






2024年视觉与学习青年学者研讨会(VALSE 2024)于5月5日到7日在重庆悦来国际会议中心举行。本公众号将全方位地对会议的热点进行报道,方便广大读者跟踪和了解人工智能的前沿理论和技术。欢迎广大读者对文章进行关注、阅读和转发。文章是对报告人演讲内容的理解或转述,可能与报告人的原意有所不同,敬请读者理解;如报告人认为文章与自己报告的内容差别较大,可以联系公众号删除。
本文主要介绍VALSE 2024年度进展评述中由上海交通大学严骏驰教授讲述的“世界模型增强下的自动驾驶”专题。严老师为上海交通大学计算机系教授,研究领域主要集中在计算机视觉、机器学习及人工智能与其它学科的交叉领域。“世界模型增强下的自动驾驶”专题所涉及的专业知识非常广泛且深入,结合了人工智能等一系列最新最先进的技术,是当今学术界和工业界最前沿和热门的研究领域之一。该专题内容的大纲如图1所示。首先,严老师从宏观角度为大家介绍了世界模型的基本概念,并探讨了自动驾驶待解决的问题以及世界模型对于解决这些问题的优势。然后,逐步深入到世界模型增强下的自动驾驶的前沿进展,并深入刨析了相关方法和模型架构。最后,严老师对本次所讲述的专题内容进行了总结和展望,强调了扩展计算资源对于解决自动驾驶策略学习中长尾问题的重要性以及基于强化学习探索端到端的自动驾驶框架的应用等。
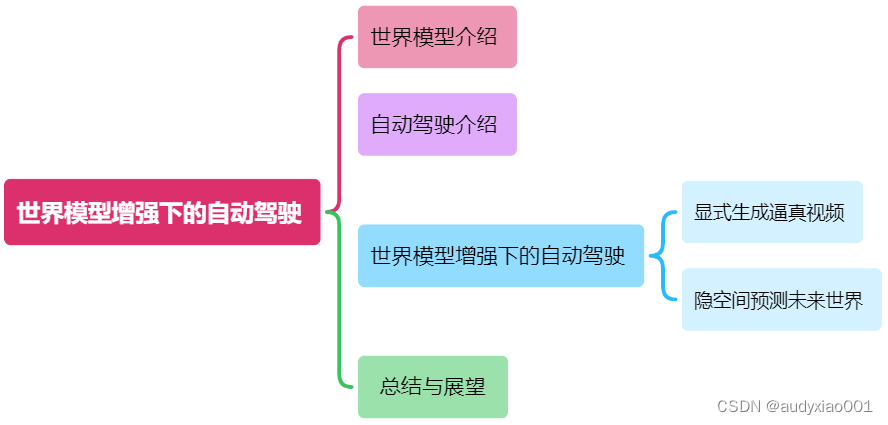
图1 世界模型增强下的自动驾驶专题报告大纲
1.世界模型介绍
图灵奖得主Yann Lecun在2022年“A Path towards autonomous machine intelligence”文章中构想的人脑模块由总控、感知、评价、短期记忆、行动、世界模型这六部分共同组成,如图2所示。其中世界模型的作用在于给定当前状态,基于预期的动作,预测未来可能的状态。例如,在自动驾驶系统中,这样的世界模型能够帮助实时分析道路情况,评估其他交通参与者的潜在意图,并预测可能的风险,从而做出适时的驾驶决策。通过模拟人类的认知框架,世界模型提供了一个全面且预测性的环境理解,极大地增强了机器系统的自主性和适应性。

图2 世界模型的定义
2.自动驾驶待解决的问题
问题一:子任务复杂繁琐和高昂的标注成本
自动驾驶系统包括多个层面的任务,如感知环境、预测潜在变化和决策制定,如图2所示。每个层面都需要大量精确标注的数据来训练和优化算法,使车辆能够准确解释周围的环境并做出安全的行驶决策。标注这些数据通常涉及复杂的技术过程,包括从实际驾驶场景中提取信息,并准确标识各种交通参与者和环境因素的位置、动作和意图,这使得标注过程成本高昂。
问题二:数据成长尾分布和高昂的采集成本
为了确保自动驾驶系统能在多样的环境中可靠运行,需要采集涵盖广泛时间、地点和行为的数据集,如图3所示。这类数据显示出成长尾分布特征,即一些罕见但关键的情况在整体数据集中占比较小,但对于训练准确鲁棒的自动驾驶模型却是不可或缺的。收集这些多样化的数据需要在不同的时间段、多变的天气条件和各种地理位置进行大规模的数据采集,从而带来高额的成本和资源投入。
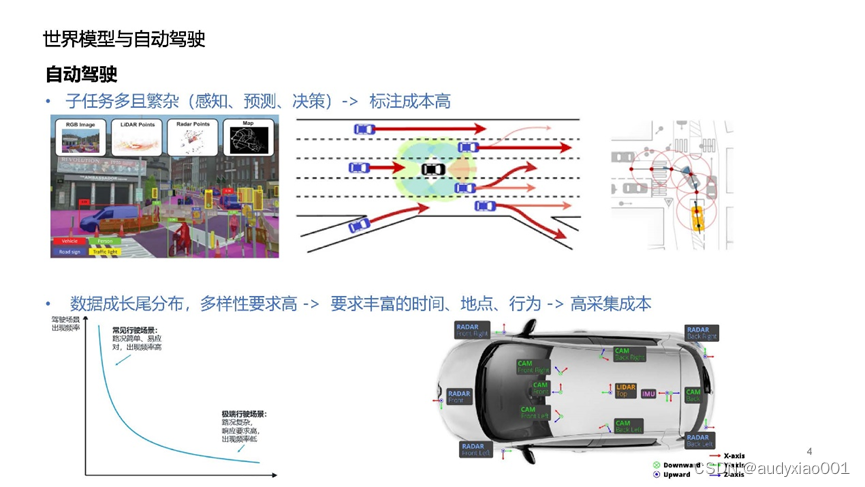
图3 自动驾驶待解决的问题示意图
3.世界模型增强下的自动驾驶
为解决上述问题,世界模型提供了一个创新的解决框架。如图4所示,第一类思路是:世界模型通过扩散模型生成逼真的视频数据,有效地扩展训练数据集,从而辅助自动驾驶系统的感知训练。这种方法能够显著增强系统对现实世界复杂情况的处理能力,同时降低对实际道路测试的依赖。另一种策略是利用隐空间技术来预测和模拟未来可能的世界状态。通过这种方式,自动驾驶系统可以在虚拟环境中“体验”未来的驾驶情况,从而优化其决策过程。这种预测不仅基于现有数据,还包括可能发生的罕见或极端情况,有效解决了自动驾驶中的长尾分布问题。

图4 世界模型增强下的自动驾驶
(1)显式生成逼真视频
严老师详细介绍了最新的5种用于自动驾驶领域视频生成的世界模型。由于篇幅有限,本文以CVPR 2024 “Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving”中提出的Drive-WM为例进行介绍,如图5所示。Drive-WM是首个与现有端到端规划模型兼容的驾驶世界模型。通过空间-时间建模和视角分解,模型能生成高保真度的多视角驾驶场景视频,为自动驾驶安全规划提供支持。通过对相机联合概率分布进行分解,预测基于相邻视图的中间视图,极大提高了视图之间的一致性。此外,其引入了简单而有效的统一条件模块,可以灵活使用多种异质条件(如图像、文本、3D框),大大简化了条件生成过程。此外,如图5所示,与其它自动驾驶世界模型相比,Drive-WM所需的数据规模更少,性能更强。
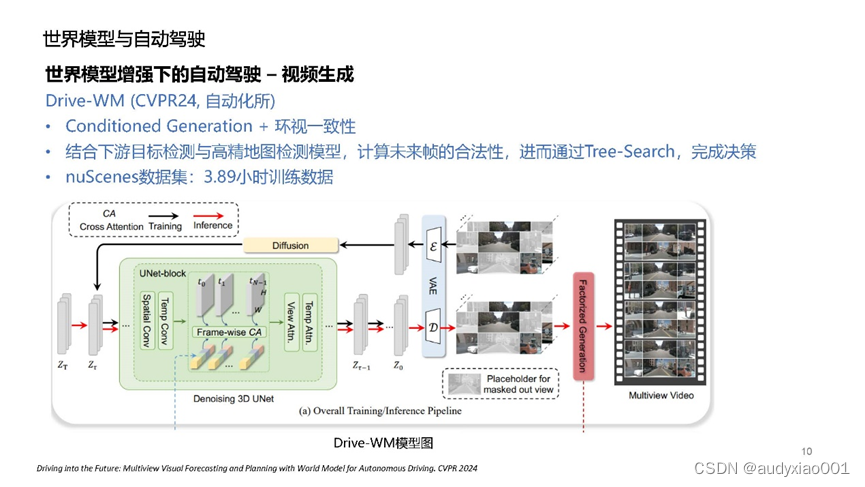
图5 Drive-WM自动驾驶世界模型介绍
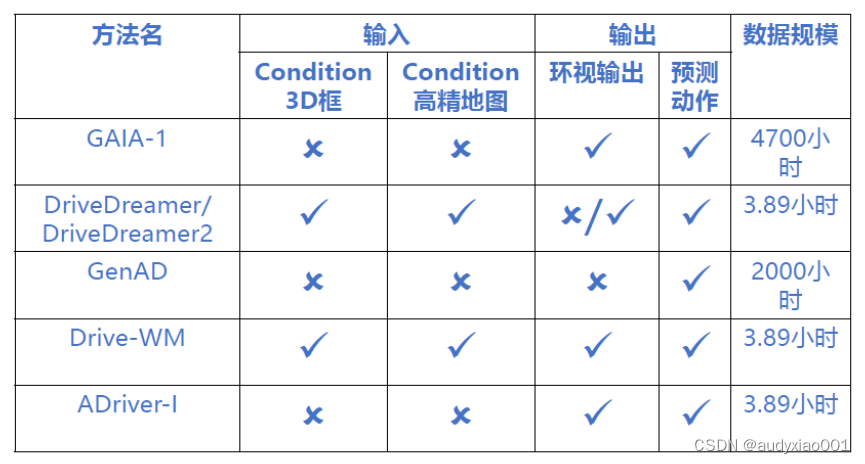
图6 五种自动驾驶世界模型对比
最后,严老师分析对比了5种方法的异同,并总结了基于视频生成的世界模型有望为长尾问题的解决提供巨大帮助,如图6所示。读者如需要详细了解严老师团队在自动驾驶方面的工作,可以下载其团队最新的综述文章“LLM4Drive: A Survey of Large Language Models for Autonomous Driving”进行阅读,网址为https://arxiv.org/abs/2311.01043v3。如需了解更多LLM和自动驾驶相结合方面的工作,可以查看网站https://github.com/Thinklab-SJTU/Awesome-LLM4AD。更多关于严老师团队研究工作的介绍,请读者查阅其实验室网站SJTU-ReThinkLab 上海交通大学交想实验室。
(2)隐空间预测未来世界
论文“Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2)”中提出的Think2Drive世界模型是严老师和他的团队最新的研究成果。Think2Drive是首个应用于自动驾驶的基于模型的强化学习方法。通过使用世界模型来学习环境的转换动态,它能在学习到的潜在空间中进行“思考式驾驶”,从而提高数据效率和应对复杂场景的灵活性。Think2Drive在CARLA v2中处理39种高度真实的驾驶场景,显示出优异的性能。这些场景包括紧急车辆让行、复杂交叉口处理等,都是自动驾驶中的高难度挑战。该模型在单个A6000 GPU上仅需三天训练时间即可达到专家级别的驾驶水平,显著优于传统的深度学习模型需要的时间。
4.总结与展望
在专题报告的最后阶段,严老师对“世界模型增强下的自动驾驶”进行了深入的总结与前瞻性展望,如图7所示。他强调,为了充分挖掘自动驾驶世界模型的潜力,需要大幅增加计算资源投入,并利用更大规模的数据集。这样做能有效促进自动驾驶策略的学习过程,尤其是解决长尾问题,从而极大提高驾驶系统的适应性和安全性。严老师还指出,未来自动驾驶的发展将更多依赖于无监督学习和强化学习技术,这些技术在端到端自动驾驶系统中展现出巨大的应用潜力。他认为,通过这些先进的学习方法,自动驾驶技术能够更好地理解和适应复杂的交通环境,从而提升整体的驾驶效率和安全标准。

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









