







论文笔记:SlowFast Networks for Video Recognition
灵魂三问:
-
作者想干什么?
提取视频信息
-
是怎么实现的?
通过分别低采样和高采样
低采样:提取空间语义(spacial sematics)
高采样:提取时域上的运动
-
实现了什么目标?
在动作识别以及检测都有很显著提升
测试集:Kinetics, Charades, AVA,
Intuition
在图片中, I ( x , y ) I(x,y) I(x,y) 有各向同性 (isotropic), 那么视频信号中是否有呢?
空域和时域显然是不具备向同性的。
所以想法就是将空域和时域分开来处理。
基于这种想法就构建了两条通路, 一条用来检测图片语义,使用低帧率。
. One pathway is designed to capture semantic information that can be given by images or a few sparse frames, and it operates at low frame rates and slow refreshing speed.
另一条用来检测移动,动作(motion)通过高帧率。
the
other pathway is responsible for capturing rapidly changing
motion, by operating at fast refreshing speed and high tem-
poral resolution.
两条网络在几个地方互相交融。
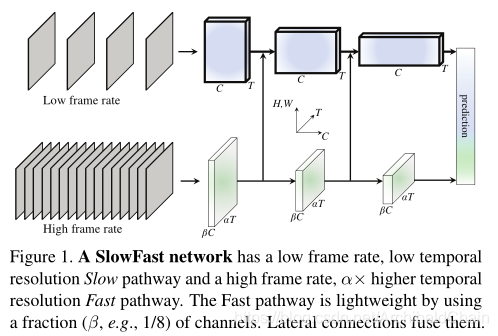
构造网络
慢速通道
可以是任何用来学习视频的模型,唯一特点是需要很大的采样步长(temporal stride) τ \tau τ, 也就是说,每个时间范围内 τ \tau τ, 采样一帧。
特别地,作者使用了 τ = 16 \tau = 16 τ=16,在三十帧视频中每秒采样两帧。
慢速通道一共采样的帧数表示为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









