







目录
一、边缘检测
边缘检测通常是在保留原有图像属性的情况下,对图像数据规模进行缩减,提取图像边缘轮廓的处理方式。边缘检测算法主要是基于图像强度的一阶和二阶导数,但导数通常对噪声很敏感,因此需要采用滤波器来过滤噪声,并调用图像增强或阈值化算法进行处理,最后再进行边缘检测。
1、Roberts算子
Roberts算子又称为交叉微分算法,它是基于交叉差分的梯度算法,通过局部差分计算检测边缘线条。常用来处理具有陡峭的低噪声图像,当图像边缘接近于正45度或负45度时,该算法处理效果更理想。其缺点是对边缘的定位不太准确,提取的边缘线条较粗。Roberts算子的模板分为水平方向和垂直方向。
Roberts算子主要通过Numpy定义模板,再调用OpenCV的filter2D()函数实现边缘提取。该函数主要是利用内核实现对图像的卷积运算,其函数原型如下所示:dst = filter2D(src, ddepth, kernel, anchor, delta, borderType) 其中,src表示输入图像,dst表示输出的边缘图,其大小和通道数与输入图像相同,ddepth表示目标图像所需的深度,kernel表示卷积核,一个单通道浮点型矩阵,anchor表示内核的基准点,其默认值为(-1,-1),位于中心位置,delta表示在储存目标图像前可选的添加到像素的值,默认值为0,borderType表示边框模式。
2、Prewitt算子
Prewitt是一种图像边缘检测的微分算子,其原理是利用特定区域内像素灰度值产生的差分实现边缘检测。由于Prewitt算子采用3*3模板对区域内的像素值进行计算,而Robert算子的模板为2*2,故Prewitt算子的边缘检测结果在水平方向和垂直方向均比Robert算子更加明显。Prewitt算子适合用来识别噪声较多、灰度渐变的图像。
在Python中,Prewitt算子的实现过程与Roberts算子比较相似。通过Numpy定义模板,再调用OpenCV的filter2D()函数实现对图像的卷积运算,最终通过convertScaleAbs()和addWeighted()函数实现边缘提取。
3、Sobel算子
Sobel算子是一种用于边缘检测的离散微分算子,它结合了高斯平滑和微分求导。该算子用于计算图像明暗程度近似值,根据图像边缘旁边明暗程度把该区域内超过某个数的特定点记为边缘。Sobel算子在Prewitt算子的基础上增加了权重的概念,认为相邻点的距离远近对当前像素点的影响是不同的,距离越近的像素点对应当前像素的影响越大,从而实现图像锐化并突出边缘轮廓。Sobel算子的边缘定位更准确,常用于噪声较多、灰度渐变的图像。
Sobel算子根据像素点上下、左右邻点灰度加权差,在边缘处达到极值这一现象检测边缘。对噪声具有平滑作用,提供较为精确的边缘方向信息。因为Sobel算子结合了高斯平滑和微分求导(分化),因此结果会具有更多的抗噪性,当对精度要求不是很高时,Sobel算子是一种较为常用的边缘检测方法。
函数原型为:dst = cv2.Sobel(src, ddepth, dx, dy, ksize, scale, delta, borderType) 其中,src表示输入图像,dst表示输出的边缘图,其大小和通道数与输入图像相同,ddepth表示目标图像所需的深度,针对不同的输入图像,输出目标图像有不同的深度,dx表示x方向上的差分阶数,取值1或 0,dy表示y方向上的差分阶数,取值1或0,ksize表示Sobel算子的大小,其值必须是正数和奇数,scale表示缩放导数的比例常数,默认情况下没有伸缩系数,delta表示将结果存入目标图像之前,添加到结果中的可选增量值,borderType表示边框模式。
4、Laplacian算子
拉普拉斯(Laplacian)算子是n维欧几里德空间中的一个二阶微分算子,常用于图像增强领域和边缘提取。它通过灰度差分计算邻域内的像素,基本流程是:判断图像中心像素灰度值与它周围其他像素的灰度值,如果中心像素的灰度更高,则提升中心像素的灰度;反之降低中心像素的灰度,从而实现图像锐化操作。在算法实现过程中,Laplacian算子通过对邻域中心像素的四方向或八方向求梯度,再将梯度相加起来判断中心像素灰度与邻域内其他像素灰度的关系,最后通过梯度运算的结果对像素灰度进行调整。Laplacian算子分为四邻域和八邻域,四邻域是对邻域中心像素的四方向求梯度,八邻域是对八方向求梯度。
5、Scharr算子
Scharr算子又称为Scharr滤波器,也是计算x或y方向上的图像差分。由于Sobel算子在计算相对较小的核的时候,其近似计算导数的精度比较低,比如一个3*3的Sobel算子,当梯度角度接近水平或垂直方向时,其不精确性就越发明显。Scharr算子同Sobel算子的速度一样快,但是准确率更高,尤其是计算较小核的情景,所以利用3*3滤波器实现图像边缘提取更推荐使用Scharr算子。
6、Canny边缘检测
Canny算法是一种被广泛应用于边缘检测的标准算法,其目标是找到一个最优的边缘检测解或找寻一幅图像中灰度强度变化最强的位置。最优边缘检测主要通过低错误率、高定位性和最小响应三个标准进行评价。
Canny边缘检测的实现步骤如下:
- 使用高斯滤波器,以平滑图像,滤除噪声。
- 计算图像中每个像素点的梯度强度和方向(梯度方向一般取0度、45度、90度和135度四个方向)。
- 应用非极大值(Non-Maximum Suppression)抑制,过滤掉非边缘像素,将模糊的边界变得清晰。该过程保留了每个像素点上梯度强度的极大值,过滤掉其他的值。
- 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘(利用双阈值方法来确定潜在的边界。经过非极大抑制后图像中仍然有很多噪声点,此时需要通过双阈值技术处理,即设定一个阈值上界和阈值下界。图像中的像素点如果大于阈值上界则认为必然是边界(称为强边界,strong edge),小于阈值下界则认为必然不是边界,两者之间的则认为是候选项(称为弱边界,weak edge))。
- 通过抑制孤立的弱边缘最终完成边缘检测(利用滞后技术来跟踪边界。若某一像素位置和强边界相连的弱边界认为是边界,其他的弱边界则被删除)。
在OpenCV中,Canny()函数原型为:edges = cv2.Canny(image, threshold1, threshold2, apertureSize, L2gradient)其中,image表示输入图像,edges表示输出的边缘图,其大小和类型与输入图像相同,threshold1表示第一个滞后性阈值,threshold2表示第二个滞后性阈值,apertureSize表示应用Sobel算子的孔径大小,其默认值为3,L2gradient表示一个计算图像梯度幅值的标识,默认值为false。
7、LOG边缘检测
LOG(Laplacian of Gaussian)边缘检测算子是也称为Marr & Hildreth算子,它根据图像的信噪比来求检测边缘的最优滤波器。该算法首先对图像做高斯滤波,然后再求其拉普拉斯(Laplacian)二阶导数,根据二阶导数的过零点来检测图像的边界,即通过检测滤波结果的零交叉(Zero crossings)来获得图像或物体的边缘。
LOG算子该综合考虑了对噪声的抑制和对边缘的检测两个方面,并且把Gauss平滑滤波器和Laplacian锐化滤波器结合了起来,先平滑掉噪声,再进行边缘检测,所以效果会更好。 该算子与视觉生理中的数学模型相似,因此在图像处理领域中得到了广泛的应用。它具有抗干扰能力强,边界定位精度高,边缘连续性好,能有效提取对比度弱的边界等特点。
代码实现如下:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取图像
img = cv2.imread('img/cute.png')
cute_img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#灰度化处理图像
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#高斯滤波
gaussianBlur = cv2.GaussianBlur(grayImage, (3,3), 0)
#阈值处理
ret, binary = cv2.threshold(gaussianBlur, 127, 255, cv2.THRESH_BINARY)
#Roberts算子
kernelx = np.array([[-1,0],[0,1]], dtype=int)
kernely = np.array([[0,-1],[1,0]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x) #计算绝对值,并将图像转换为8位图进行显示
absY = cv2.convertScaleAbs(y)
Roberts = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Prewitt算子
kernelx = np.array([[1,1,1],[0,0,0],[-1,-1,-1]], dtype=int)
kernely = np.array([[-1,0,1],[-1,0,1],[-1,0,1]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Prewitt = cv2.addWeighted(absX,0.5,absY,0.5,0)
#Sobel算子
x = cv2.Sobel(binary, cv2.CV_16S, 1, 0,ksize=3)
y = cv2.Sobel(binary, cv2.CV_16S, 0, 1,ksize=3)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Sobel = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#拉普拉斯算法
dst = cv2.Laplacian(binary, cv2.CV_16S, ksize = 3)
Laplacian = cv2.convertScaleAbs(dst)
# Scharr算子
x = cv2.Scharr(binary, cv2.CV_32F, 1, 0) #X方向
y = cv2.Scharr(binary, cv2.CV_32F, 0, 1) #Y方向
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Scharr = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Canny算子
gaussian = cv2.GaussianBlur(grayImage, (3,3), 0) #高斯滤波降噪
Canny = cv2.Canny(gaussian, 50, 150)
#LOG算子
gaussian = cv2.GaussianBlur(grayImage, (3,3), 0) #先通过高斯滤波降噪
dst = cv2.Laplacian(gaussian, cv2.CV_16S, ksize = 3) #再通过拉普拉斯算子做边缘检测
LOG = cv2.convertScaleAbs(dst)
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#效果图
titles = ['Source Image', 'Binary Image', 'Roberts Image',
'Prewitt Image','Sobel Image', 'Laplacian Image',
'Scharr Image','Canny Image','LOG算子']
images = [cute_img, binary, Roberts, Prewitt, Sobel, Laplacian, Scharr,Canny,LOG]
for i in np.arange(9):
plt.subplot(3,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
结果如下:

二、图像金字塔
图像金字塔是指由一组图像且不同分别率的子图集合,它是图像多尺度表达的一种,以多分辨率来解释图像的结构,主要用于图像的分割或压缩。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。
高斯金字塔:向下采样(缩小),它将对图像进行高斯核卷积,并删除原图中所有的偶数行和列,最终缩小图像。由于每次向下取样会删除偶数行和列,所以它会不停地丢失图像的信息。在向下采样中,层级越高,则图像越小,分辨率越低。在OpenCV中,向下取样使用的函数为cv2.pyrDown()。
高斯金字塔:向上采样(放大),在图像向上取样是由小图像不断放图像的过程。它将图像在每个方向上扩大为原图像的2倍,新增的行和列均用0来填充,并使用与“向下取样”相同的卷积核乘以4,再与放大后的图像进行卷积运算,以获得“新增像素”的新值。在OpenCV中,向上取样使用的函数为cv2.pyrUp()。
拉普拉斯金字塔:对图像先进行向下采样,然后再向上采样得到结果,最后使用原图像减去该结果。img-pyrdown(pyrup)
# -*- coding: utf-8 -*-
import cv2
import matplotlib.pyplot as plt
#读取原始图像
img = cv2.imread('img/cute.png')
img_cute=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#图像先向下取样再向上取样
down=cv2.pyrDown(img)
down_up=cv2.pyrUp(down)
img_new=img-down_up
#显示图像
images=[img_cute,img_new]
for i in range(2):
plt.subplot(1,2,i+1)
plt.imshow(images[i])
plt.show()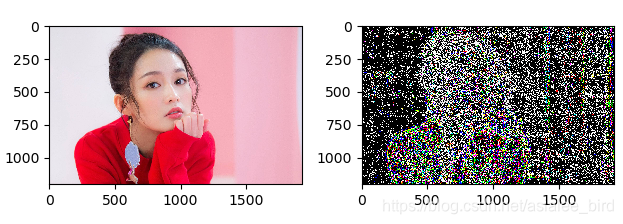
三、图像轮廓检测
图像轮廓检测函数:cv2.findContours(img,mode,method)
mode:轮廓检索模式
- RETR_EXTERNAL :只检索最外面的轮廓;
- RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
- RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
- RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;
method:轮廓逼近方法
- CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
- CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
1、绘制图像轮廓
# -*- coding: utf-8 -*-
import cv2
import numpy as np
#显示图像
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
#图像轮廓
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt=contours[0] #获取图像轮廓中的第一个
area=cv2.contourArea(cnt) #计算某个轮廓的面积
print(area) #8500.5
arclen=cv2.arcLength(cnt,True) #计算某个轮廓的周长,True表示闭合的
print(arclen) #437.9482651948929
#绘制图像轮廓,传入绘制图像,轮廓,轮廓索引,颜色模式,线条厚度
# 注意需要copy,要不原图会变。
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 1) #绘制图像中的所有轮廓
#res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2) #绘制图形中的一个轮廓
cv_show('thresh',res)
2、轮廓近似绘制
# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('data/contours2.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
epsilon = 0.15*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True) #多边形逼近函数,轮廓近似
draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show('res',res)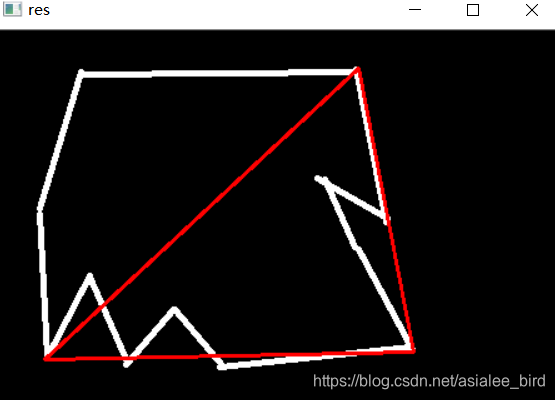
3、画轮廓边界矩形框
# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show('img',img)
#求轮廓面积与边界矩形比
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print ('轮廓面积与边界矩形比',extent) #轮廓面积与边界矩形比 0.5154317244724715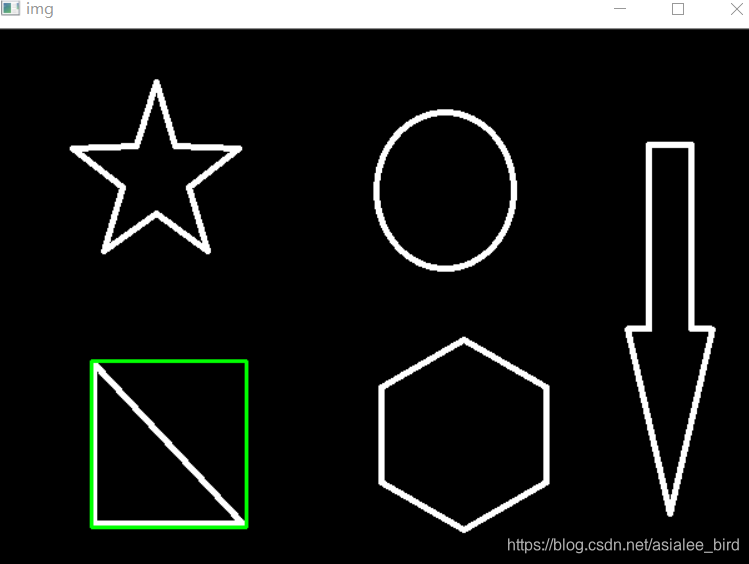
- cv2.boundingRect(img)函数:img是一个二值图,函数返回四个值,分别是x,y,w,h;x,y是矩阵左上点的坐标,w,h是矩阵的宽和高。
- cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)画出矩形:img是原图,(x,y)是矩阵的左上点坐标,(x+w,y+h)是矩阵的右下点坐标,(0,255,0)是画线对应的rgb颜色,2是所画的线的宽度。
4、画轮廓外接圆
# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show('img',img)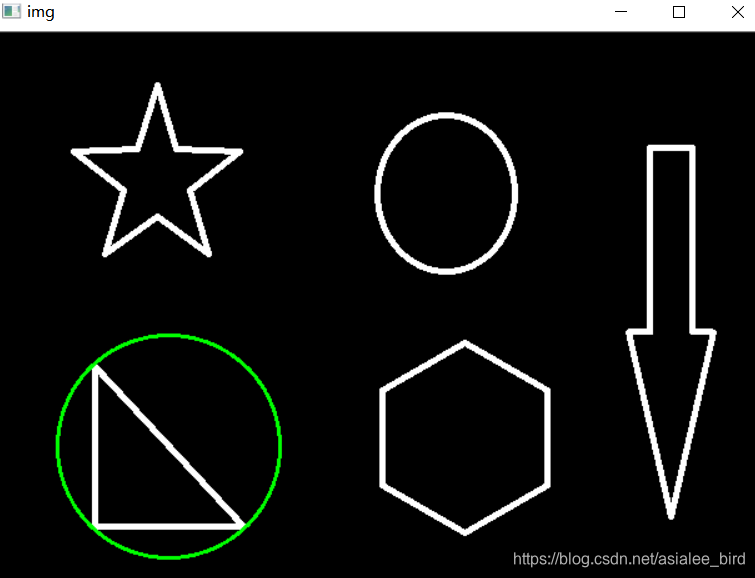
四、背景建模
1、帧差法
由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。帧差法非常简单,但是会引入噪音和空洞问题。
2、混合高斯模型
在进行前景检测前,先对背景进行训练,对图像中每个背景采用一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应。然后在测试阶段,对新来的像素进行GMM匹配,如果该像素值能够匹配其中一个高斯,则认为是背景,否则认为是前景。由于整个过程GMM模型在不断更新学习中,所以对动态背景有一定的鲁棒性。最后通过对一个有树枝摇摆的动态背景进行前景检测,取得了较好的效果。
在视频中对于像素点的变化情况应当是符合高斯分布,背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型也可以带有权重。
混合高斯模型学习方法:(1)首先初始化每个高斯模型矩阵参数;(2)取视频中T帧数据图像用来训练高斯混合模型。来了第一个像素之后用它来当做第一个高斯分布;(3)当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3倍的方差内,则属于该分布,并对其进行参数更新;(4)如果下一次来的像素不满足当前高斯分布,用它来创建一个新的高斯分布。
混合高斯模型测试方法:在测试阶段,对新来像素点的值与混合高斯模型中的每一个均值进行比较,如果其差值在2倍的方差之间的话,则认为是背景,否则认为是前景。将前景赋值为255,背景赋值为0。这样就形成了一副前景二值图。
3、背景建模实战
import numpy as np
import cv2
#测试视频
cap = cv2.VideoCapture('data/test.avi')
#形态学操作需要使用
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
#创建混合高斯模型用于背景建模
fgbg = cv2.createBackgroundSubtractorMOG2()
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)#前景赋值为255,背景赋值为0
#形态学开运算去噪点
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
#寻找视频中的轮廓
contours,hierarchy = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
#找到一个直矩形(不会旋转)
x,y,w,h = cv2.boundingRect(c)
#画出这个矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
cv2.imshow('fgmask', fgmask)
k = cv2.waitKey(150) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()五、光流估计
光流是空间运动物体在观测成像平面上的像素运动的“瞬时速度”,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如目标跟踪。
光流估计前提条件:
- 亮度恒定:同一点随着时间的变化,其亮度不会发生改变。
- 小运动:随着时间的变化不会引起位置的剧烈变化,只有小运动情况下才能用前后帧之间单位位置变化引起的灰度变化去近似灰度对位置的偏导数。
- 空间一致:一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。因为光流法基本方程约束只有一个,而要求x,y方向的速度,有两个未知变量。所以需要连立n多个方程求解。
import numpy as np
import cv2
cap = cv2.VideoCapture('test.avi')
# 角点检测所需参数
feature_params = dict( maxCorners = 100, qualityLevel = 0.3, minDistance = 7)
# lucas kanade参数
lk_params = dict( winSize = (15,15),maxLevel = 2)
# 随机颜色条
color = np.random.randint(0,255,(100,3))
# 拿到第一帧图像
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 返回所有检测特征点,需要输入图像,角点最大数量(效率),品质因子(特征值越大的越好,来筛选)
# 距离相当于这区间有比这个角点强的,就不要这个弱的了
p0 = cv2.goodFeaturesToTrack(old_gray, mask = None, **feature_params)
# 创建一个mask
mask = np.zeros_like(old_frame)
while(True):
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 需要传入前一帧和当前图像以及前一帧检测到的角点
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# st=1表示
good_new = p1[st==1]
good_old = p0[st==1]
# 绘制轨迹
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv2.line(mask, (a,b),(c,d), color[i].tolist(), 2)
frame = cv2.circle(frame,(a,b),5,color[i].tolist(),-1)
img = cv2.add(frame,mask)
cv2.imshow('frame',img)
k = cv2.waitKey(150) & 0xff
if k == 27:
break
# 更新
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
cv2.destroyAllWindows()
cap.release()- cv2.calcOpticalFlowPyrLK():参数:prevImage 前一帧图像,nextImage 当前帧图像,prevPts 待跟踪的特征点向量,winSize 搜索窗口的大小,maxLevel 最大的金字塔层数;返回:nextPts 输出跟踪特征点向量,status 特征点是否找到,找到的状态为1,未找到的状态为0


















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











