







在Spark使用iceberg中,提供了Spark Procedures去获取iceberg的存储过程数据,包括快照管理、分支管理、元数据管理、以及变更数据的轨迹表获取。
轨迹表的生存逻辑如下:
可以通过指定快照ID,获取两个快照之前的数据变化轨迹;或者指定时间戳,获取指定时间范围的数据变化轨迹。能够捕捉数据的增、删、改。通过下面SQL能够创建一个临时视图获取数据变化轨迹。
注意:默认创建的是临时视图,只在当前会话有效,所以如果需要查询结果,以下两个SQL需同时运行。
-- 指定快照ID,结束快照ID如果不指定,则默认为当前快照ID
CALL spark_catalog.system.create_changelog_view(
table => 'credit_card_ms02_test1.sample2',
changelog_view => 'my_changelog_view',
options => map('start-snapshot-id','6816102630015607376'),
identifier_columns => array('id')
);
select a.*,b.committed_at from my_changelog_view a
join credit_card_ms02_test1.sample2.snapshots b on a._commit_snapshot_id=b.snapshot_id;
参数详解:
table:必输,表名。指定库名+表名。
changelog_view:创建视图的名称。
options:map类型,配置选项。
identifier_columns:用于捕捉数据变化的标识列。可设置为主键,捕捉这条记录的增、删、改。
-- 指定时间戳,结束时间戳未指定,默认为当前时间戳
CALL spark_catalog.system.create_changelog_view(
table => 'credit_card_ms02_test1.sample2',
changelog_view => 'my_changelog_view',
options => map('start-timestamp','1745769600000'),
identifier_columns => array('id')
);
select a.*,b.committed_at from my_changelog_view a
join credit_card_ms02_test1.sample2.snapshots b on a._commit_snapshot_id=b.snapshot_id;
查询结果:
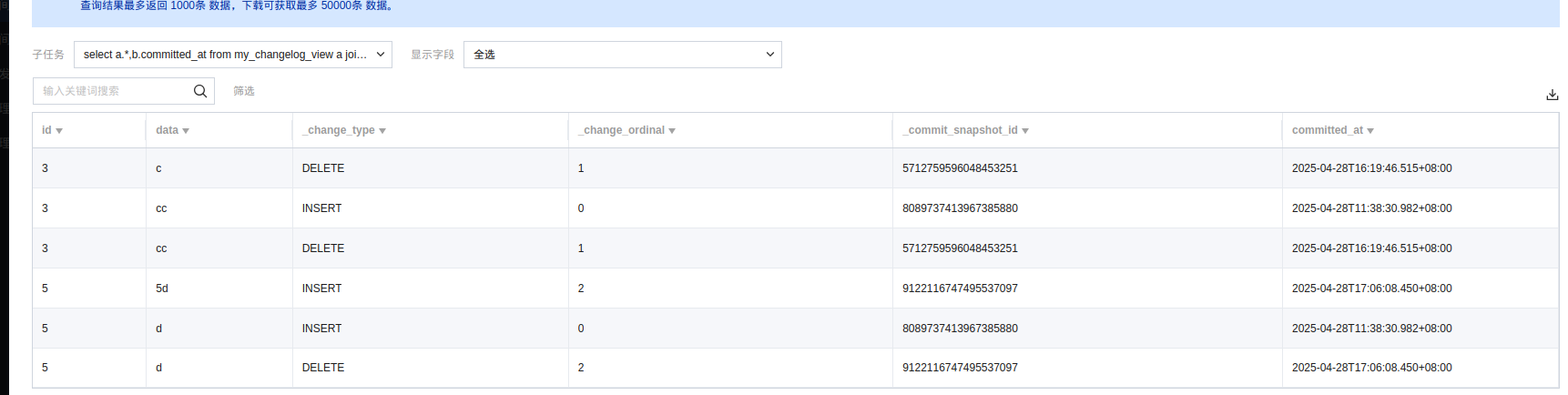
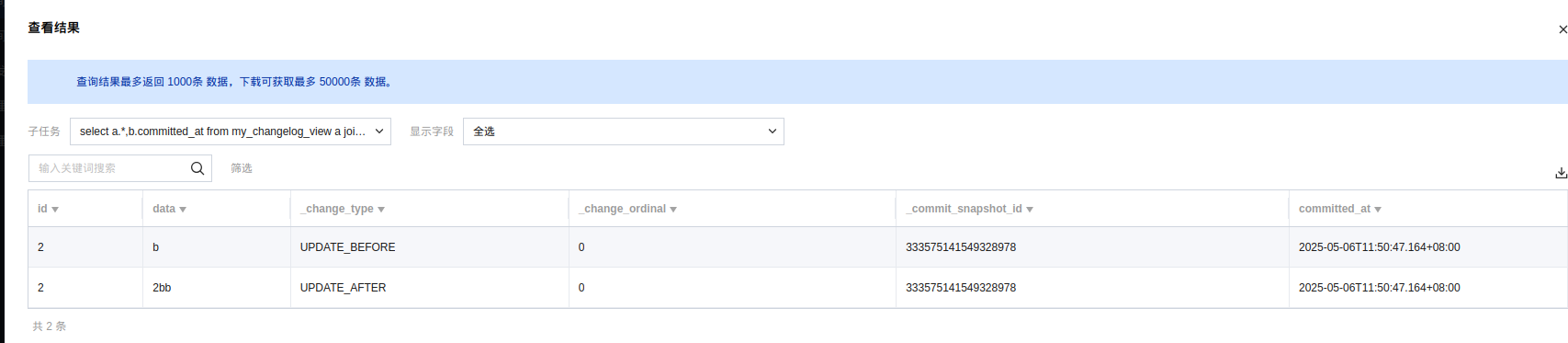
查询结果字段详解:
_change_ordinal:更改顺序,从0开始。
_commit_snapshot_id:发生更改的快照 ID
_change_type:更改的类型。它具有以下值之一:INSERT、DELETE、UPDATE_BEFORE 或 UPDATE_AFTER。

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









