







自从DETR问询式检测器首次亮相以来,基于查询的方法在目标检测中引起了广泛关注。然而,这些方法面临着收敛速度慢和性能亚优等挑战。值得注意的是,在目标检测中,自注意力机制经常因其全局聚焦而妨碍了收敛。为了解决这些问题,作者提出了FoLR,一种仅包含解码器的类似Transformer的架构。作者通过隔离不相关目标之间的连接来增强自注意力机制,使其聚焦于局部区域而不是全局区域。作者还设计了自适应采样方法,从特征图中基于查询的局部区域提取有效特征。此外,作者采用了一种解码器的回溯策略,以保留先前的信息,然后使用特征混合器模块来融合特征和查询。实验结果表明,FoLR在基于查询的检测器中表现出卓越的性能,具有卓越的收敛速度和计算效率。
1. INTRODUCTION
通用目标检测旨在定位和分类图像中的现有目标,并使用矩形边界框对它们进行标记以显示存在的置信度。这些方法的框架主要可以分为两种类型:一阶段方法,如SSD和YOLO,以及多阶段检测器,如Faster R-CNN。最近,基于Transformer的目标检测器引起了关注,DETR引入了Transformer的编码器-解码器模块到目标检测中。与传统检测器不同,DETR消除了对Anchor Box设计的需求,依赖于一组可学习的向量,称为目标查询,用于检测。然而,DETR在收敛速度慢和性能问题方面面临挑战。具体来说,在COCO 2017数据集上取得与以前检测器相媲美的结果需要DETR训练超过500个Epoch,而Faster R-CNN通常只需要12个Epoch。
为了应对这一挑战,一些研究已经提出了解决这些问题的方法。然而,这些方法往往引入了大量的额外参数,增加了网络的大小,显著提高了训练成本。因此,在收敛速度和计算复杂性之间取得适当平衡仍然是一个挑战。此外,包含全局信息的注意力机制可以快速建立不相关目标之间的关联,对算法的收敛产生负面影响。这促使作者对全局信息的注意力机制进行了研究和增强。
在本文中,作者提出了FoLR,这是一种旨在解决上述挑战的新型基于查询的检测器。总之,作者的工作做出了以下贡献:
-
引入FoLR,这是一种新型的基于查询的目标检测方法,具有简化的解码器架构,可以增强自注意力与局部区域的交互。
-
设计和实现了Feature Mixer模块和基于DCN的自适应采样方法,以增强特征和查询之间的交互。此外,作者采用“回顾”策略来保留在先前阶段生成的数据。
-
通过在COCO数据集上的实验结果展示了FoLR的卓越性能,它有效地克服了传统方法在收敛速度缓慢和计算成本高的限制。
2. RELATED WORK
这部分跳过......
3. METHOD
3.1. Overview
在本节中,作者详细介绍了作者的基于查询的检测器FoLR。FoLR是一个完全的解码器架构,包括以下几个关键组件:
-
带有局部区域的自注意力:该模块增强了查询的描述能力,代表目标的位置和语义信息。同时,它旨在减轻不相关查询之间的负面关系。
-
自适应采样方法(ASM):它有助于根据查询的位置从多尺度特征图中自适应地采样特征。
-
特征混合器:该组件促进了在ASM中采样的特征与查询之间的互动,实现了有效的信息融合。
-
预测Head:这些Head负责完成分类和回归任务。
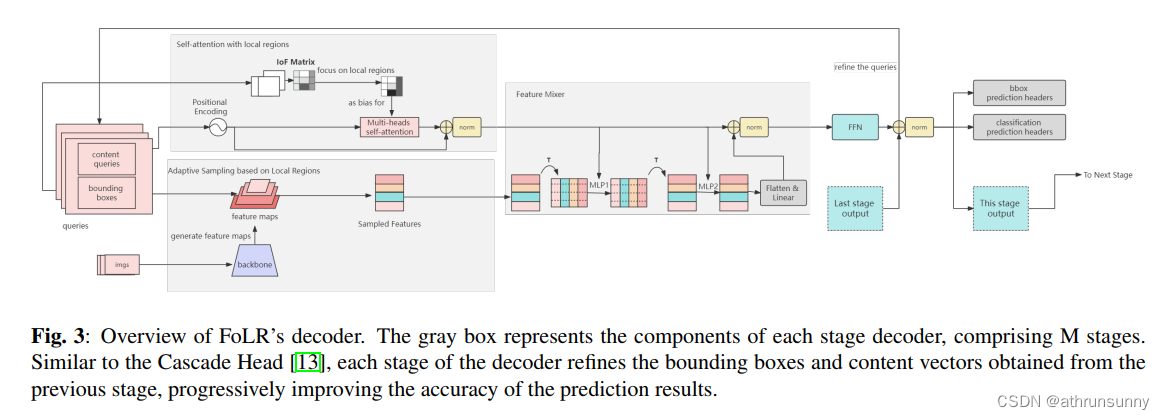
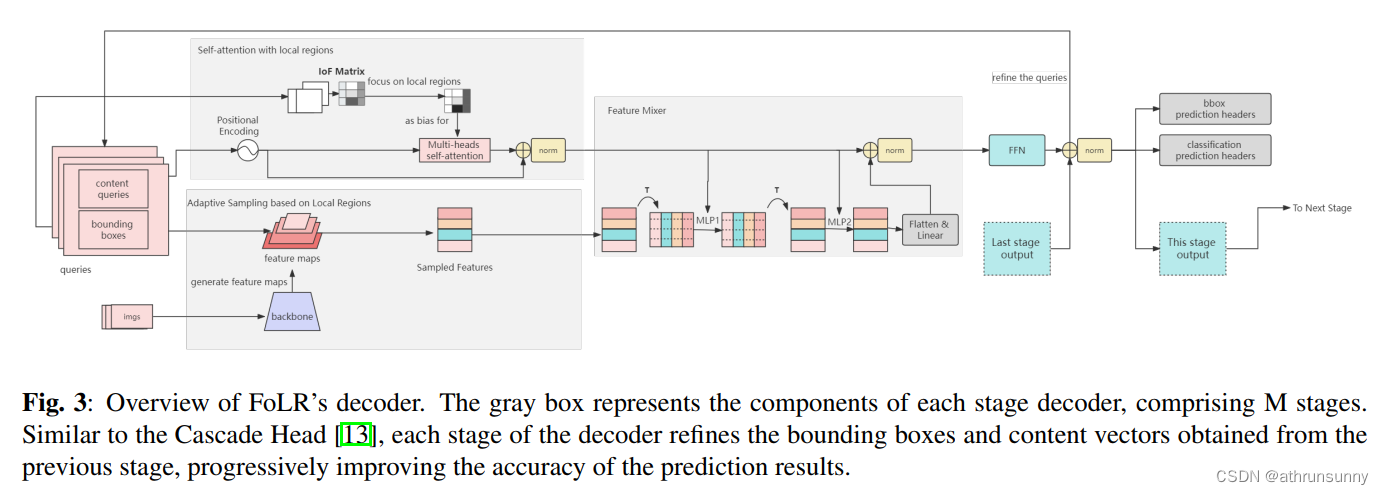
这些组件的相互作用塑造了FoLR的整体架构,赋予其有效提取特征和检测目标的能力。架构的视觉表示如图3所示。此外,FoLR采用了受Cascade R-CNN启发的多阶段细化策略。查询向量可以在每个后续阶段迭代地进行细化,以增强目标检测的准确性,如图2所示。

解耦分类和定位 在本文提出的方法中,作者利用了查询的概念,它合并了每个目标的语义和位置信息,就像Sparse RCNN等基于Transformer的算法中所看到的那样。先前的研究表明,将查询分解为这两个向量显著提高了模型的识别效率。作者通过将查询分解为两个不同的向量来扩展这种方法:内容向量(content vector)和边界框向量(bounding box vector)。
损失 模型的损失,采用DETR方法计算,包括用于预测分类的Focal Loss(),用于预测框坐标的L1损失(
)和GIoU(
)。总损失如下:
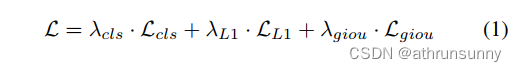
3.2. Self-Attention with Local Regions
自注意力是Transformer样式方法中常用的机制,用于增强查询的描述能力。它有助于在序列内建立关系。在目标检测任务中,自注意力增强了每个查询与其他查询之间的连接,增强了内容向量的描述能力。然而,作者的研究发现,这种具有全局焦点的注意力机制甚至建立了不相关查询之间的连接,如图1所示。这阻碍了检测任务,对模型产生了负面影响。

为了使模型能够识别和屏蔽负面连接,作者鼓励自注意力集中在局部区域。首先,作者使用方程2计算每个查询与其他查询之间的IoF(帧交集 (Intersection of Frame))矩阵。如果矩阵元素的值低于指定的阈值ε,作者将其替换为一个较大的负数。这表示该信息对于自注意力是有害的,应在后续操作中排除。
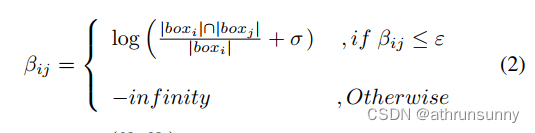
其中,由
和
索引,
是查询的数量,σ是一个设置为
的小常数,ε是从间隔[0,1]中取的一个常数。
3.3. Extract Multi-Scale Features
为了增强每个查询的有效性,从每个输入图像的Backbone生成的有意义和丰富的特征是至关重要的。在本节中,作者介绍了一种受可变卷积网络启发的自适应采样方法来提取特征。
Adaptive Sampling Method (ASM) 给定第i个边界框,作者使用以下方程来生成第个对应的采样点:
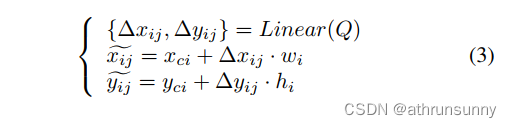
其中,Q代表内容向量。和
表示第j个采样点相对于第i个边界框的中心点
的偏移,
和
分别表示第
个边界框的宽度和高度。
Focus on Local Regions.
现在作者已经在特征图上获得了采样点,Sparse RCNN和AdaMixer的下一步涉及与查询交互地融合这些采样点。然而,作者认为以这种方式收集的特征是从特征图派生的,而不是从查询派生的。
与DETR的解码器在目标查询上应用位置编码类似,作者的方法旨在改进收集的采样点,以更好地与查询集成。在这里,作者使用线性层生成的一组参数来增强采样点:
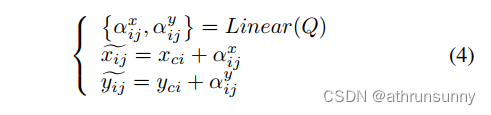
在作者的方法中,作者采用双线性插值方法来处理采样点的小数坐标。此外,作者采用了类似于自注意力中使用的多头机制的策略,以增强采样点的多样性。
具体来说,作者将特征图的维度,表示为d,分成个Head,其中每个头分配
个维度。这种划分确保每个头捕捉到特征的不同方面。对于本研究,作者保持d = 256和
= 4。
实际上,作者在每个特征图级别的每个查询中生成个采样点,总共产生了LN个采样点。然而,不同查询生成的采样点或不同特征图中相同查询生成的采样点不应具有相同的重要性。作者为第
个查询分配自适应和可学习的权重,权重方法如下:
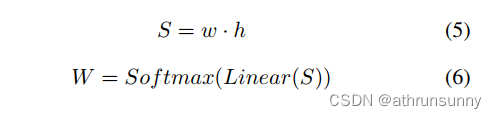
在这里,S表示每个查询对应的边界框面积,计算为其宽度和高度的乘积。形状为的
表示每个查询在特征图的L个级别上的权重。
3.4. Feature Mixer
采样的多尺度特征与内容向量之间的相互作用在目标检测中至关重要。受MLPmixer和AdaMixer的启发,作者引入了Feature Mixer,一个MLP模块,用于增强这种交互作用。按照MLPmixer的方法,作者使用内容查询来训练两个MLP网络,用于混合采样特征的最后两个维度。然后将结果转换成内容查询的形状,并将其添加到内容查询中,如图3所示。
在作者的设计中,作者在每个查询和采样特征之间建立了直接连接,确保每个采样特征与其相应的查询进行交互。这个过程消除了无效的bins,生成了最终的目标特征。为了保持轻量级设计,作者使用两个连续的1×1卷积和GELU激活函数进行交互。这些卷积的参数是从相应的内容向量生成的。
4. EXPERIMENTS
4.3. Main Result
最终的结果如表1所示。值得注意的是,FoLR在平均精度(AP)方面优于密集检测器,使用ResNet-50和ResNet-101Backbone分别获得42.6 AP(与40.3 AP相比)和43.5 AP(与42.0 AP相比)。
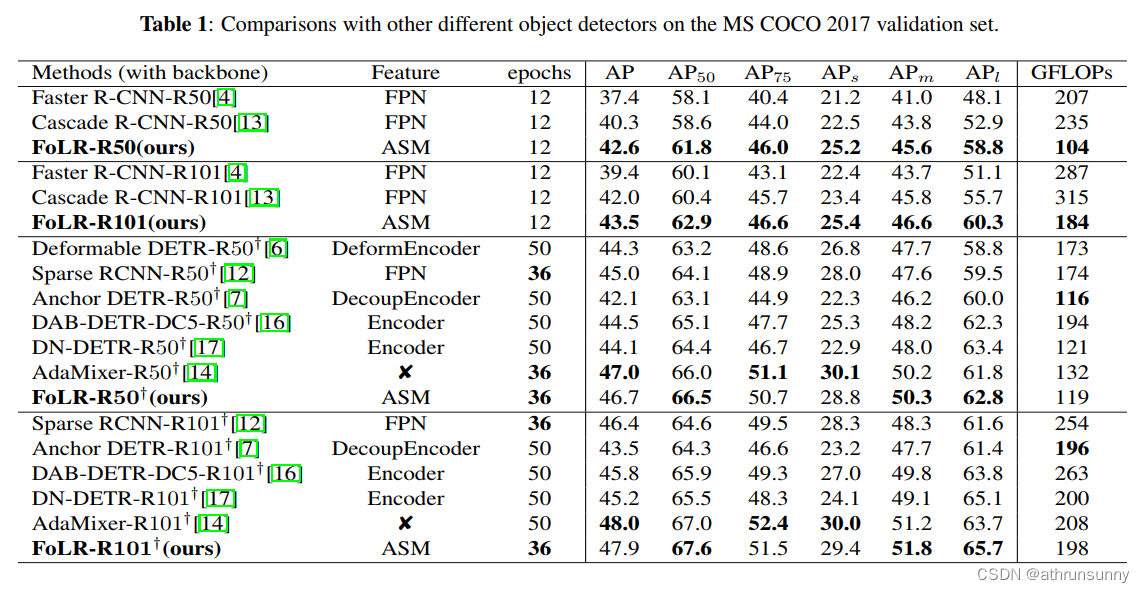
此外,FoLR在基于查询的检测器中获得了相对较高的分数,分别使用ResNet-50和ResNet-101Backbone达到46.7 AP和47.7 AP。此外,FoLR在其他指标(包括小目标准确性和计算成本)方面也表现出色。这些结果提供了有力的证据,表明FoLR在复杂性和性能之间有效地取得了平衡。
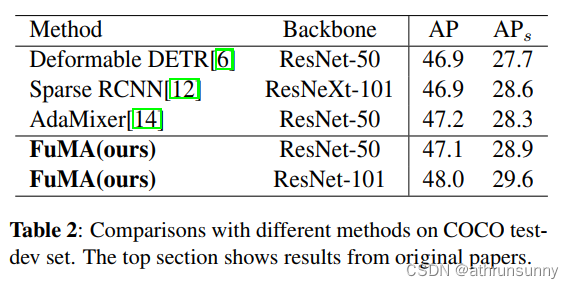
表2对比了FoLR和COCO 2017测试开发数据集上其他方法的结果。在使用ResNet-50和ResNet-101作为Backbone时,FoLR分别获得了47.2和48.1的AP分数。这些显著的结果进一步证明了FoLR的卓越性能也可以扩展和适应其他数据集。
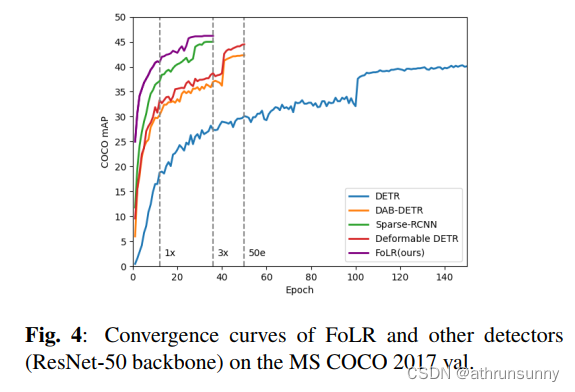
此外,如图4所示,作者通过与其他基于查询的检测器进行比较,全面分析了FoLR的收敛速度。结果清楚地表明,FoLR在训练的各个阶段都在收敛速度方面优于基于查询的检测器。具体而言,FoLR在使用更短的36个时期的training schedule时,实现了卓越的准确性,达到了46.7 AP(相对于可变形DETR的44.5 AP)。
4.4. Ablation Studies
在这里,作者还进行了消融实验,以评估FoLR中模块的有效性。由于计算约束,作者对这些实验使用了ResNet-50Backbone和1×training schedule。
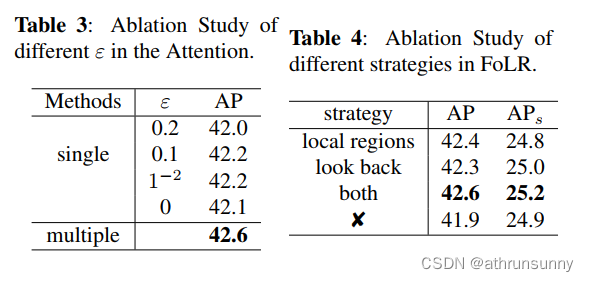
Design of Attention with Local Regions. 作者进行了额外的实验,验证了FoLR方法中注意力模块的有效性。不同的ε值表示对局部区域的关注程度不同。具体来说,当ε=0时,意味着不应用局部区域策略。同时,作者在不同阶段的解码器中分配了不同的ε值。作者观察到,在最后三个阶段,ε分别为0.01、0.1和0.2时,算法显示出0.5 AP的提高。结果如表3所示。
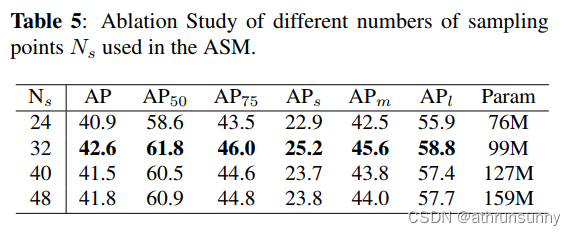
Design of Adaptive Sampling Method. 作者还比较了着重关注局部区域策略与不使用此策略的结果。表4中的结果表明,着重关注局部区域策略提高了0.7 AP的性能。同时,的选择影响了FoLR的收敛速度和所需的计算资源。为了在性能和计算负荷之间取得平衡,作者在[24, 48]范围内以8为步长进行了不同
值的实验。表5中的结果表明,
=32可以在性能和计算负载之间取得良好的平衡。
Look-Back Strategy Validation. 图4中的实验结果表明,使用回溯策略相对于没有回溯策略,准确性提高了0.4 AP。


















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











