







(5)使用库matplotlib 和seaborn 创建了一个包含两个子图的图形,通过条形图和饼图的形式展示了电影中最常见的电影类别及其百分比比例。
genres_list = []
for i in df['genres']:
genres_list.extend(i.split(', '))
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14,6))
df_plot = pd.DataFrame(Counter(genres_list).most_common(5), columns=['genre', 'total'])
ax = sns.barplot(data=df_plot, x='genre', y='total', ax=axes[0], palette=['#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811'])
ax.set_title('Top 5 Genres in Movies', fontsize=18, weight=600, color='#333d29')
sns.despine()
df_plot_full = pd.DataFrame([Counter(genres_list)]).transpose().sort_values(by=0, ascending=False)
df_plot.loc[len(df_plot)] = {'genre': 'Others', 'total':df_plot_full[6:].sum()[0]}
plt.title('Percentage Ratio of Movie Genres', fontsize=18, weight=600, color='#333d29')
wedges, texts, autotexts = axes[1].pie(x=df_plot['total'], labels=df_plot['genre'], autopct='%.2f%%',
textprops=dict(fontsize=14), explode=[0,0,0,0,0,0.1], colors=['#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811', '#fdc100'])
for autotext in autotexts:
autotext.set_color('#1c2541')
autotext.set_weight('bold')
axes[1].axis('off')上述代码的实现流程如下所示:
- 首先,通过循环遍历电影数据中的 'genres' 列,将每个电影的类别拆分成单独的列表,并将这些列表合并为一个总的类别列表 genres_list。
- 接着,通过 plt.subplots 创建了一个包含两个子图的图形对象。nrows=1 和 ncols=2 指定了子图的行数和列数,figsize=(14,6) 设置了整个图形的大小。
- 然后,通过 sns.barplot 绘制了一个条形图,显示了电影中前五个最常见的电影类别。数据框 df_plot 包含了每个类别及其出现次数,颜色使用了预定义的调色板。
- 接下来,创建了一个新的数据框 df_plot_full,其中包含了所有电影类别的出现次数,并将其中排名第六及以下的类别合并成一个名为 'Others' 的类别。
- 最后,通过 axes[1].pie 绘制了一个饼图,展示了电影类别的百分比比例。饼图中的 'Others' 部分使用了稍微突出的效果 (explode)。
执行后会绘制展示电影类别的百分比比例的饼形图,如图11-5所示。
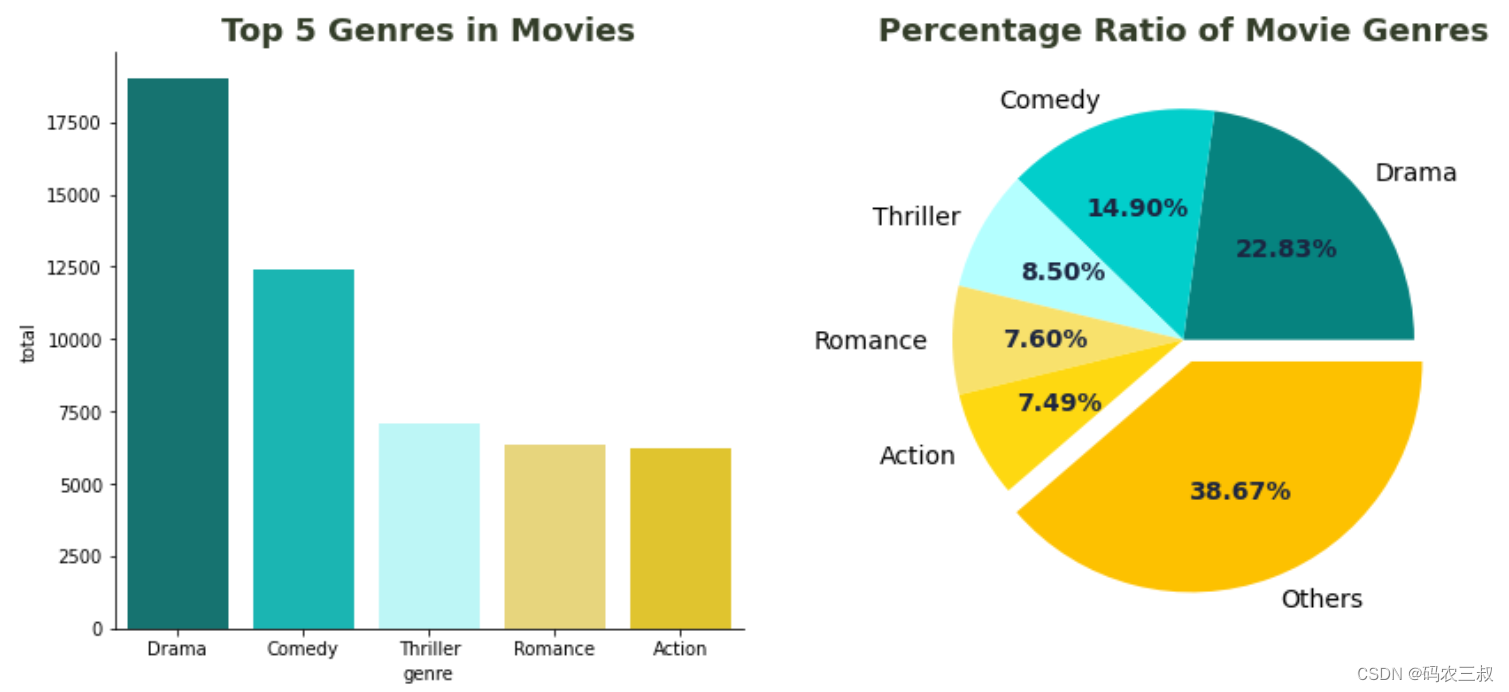
图11-5 电影类别的百分比比例的饼形图
通过上面的饼形图可以看出:
- 戏剧是最主导的电影类别,超过18000部电影属于这一类别。
- 在前五大电影类别中,数据集中仍然包含许多其他类别。它们占据了电影中总类别的38.67%。
(6)使用seaborn 库创建了一个直方图(Histogram)和核密度估计图,展示了电影按发布日期的分布情况。
sns.displot(data=df, x='release_date', kind='hist', kde=True,
color='#fdc100', facecolor='#06837f', edgecolor='#64b6ac', line_kws={'lw': 3}, aspect=3)
plt.title('Total Released Movie by Date', fontsize=18, weight=600, color='#333d29')上述代码的实现流程如下所示:
- sns.displot(...):通过 displot 函数创建直方图和核密度估计图。data=df 指定了数据框,x='release_date' 设置了 x 轴的数据为电影的发布日期,kind='hist' 指定了图形类型为直方图,kde=True 添加了核密度估计,color='#fdc100' 设置了整体颜色,facecolor='#06837f' 设置了直方图的颜色,edgecolor='#64b6ac' 设置了直方图的边缘颜色,line_kws={'lw': 3} 设置了核密度估计曲线的线宽,aspect=3 设置了图形的纵横比。
- plt.title('Total Released Movie by Date', fontsize=18, weight=600, color='#333d29'):添加图形标题,描述了“按日期发布的电影总数”。
整体而言,这段代码绘制了一个直方图和核密度估计图,以直观地展示电影按照发布日期的分布情况。如图11-6所示。
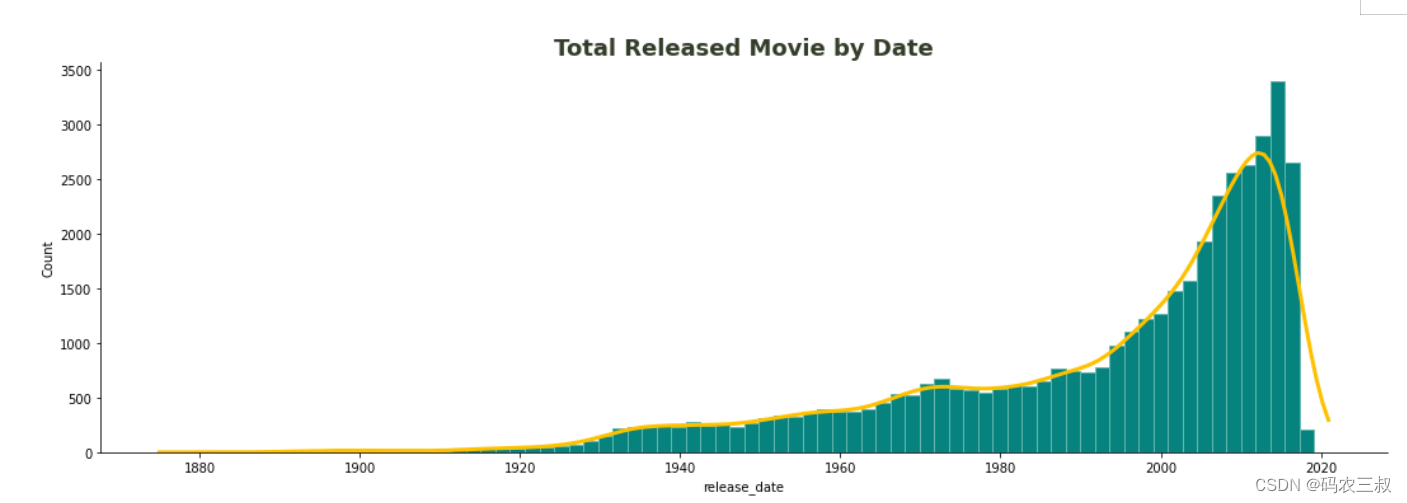
图11-6 直方图和核密度估计图
通过上面的直方图和核密度估计图可以看出:
- 从1930年开始,电影产业在过去50年里取得了显著的增长。
- 在2020年左右,总发布电影数出现下降,这是因为数据集中在那些年份仅包含了少量数据。
(7)在如下所示的代码中,通过循环遍历数据框中的多列,将包含多个值的字符串分割并扩展到相应的列表中。以下是代码中使用的列表以及它们对应的数据列:
- original_language_list:包含了电影的原始语言。
- spoken_languages_list:包含了电影的口语语言。
- actors_list:包含了电影的演员列表。
- crew_list:包含了电影的制作组成员列表。
- company_list:包含了电影的制作公司列表。
- country_list:包含了电影的制作国家列表。
这样的数据处理步骤通常用于将包含多个元素的字符串拆分成单独的项,以便更好地进行分析和可视化。
original_language_list = []
for i in df['original_language']:
original_language_list.extend(i.split(', '))
spoken_languages_list = []
for i in df['spoken_languages']:
if i != '':
spoken_languages_list.extend(i.split(', '))
actors_list = []
for i in df['actors']:
if i != '':
actors_list.extend(i.split(', '))
crew_list = []
for i in df['crew']:
if i != '':
crew_list.extend(i.split(', '))
company_list = []
for i in df['production_companies']:
if i != '':
company_list.extend(i.split(', '))
country_list = []
for i in df['production_countries']:
if i != '':
country_list.extend(i.split(', '))上述代码的实现流程如下:
- 首先,对 'original_language' 列进行循环遍历,将包含多个语言的字符串分割并扩展到 original_language_list 中。
- 接着,对 'spoken_languages' 列进行循环遍历,检查非空字符串,将包含多个口语语言的字符串分割并扩展到 spoken_languages_list 中。
- 然后,对 'actors' 列进行循环遍历,检查非空字符串,将包含多个演员的字符串分割并扩展到 actors_list 中。
- 接下来,对 'crew' 列进行循环遍历,检查非空字符串,将包含多个制作组成员的字符串分割并扩展到 crew_list 中。
- 然后,对 'production_companies' 列进行循环遍历,检查非空字符串,将包含多个制作公司的字符串分割并扩展到 company_list 中。
- 最后,对 'production_countries' 列进行循环遍历,检查非空字符串,将包含多个制作国家的字符串分割并扩展到 country_list 中。
(8)使用 matplotlib 和 seaborn 库创建了一个包含六个子图的图形,每个子图展示了不同方面的数据分布。
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(13, 10))
# Spoken language plot
df_plot1 = pd.DataFrame(Counter(spoken_languages_list).most_common(5), columns=['language', 'total']).sort_values(by='total', ascending=True)
axes[0,0].hlines(y=df_plot1['language'], xmin=0, xmax=df_plot1['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[0,0].scatter(x=df_plot1['total'], y=df_plot1['language'], s = 75, color='#fdc100')
axes[0,0].set_title('\nTop 5 Spoken Languages\nin Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot1['total']):
axes[0,0].text(value+1000, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Original Language plot
df_plot2 = pd.DataFrame(Counter(original_language_list).most_common(5), columns=['language', 'total']).sort_values(by='total', ascending=True)
axes[0,1].hlines(y=df_plot2['language'], xmin=0, xmax=df_plot2['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[0,1].scatter(x=df_plot2['total'], y=df_plot2['language'], s = 75, color='#fdc100')
axes[0,1].set_title('\nTop 5 Original Languages\nin Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot2['total']):
axes[0,1].text(value+1000, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Actor plot
df_plot3 = pd.DataFrame(Counter(actors_list).most_common(5), columns=['actor', 'total']).sort_values(by='total', ascending=True)
axes[1,0].hlines(y=df_plot3['actor'], xmin=0, xmax=df_plot3['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[1,0].scatter(x=df_plot3['total'], y=df_plot3['actor'], s = 75, color='#fdc100')
axes[1,0].set_title('\nTop 5 Actors in Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot3['total']):
axes[1,0].text(value+10, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Crew plot
df_plot4 = pd.DataFrame(Counter(crew_list).most_common(5), columns=['name', 'total']).sort_values(by='total', ascending=True)
axes[1,1].hlines(y=df_plot4['name'], xmin=0, xmax=df_plot4['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[1,1].scatter(x=df_plot4['total'], y=df_plot4['name'], s = 75, color='#fdc100')
axes[1,1].set_title('\nTop 5 Crews in Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot4['total']):
axes[1,1].text(value+10, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Company plot
df_plot5 = pd.DataFrame(Counter(company_list).most_common(5), columns=['name', 'total']).sort_values(by='total', ascending=True)
axes[2,0].hlines(y=df_plot5['name'], xmin=0, xmax=df_plot5['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[2,0].scatter(x=df_plot5['total'], y=df_plot5['name'], s = 75, color='#fdc100')
axes[2,0].set_title('\nTop 5 Production Companies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot5['total']):
axes[2,0].text(value+50, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Country plot
df_plot6 = pd.DataFrame(Counter(country_list).most_common(5), columns=['name', 'total']).sort_values(by='total', ascending=True)
axes[2,1].hlines(y=df_plot6['name'], xmin=0, xmax=df_plot6['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[2,1].scatter(x=df_plot6['total'], y=df_plot6['name'], s = 75, color='#fdc100')
axes[2,1].set_title('\nTop 5 Production Countries\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot6['total']):
axes[2,1].text(value+900, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
sns.despine()
plt.tight_layout()上述代码的实现流程如下:
- 首先,通过 plt.subplots 创建了一个包含三行两列的子图集,设置了整个图形的大小为 (13, 10)。
- 接着,通过对不同的数据进行处理和计数,生成了五个数据框 df_plot1 到 df_plot6,每个数据框包含了不同类别的计数信息,例如口语语言、原始语言、演员、制作组成员、制作公司和制作国家。
- 然后,对每个子图使用 axes[i, j] 的方式,绘制了横向条形图和散点图,显示了每个类别中前五个最常见的元素。条形图上的水平线表示元素的计数,散点图上的点表示计数的具体值,并通过文字标签显示了具体的计数值。
- 最后,通过 sns.despine() 和 plt.tight_layout() 进行了一些样式调整,确保图形的美观性和可读性。
整体而言,这段代码创建了一个包含6个子图的可视化图,每个子图分别展示了不同类别中前五个最常见的元素,并以条形图和散点图的形式呈现。如图11-7所示。
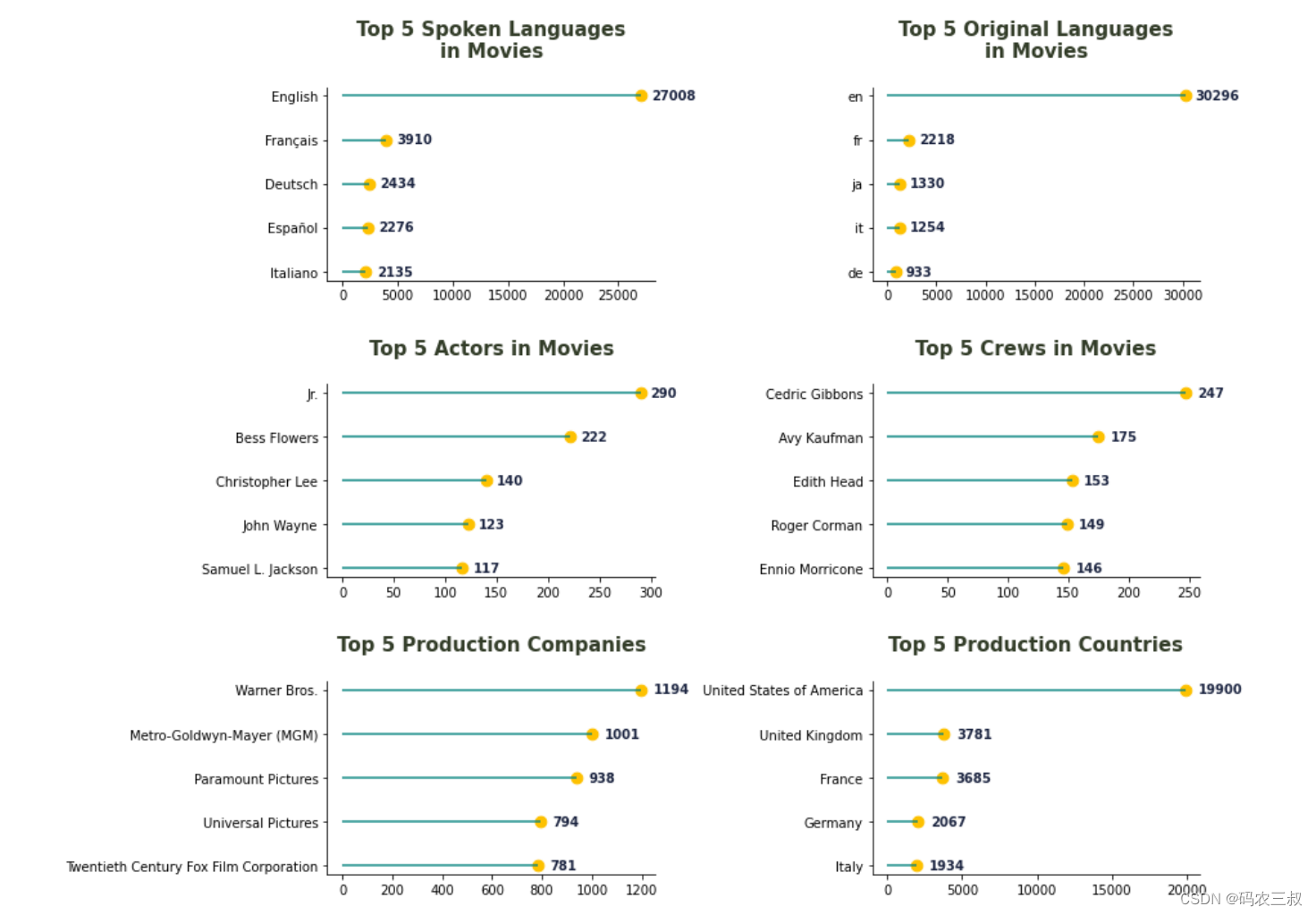
图11-7 6个子图的可视化图
通过上面的6个可视化子图可以看出:
- 在这个特定的数据集中,英语是电影中最常见的原始语言和口语语言。
- Jr. 和 Cedric Gibbons 分别是电影中涉及最多的演员和制作组成员。
- Warner Bros. 以1194部电影的数量成为列表中排名第一的制作公司。
(9)使用 seaborn 库创建了一个关系图,展示了电影评分 (vote_average) 和流行度 (popularity) 之间的关系。
sns.relplot(data=df, x='vote_average', y='popularity', size='vote_count',
sizes=(20, 200), alpha=.5, aspect=2, color='#06837f')
plt.title('The Relationship Between Rating and Popularity', fontsize=15, weight=600, color='#333d29')上述代码的实现流程如下:
- 首先,通过 sns.relplot 函数设置数据框为 df,并指定 x 轴为电影评分 (vote_average),y 轴为电影流行度 (popularity)。同时,通过 size='vote_count' 设置数据点的大小基于电影的投票数量,sizes=(20, 200) 指定了数据点的大小范围,alpha=.5 设置了数据点的透明度,aspect=2 设置了图形的纵横比,color='#06837f' 设置了整体颜色。
- 接着,在可视化图中,数据点的横坐标表示电影的评分,纵坐标表示电影的流行度。数据点的大小反映了电影的投票数量,越大表示投票数量越多。图形中的透明度为0.5,以便更好地区分重叠的数据点。
- 最后,通过 plt.title 函数添加了图形标题,描述了“评分与流行度之间的关系”。整个图形帮助观察者直观地了解电影评分与流行度之间的关联关系,以及投票数量的影响。
整体而言,这段代码创建了一个关系图,通过点的位置(评分和流行度)和大小(投票数量)直观地展示了电影评分与流行度之间的关系。如图11-8所示。
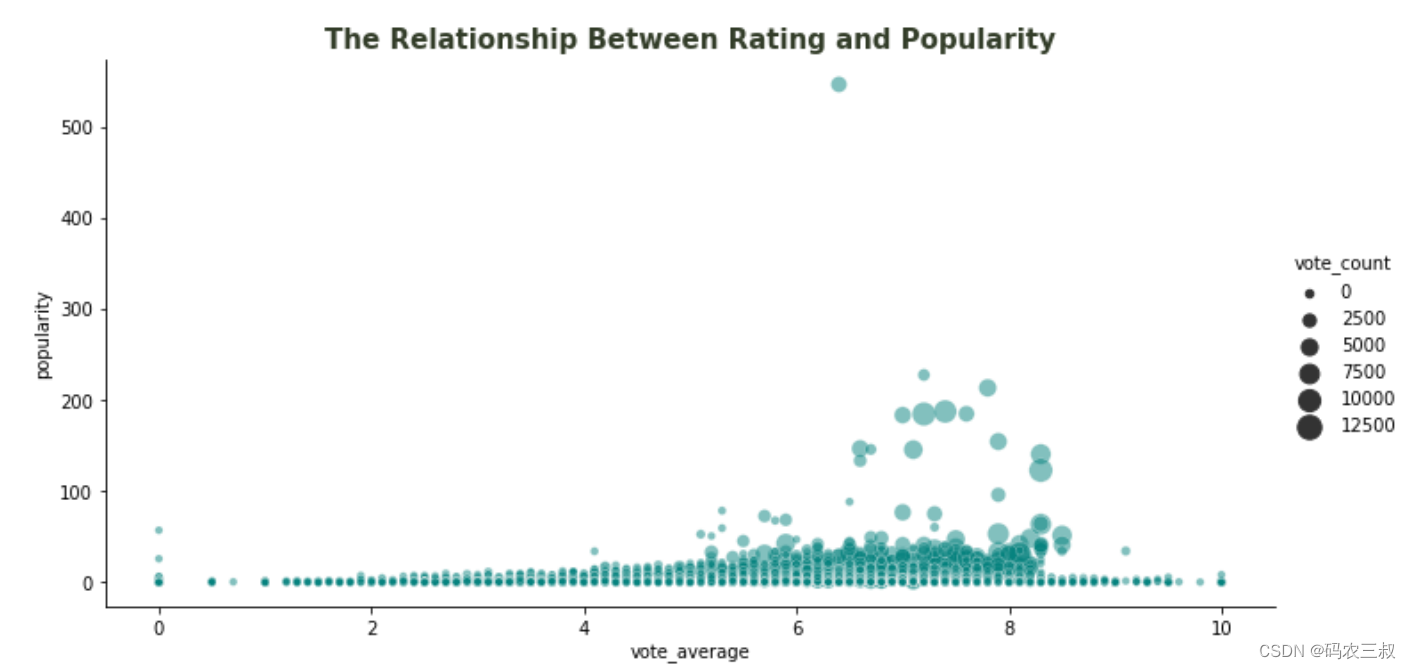
图11-8 电影评分与流行度之间的关系图
(10)对电影数据中的流派进行计数,并选择前五个最常见的流派,然后创建一个子图集,分别展示这些流派在四个不同的数据属性(时长、流行度、预算、收入)上的分布情况。
df_plot = pd.DataFrame(Counter(genres_list).most_common(5), columns=['genre', 'total'])
df_plot = df[df['genres'].isin(df_plot['genre'].to_numpy())]
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10,6))
plt.suptitle('Data Distribution Across Top 5 Genres', fontsize=18, weight=600, color='#333d29')
for i, y in enumerate(['runtime', 'popularity', 'budget', 'revenue']):
sns.stripplot(data=df_plot, x='genres', y=y, ax=axes.flatten()[i], palette=['#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811'])
plt.tight_layout()上述代码的实现流程如下:
- 首先,通过 Counter(genres_list).most_common(5) 统计了电影数据中流派的频次,并创建了一个包含前五个最常见流派的数据框 df_plot,其中包含两列,一列是流派名称 (genre),另一列是该流派出现的总次数 (total)。
- 接着,通过 df[df['genres'].isin(df_plot['genre'].to_numpy())] 从原始数据框中选择了包含前五个最常见流派的子集,并存储在 df_plot 中。
- 然后,通过 plt.subplots 创建了一个包含两行两列的子图集,总共四个子图,设置了整个图形的大小为 (10, 6)。
- 在每个子图中,通过 sns.stripplot 函数绘制了散点图,横坐标是电影的流派,纵坐标分别是电影的时长 (runtime)、流行度 (popularity)、预算 (budget)、收入 (revenue)。使用不同颜色的散点表示不同的流派,以增加可视化的区分度。
- 最后,通过 plt.tight_layout() 进行了一些样式调整,确保图形的美观性和可读性。
整体而言,这段代码创建了一个包含4个子图的可视化图形,展示了前五个最常见流派在不同数据属性上的分布情况。如图11-9所示。
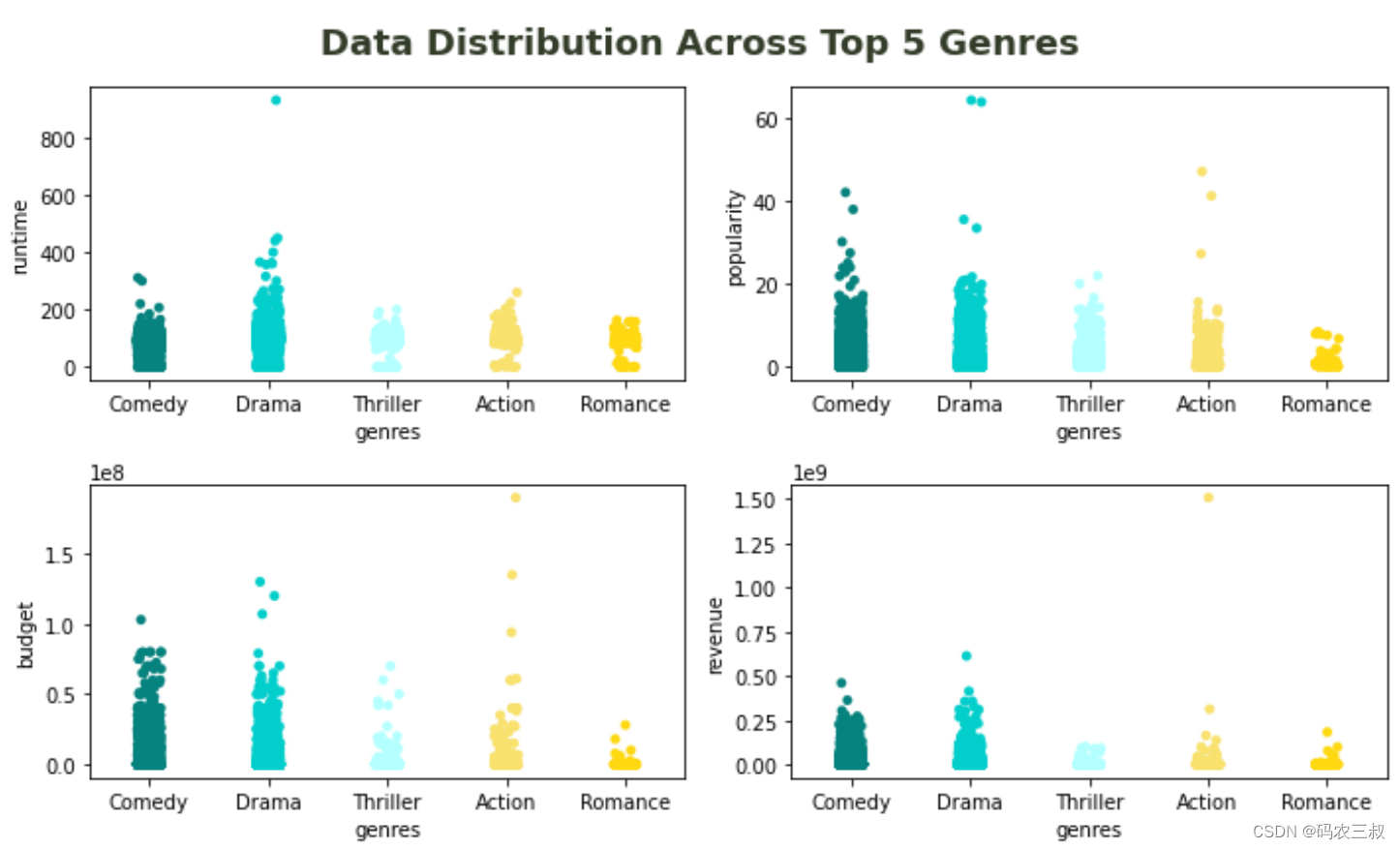
图11-9 前五个最常见流派在不同数据属性上的分布情况
通过上面的4个可视化子图可以看出:
- 电影流派中时长最长的是戏剧。
- 在前五名中,最不受欢迎的流派是浪漫片。
- 动作电影的制作成本高于其他类型的电影。
- 其中一部动作电影相较于其他电影获得了巨大的利润。
(11)创建一个热力图,用于可视化电影数据框中各个特征之间的相关性。
plt.figure(figsize=(12,10))
plt.title('Correlation of Movie Features\n', fontsize=18, weight=600, color='#333d29')
sns.heatmap(df.corr(), annot=True, cmap=['#004346', '#036666', '#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811', '#fdc100'])上述代码的实现流程如下:
- 首先,通过 plt.figure(figsize=(12,10)) 设置了图形的大小为 (12, 10)。
- 接着,通过 plt.title 添加了图形标题,描述了“电影特征的相关性”。
- 然后,使用 sns.heatmap(df.corr(), annot=True, cmap=['#004346', '#036666', '#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811', '#fdc100']) 创建了热力图。df.corr() 计算了数据框中各个特征的相关系数,并通过 annot=True 在图形中显示了相关系数的数值。cmap 参数指定了颜色映射,使用了多种颜色来表示不同的相关性程度。
- 最后,整个图形被渲染出来,呈现了电影数据中各个特征之间的相关性。热力图的颜色深浅表示相关性的强弱,数值标注在图中提供了具体的相关系数信息。
整体而言,这段代码创建了一个热力图,用于观察电影数据中特征之间的相互关系。如图11-10所示。
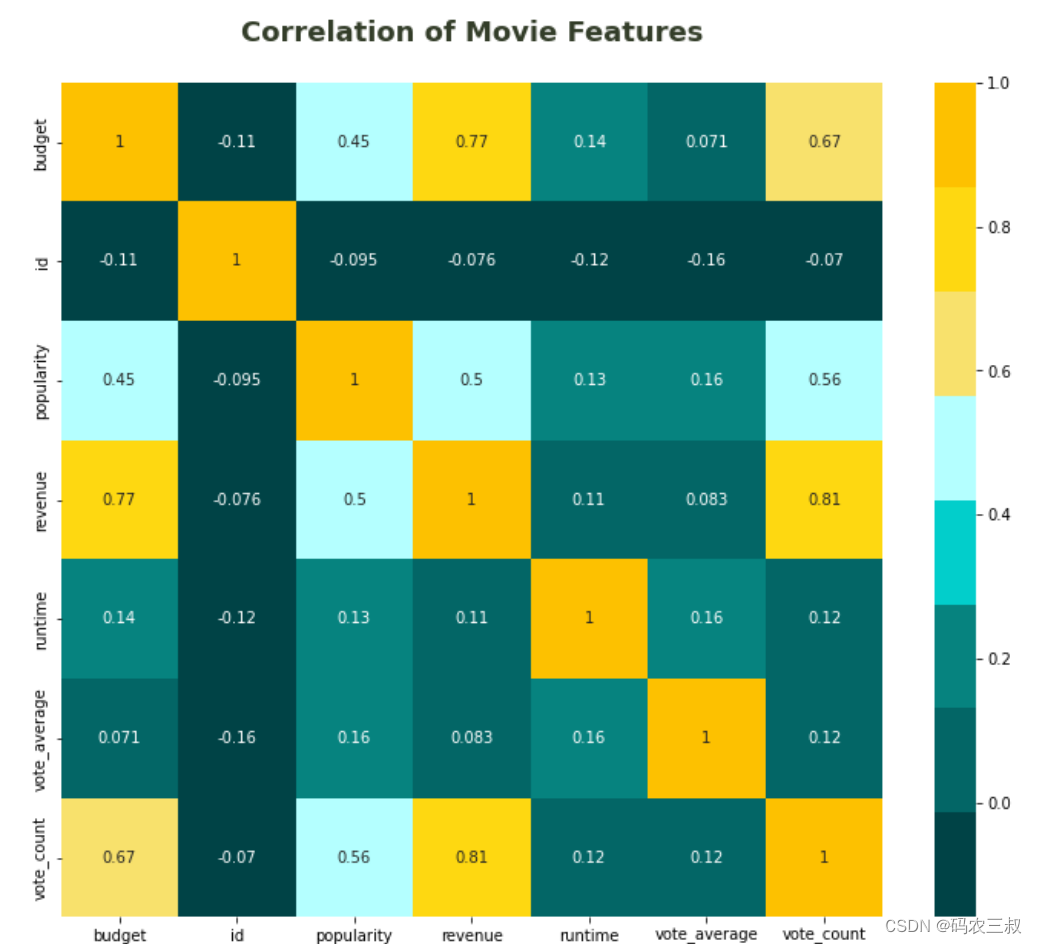
图11-10 热力图
通过上面的热力图可以看出:投票数量、预算和流行度是决定电影收入的三个主要特征。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











