







 本文详细介绍了如何在安装了Nvidia显卡和驱动的机器上,利用NVIDIA Triton推理服务器进行模型部署,包括从克隆模型库、启动服务器到客户端调用的步骤,并展示了使用DenseNet onnx模型的实例。重点涵盖了CUDA驱动、docker容器和NVIDIA Container Toolkit的应用。
本文详细介绍了如何在安装了Nvidia显卡和驱动的机器上,利用NVIDIA Triton推理服务器进行模型部署,包括从克隆模型库、启动服务器到客户端调用的步骤,并展示了使用DenseNet onnx模型的实例。重点涵盖了CUDA驱动、docker容器和NVIDIA Container Toolkit的应用。
前置条件
安装Nvidia显卡的机器,安装最新的显卡驱动
可以根据自己的操作系统和显卡型号选择对应的cuda驱动下载
Frameworks Support Matrix :: NVIDIA Deep Learning Frameworks Documentation
安装:
docker
安装:NVIDIA Container Toolkit
GitHub - NVIDIA/nvidia-docker: Build and run Docker containers leveraging NVIDIA GPUs
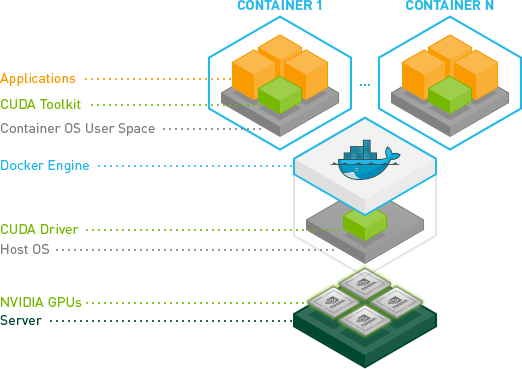
Triton Architecture
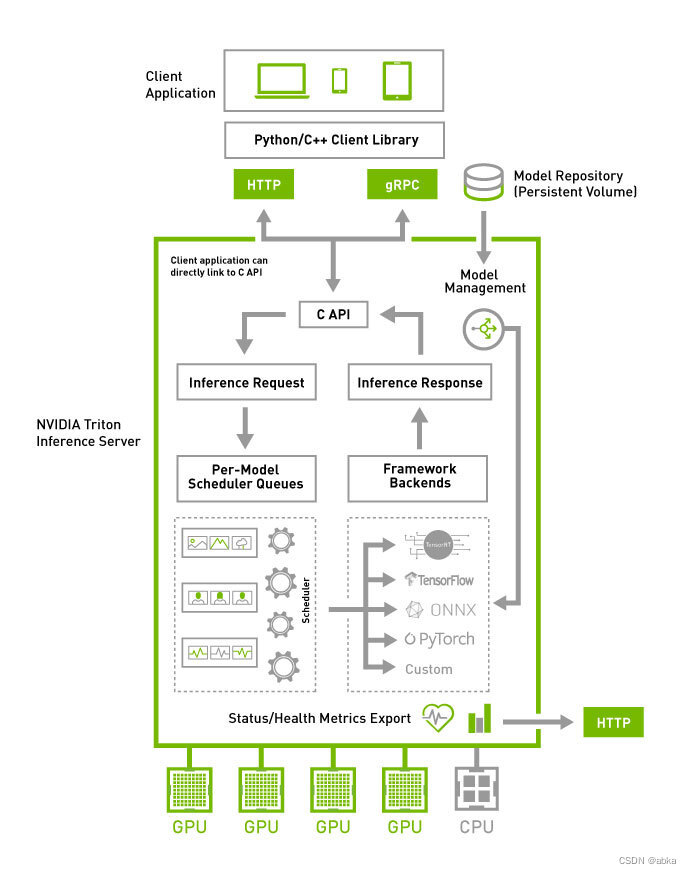
server/architecture.md at main · triton-inference-server/server · GitHub
文档上面说也可以支持纯cpu版本,笔者没有测试
1. clone 代码,获取模型样例
# Step 1: Create the example model repository
git clone -b r22.05 https://github.com/triton-inference-server/server.git
cd server/docs/examples
./fetch_models.sh
2. 启动triton 推理服务器,使用指定的
/full/path/to/docs/examples/model_repository 是上面的目录,替换即可
# Step 2: Launch triton from the NGC Triton container
docker run --gpus=1 --rm --net=host -v /full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:22.05-py3 tritonserver --model-repository=/models
3. 启动client调用triton服务
# Step 3: In a separate console, launch the image_client example from the NGC Triton SDK container
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:22.05-py3-sdk
# 执行上面的命令会进入命令行
# /workspace/# 直接执行下面命令即可
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
返回结果如下:
# Inference should return the following
Image '/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT参考:
server/quickstart.md at main · triton-inference-server/server · GitHub
server/architecture.md at main · triton-inference-server/server · GitHub
Installation Guide — NVIDIA Cloud Native Technologies documentation

















 2762
2762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









