequently allocated from this host thread using cudaMalloc(), cudaMallocPitch() or cudaMallocArray() will be physically resident on device. Any host memory allocated from thishost thread using cudaMallocHost() or cudaHostAlloc() or cudaHostRegister() will have its lifetime associated with device. Any streams or events created from thishost thread will be associated with device. Any kernels launched from this host thread using the <<<>>> operator or cudaLaunch() will be executed on device.
This call may be made from any host thread, to any device, and at any time. This function will do no synchronization with the previous or new device, and should be considered a very low overhead call.
Parameters:
device - Device on which the active host thread should execute the device code.
Returns:
cudaSuccess, cudaErrorInvalidDevice, cudaErrorSetOnActiveProcess
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Then I found a slides(2009) about this.
http://www.ks.uiuc.edu/Research/gpu/files/multigpusched.20090224.pdf
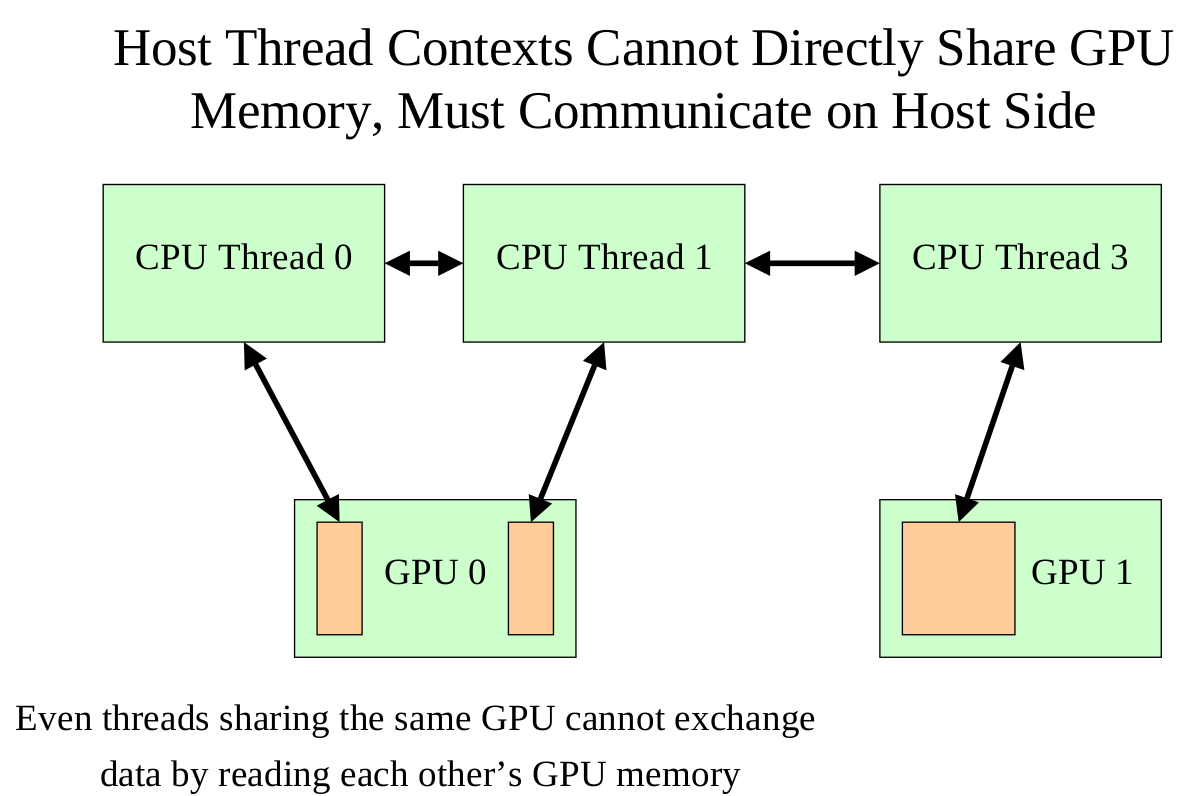
A single host thread can attach to and communicate with a single GPU
A single GPU can be shared by multiple threads/processes, but only one such context is active at a time
In order to use more than one GPU, multiple host threads or processes must be created.
About "Data Exchange Between GPUs", it talks about the Limitations with current version of CUDA(in fact, it seems that multiple GPUs can communicate with each other now.):
1.No way to directly exchange data between multiple GPUs using CUDA.
2.Exchanges must be done on the host side outside of CUDA.
3.Involves host thread/process responsible for each device"
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
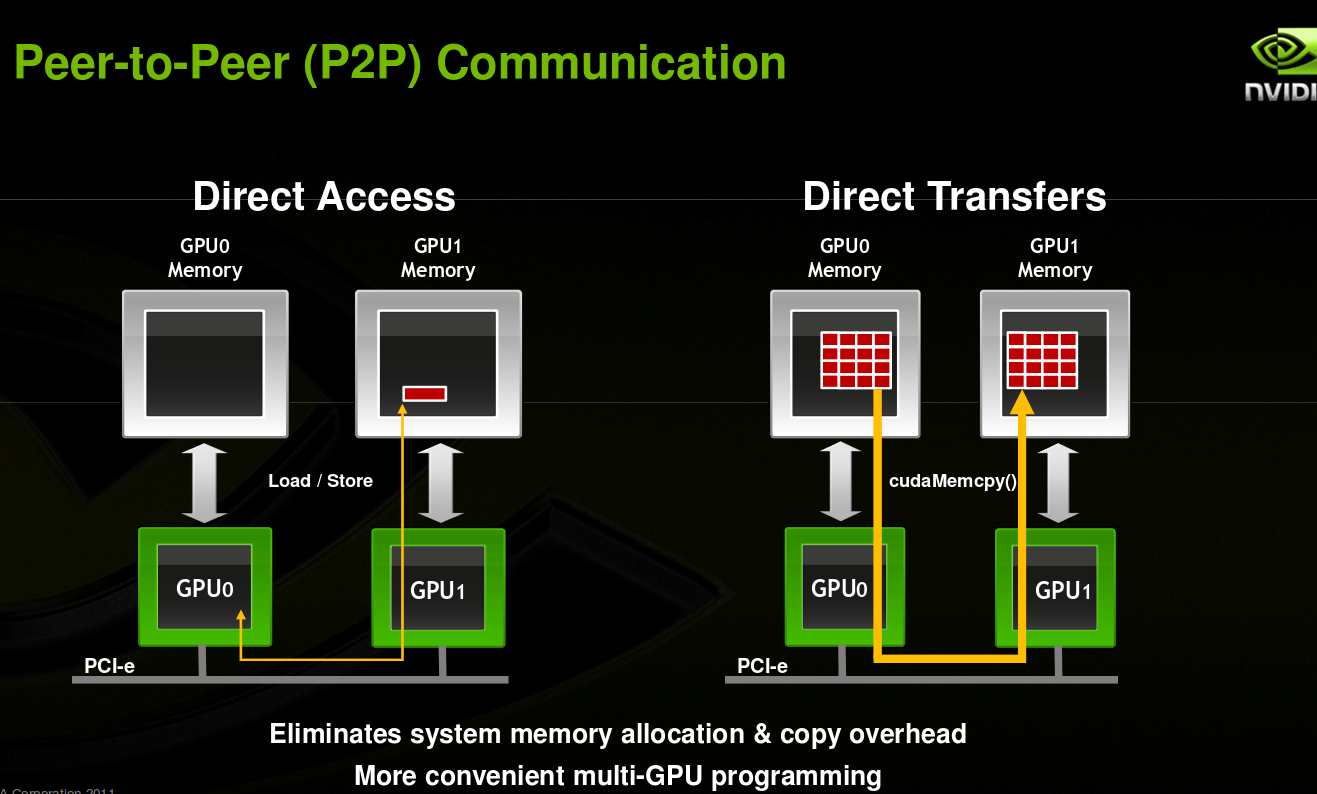
from: http://on-demand.gputechconf.com/gtc-express/2011/presentations/cuda_webinars_GPUDirect_uva.pdf















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









