






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自丨极市平台 作者丨小马
导读
本文作者提出了一种基于Transformer的目标检测器Anchor DETR,借鉴了CNN目标检测器中的Anchor Point机制,使得每个查询都基于特定的Anchor Point的,Anchor DETR获得比DETR更好的性能和更快的运行速度。
写在前面
在本文中,作者提出了一种基于Transformer的目标检测器。在以前基于Transformer的检测器中,目标的查询是一组可学习的embedding。然而,每个可学习的embedding都没有明确的意义 (因为是随机初始化的),所以也不能解释它最终将集中在哪里。此外,由于每个对象查询将不会关注特定的区域,所以训练时优化也是比较困难的 。
为了解决这些问题,作者借鉴了CNN目标检测器中的Anchor Point机制,使得每个查询都基于特定的Anchor Point的。因此,每个查询都可以集中在Anchor Point附近的目标上。此外,本文的查询设计可以在一个位置预测多个目标。为了降低attention的计算成本,作者设计了一种轻量级的attention变体。基于新的查询设计和attention变体,本文提出的Anchor DETR可以获得比DETR更好的性能和更快的运行速度。
1. 论文和代码地址

Anchor DETR: Query Design for Transformer-Based Detector
论文地址:https://arxiv.org/abs/2109.07107
代码地址(刚刚开源):
https://github.com/megvii-model/AnchorDETR
2. Motivation
目前DETR模型为目标检测任务提供了一个新的模型范式。它使用一组可学习到的目标查询来推理目标和全局图像上下文之间的关系,以输出最终的预测集。然而,学习到的目标查询的可解释性较差。它没有显式的意义,每个查询也没有显式对应的某个检测位置、或者检测目标。
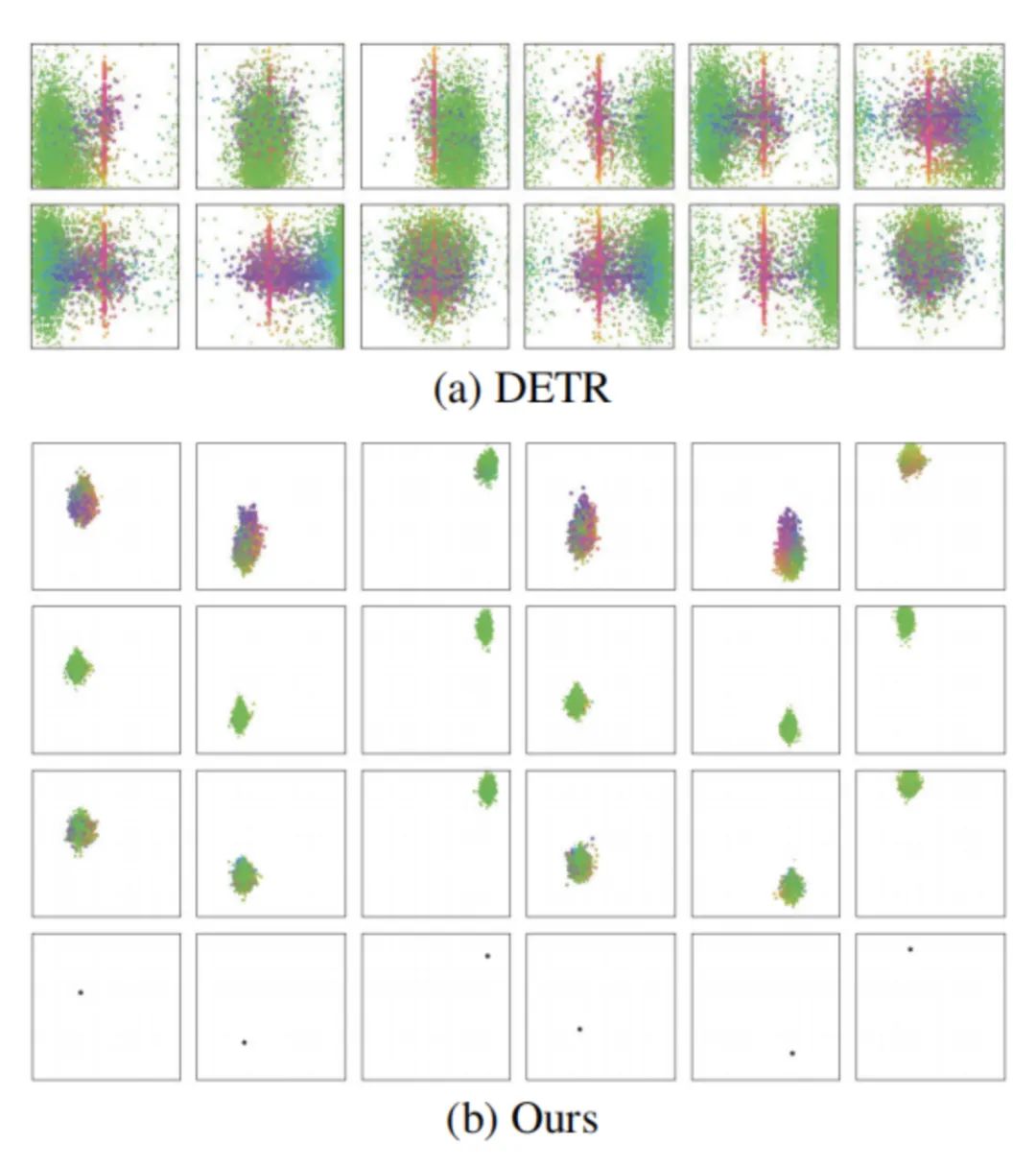
如上图(a)所示,DETR中每个目标查询的预测与不同的区域相关,并且每个查询将负责一个非常大的区域。这种位置上的不明确性,也使得DETR很难优化。
回顾基于CNN的检测器,anchor与位置高度相关,包含可解释的意义。受此启发,作者提出了一种基于锚点(anchor points)的查询设计 ,即将anchor points编码为目标查询 。查询是锚点坐标的编码,因此每个目标查询都具有显式的物理意义。
但是,这个解决方案还有一个限制:多个目标可能出现在一个位置 。在这种情况下,只有这个位置的一个查询不能预测多个目标,因此来自其他位置的查询必须协同预测这些目标。它将导致每个目标查询负责一个更大的区域。因此,作者通过向每个锚点添加多个模式(multiple patterns,即一个锚点可以检测多个目标)来改进目标查询设计,以便每个锚点都可以预测多个目标。如上图(b)所示,每个查询的三种模式的所有预测都分布在相应的锚点周围。因此,本文提出的目标查询具备更好的可解释性 。由于查询具有特定的模式,并且不需要预测远离相应位置的目标,因此更容易进行优化 。
除了查询设计之外,作者还设计了一个attention变体——行列解耦注意(Row-Column Decouple Attention,RCDA) 。它将二维key特征解耦为一维行特征和一维列特征,然后依次进行行注意和列注意。RCDA可以降低计算成本,同时实现与DETR中的标准注意力相似甚至更好的性能。
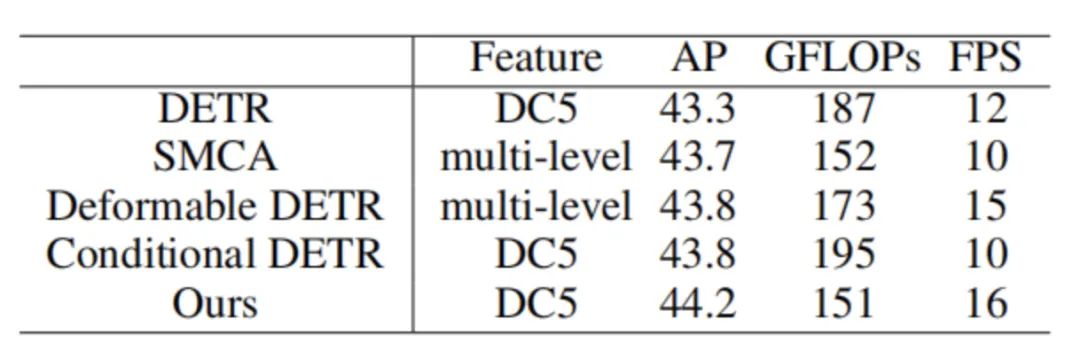
如上表所示,基于锚点查询和RCDA注意力的Anchor DETR在使用相同的特征时,可以获得更好的性能和更快的检测速度。此外,相比于原始的DETR模型,本文的训练epoch数只需要原来的十分之一。
3. 方法
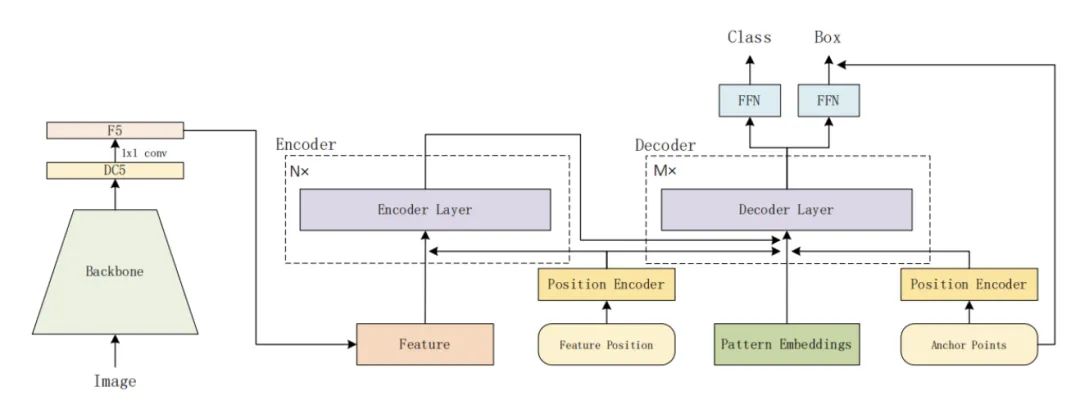
本文提出的检测器模型结构如上图所示。
3.1. Anchor Points
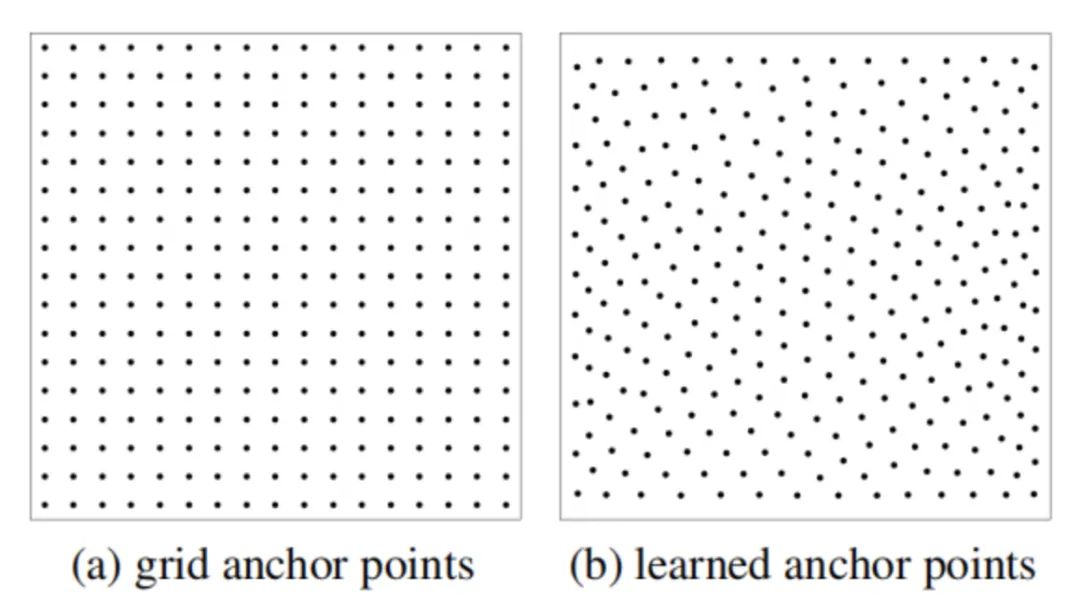
在基于CNN的检测器中,锚点是特征图的位置。但在基于Transformer的检测器中,锚点可以是可学习的点、统一的网格点或其他手工设置的点。在本文中,作者采用了两种类型的锚点。一个是网格锚点 ,另一个是可学习的锚点 。如下图(a)所示,网格锚点固定为图像中的均匀网格点。可学习的锚点以0到1的均匀分布随机初始化,并作为学习参数进行更新,如下图(b)所示。
3.2. Attention Formulation
DETR中的attention可以表示如下:
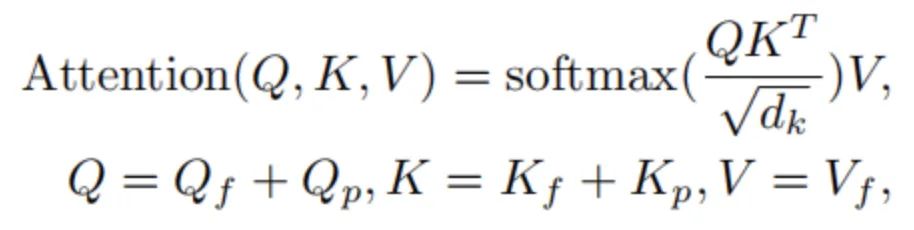
下标f表示特征,下标p表示位置embedding。
DETR中有两种attention:Self-Attention和Cross-Attention。
在Self-Attention中,、与相同,与相同。是上一个解码器的输出,为第一个解码器的初始化查询向量。对于查询位置embedding ,它在DETR中使用了一组可学习的向量:

在Cross-Attention中,是由前面的自注意的输出生成的,而和是编码器的输出特征。是的位置embedding,它由sine-cosine position函数生成:
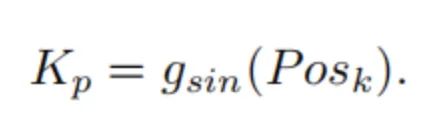
3.3. Anchor Points to Object Query
解码器中的为目标查询向量,它们负责区分不同的目标。但是上面式子中的目标查询可解释性比较差,因为每个查询对应的目标都没有显式的约束。
在本文中,作者提出基于锚点的查询。代表其,位置的个点。然后,基于锚点的目标查询可以表示为:
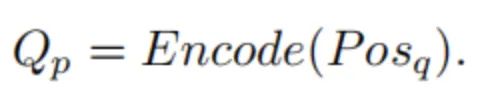
也就是说,这里的目标查询是根据锚点的位置编码的。
对于上述式子中的编码函数,计算如下:

位置编码函数可以是或其他位置编码函数。在实验中,作者就是采用了。
3.4. Multiple Predictions for Each Anchor Point
对于初始的查询向量,每个查询都有一个模式(pattern) 。为了预测每个锚点的多个目标,可以合并一个锚点中的多个模式。因此,一个具有个模式的集合 可以表示为:

在实验中,通常不会太大,因为同一个锚点位置通常不会有非常多的目标。
最终只需要将query和位置编码相加,就得到最终的查询向量, Pattern Position query可以表示为:
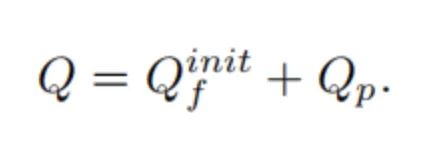
由于这种查询设计,Anchor DETR检测器具有可解释的查询,在训练epoch数少10倍的情况下,依旧比原始DETR获得更好的性能。
3.5. Row-Column Decoupled Attention
在本文中,作者还提出了行列解耦注意(Row-Column Decoupled Attention,RCDA),它不仅可以降低计算负担,而且还可以获得比DETR中的标准注意力相似或更好的性能。RCDA的主要思想是将key特征解耦为横向特征和纵向特征(即用一维的gobal pooling消除纵向或者横向的维度)。RCDA可以表述为:
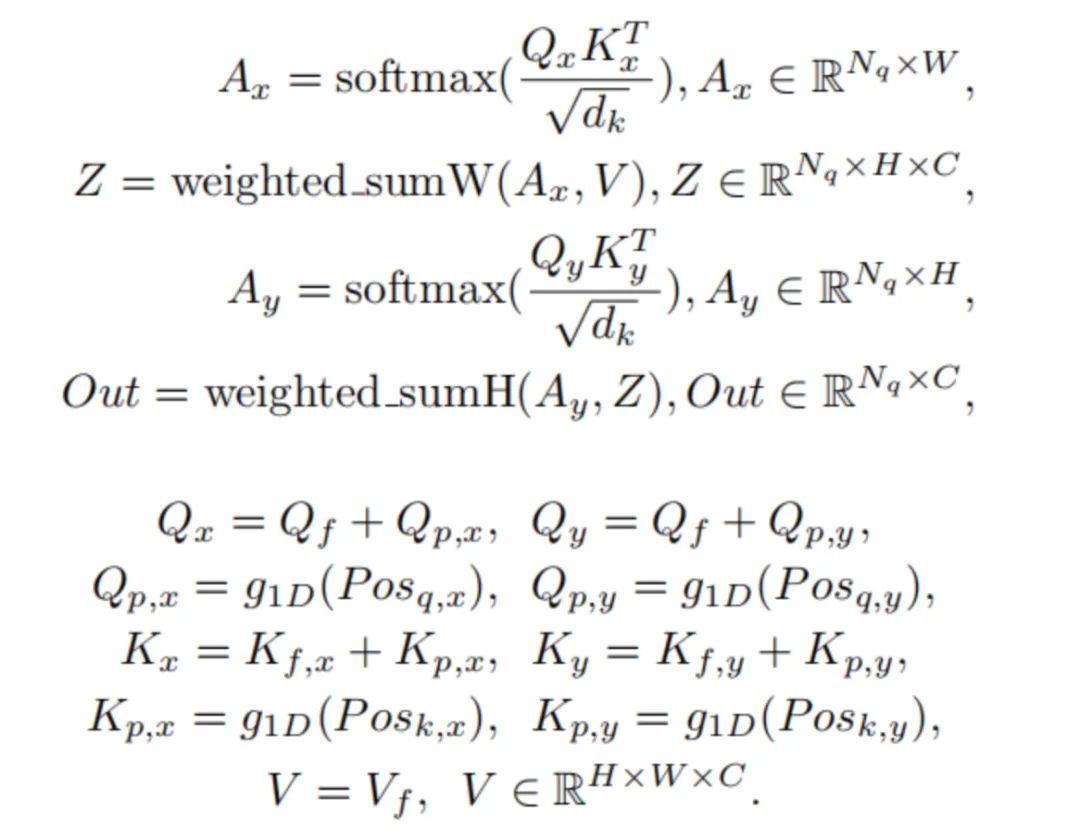
和运算分别沿着宽度维度和高度维度进行加权和。代表一维的位置编码。
4.实验
4.1. Main Results
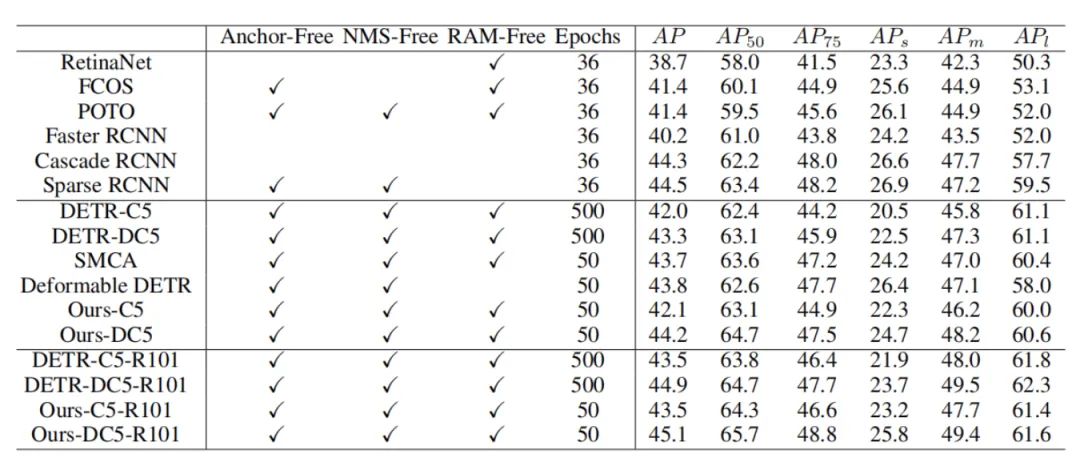
上表显示了本文方法和一些目标检测方法的性能和训练epoch数的对比。可以看出,本文的方法在性能上相比于其他方法还是具有一定的优势,并且训练的epoch数比DETR小的多。
4.2. Ablation Study
4.2.1. Effectiveness of each component
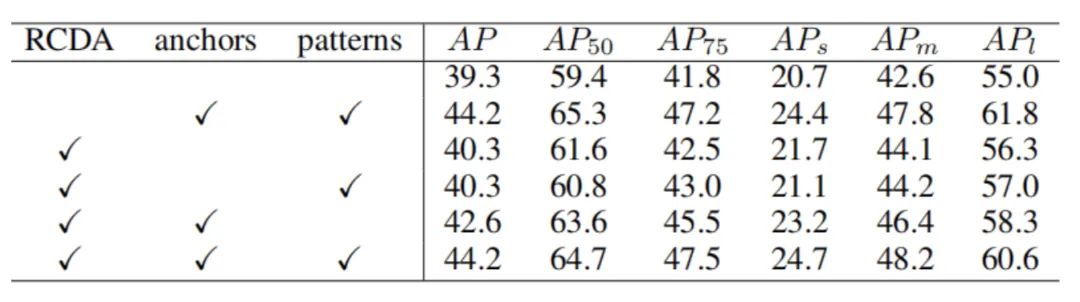
上表显示了本文的不同模块RCDA、Anchor、patterns的消融实验结果,可以看出,Anchor、patterns对实验性能的提升有效果。RCDA在减少计算量的同时没有明显影响性能。
4.2.2. Multiple Predictions for Each Anchor Point
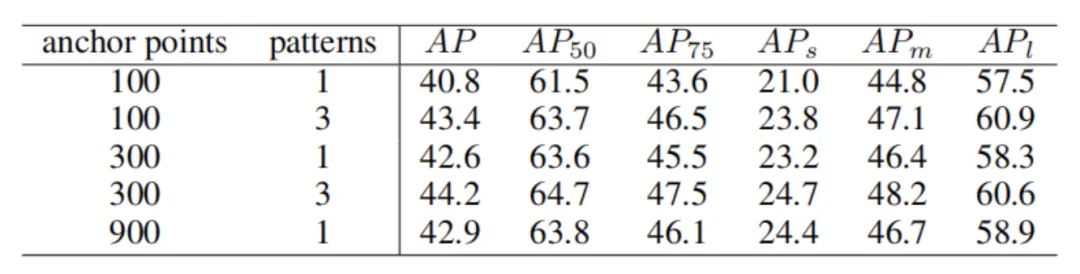
上表显示了不同anchor point和pattern的实验结果。可以看出基于锚点的多重预测对于提升模型性能是非常有效的。
4.2.3. Anchor Points Types

可以看出,可学习的锚点和均匀分布的锚点对于最终实验性能的影响是不大的。
4.2.4. Prediction Slots of Object Query
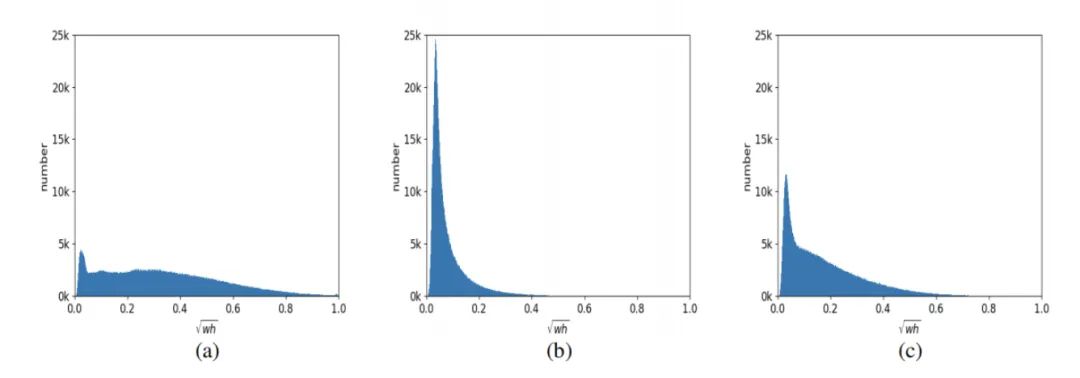
上表显示了每个pattern的直方图,可以看出不同的pattern会倾向于预测不同尺寸的目标框。
4.2.5. Row-Column Decoupled Attention
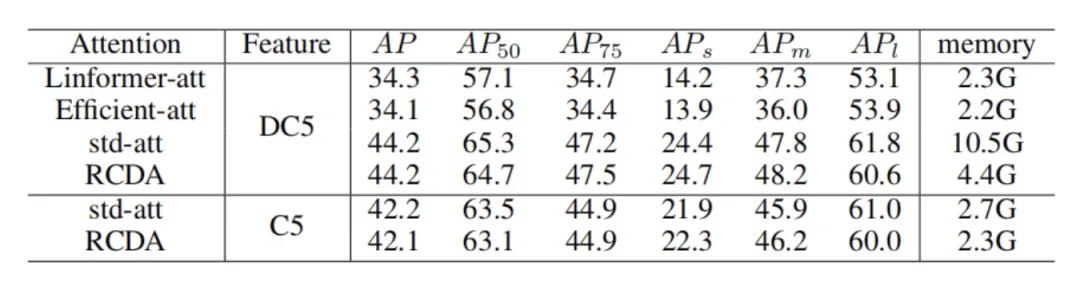
上表显示了不同注意力机制下的memory和performance,可以看出RCDA在没有显著影响performance的情况下,降低了计算的开销。
5. 总结
在本文中,作者提出了一种基于Transformer的检测器——Anchor DETR。Anchor DETR中有基于anchor point(锚点)的查询设计,因此每个查询只预测锚点附近的目标,因此更容易优化。此外,作者在每个锚点上加入了多个模式来解决一个区域中可能多个目标的问题。为了降低计算的复杂度,作者还提出了一种注意变体,称为行列解耦注意(Row-Column Decoupled Attention)。行列解耦注意可以降低计算成本,同时实现与DETR中的标准注意力相似甚至更好的性能。与DETR相比,Anchor DETR可以在减少10倍训练epoch数的情况下,获得更好的性能。
本文的最大亮点是提出了一个基于Anchor Point的DETR ,能够为每个查询赋予显式的物理意义,因此相比于DETR更容易优化。个人觉得很有意思的一点是:基于CNN的目标检测器“无Anchor→有Anchor→Anchor Free ”的过程。基于Transformer的目标检测器(比如:DETR)最开始也是没有Anchor的,这篇文章开始引入了Anchor Point机制(即Anchor-Free)来优化DETR,直接跳过了有Anchor(这里的Anchor指Anchor Box)阶段,之后会不会又有文章继续提出基于Anchor Box的Transformer目标检测器,重走一遍CNN目标检测器走过的道路呢?
Anchor DETR论文和代码下载
后台回复:Anchor,即可下载上述论文和代码ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()

















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









