







 本文介绍使用TensorFlow构建卷积神经网络(CNN)对CIFAR-10数据集进行分类的过程。主要内容包括数据加载、模型训练与评估等关键步骤。
本文介绍使用TensorFlow构建卷积神经网络(CNN)对CIFAR-10数据集进行分类的过程。主要内容包括数据加载、模型训练与评估等关键步骤。
cifar10是nclass = 10的分类问题,共采用两层卷积层(conv),两层maxpool层,3层全连接层,最后一层为softmax层。数据类型为二进制文件:CIFAR-10 binary version (suitable for C programs)。
可从cifar数据官网下载:https://www.cs.toronto.edu/~kriz/cifar.html,
代码一共分为三部分:读取数据,训练模型,测试模型。开发环境采用sublime上的搭建的python环境。
1.读取数据
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import numpy as np
def input_cifar10(file_dir,is_train,batch_size,shuffle):
'''
Args:
file_dir: file path
batch_size: Number of images per batch
shuffle : boolean indicating whether to use a shuffling queue
Outputs:
image tensor: image. 4D tensor of [batch_size, height, width, depth] size.
label tensor: labels. 1D tensor of [batch_size] size.
'''
image_height = 32
image_width = 32
image_depth = 3
label_bytes = 1
image_bytes = image_width*image_height*image_depth
record_bytes = image_bytes+label_bytes
# input queue
file_list = os.listdir(file_dir)
if is_train:
filenames = [os.path.join(file_dir,'data_batch_%d.bin' % ii) for ii in range(1,6)]
else:
filenames = [os.path.join(file_dir,'test_batch.bin')]
filename_queue = tf.train.string_input_producer(filenames)
#reader
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
key, value = reader.read(filename_queue)
record_bytes = tf.decode_raw(value, tf.uint8)
#generate label and float_image
label = tf.cast(tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
image = tf.reshape(tf.strided_slice(record_bytes,[label_bytes],
[label_bytes + image_bytes]),
[image_depth, image_height, image_width])
image = tf.transpose(image, [1, 2, 0])
reshape_image = tf.cast(image, tf.float32)
resized_image = tf.image.resize_image_with_crop_or_pad(reshape_image,
image_height, image_width)
float_image = tf.image.per_image_standardization(resized_image)
float_image = tf.reshape(float_image,[image_height, image_width, 3])
label = tf.reshape(label,[1])
if shuffle:
images, label_batch = tf.train.shuffle_batch([float_image, label],
batch_size=batch_size,
num_threads=16,
capacity= 500,
min_after_dequeue = 300)
else:
images, label_batch = tf.train.batch([float_image, label],
batch_size=batch_size,
num_threads=16,
capacity=500)
label_batch = tf.reshape(label_batch, [batch_size])
print(images)
return images, label_batch
2.训练模型
import os
import tensorflow as tf
import numpy as np
import input_cifar10
n_class = 10
image_H = 32
image_W = 32
CAPACITY = 2000
BATCH_SIZE = 128
MAX_STEP = 9999
learning_rate = 0.05
def inference(images,batch_size,n_classes):
'''
Args:
images: images
labels:label_batch
Returns:
logits.
'''
#conv1
with tf.variable_scope('conv1') as scope:
weights = tf.get_variable('weights',
shape = [5,5,3,64],
dtype = tf.float32,
initializer = tf.truncated_normal_initializer(stddev = 0.005,dtype = tf.float32))
conv = tf.nn.conv2d(images,weights,[1,1,1,1],padding = 'SAME')
biases = tf.get_variable('biases',
shape = [64],
dtype = tf.float32,
initializer = tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv,biases)
conv1 = tf.nn.relu(pre_activation,name = scope.name)
# pooling 1 and norm 1
pool1 = tf.nn.max_pool(conv1,ksize = [1,3,3,1],strides = [1,2,2,1],
padding = 'SAME',name = 'pool1')
norm1 = tf.nn.lrn(pool1,4,bias = 1.0,alpha=0.001/9.0,beta=0.75,
name = 'norm1')
print(conv1,pool1,norm1)
#conv2
with tf.variable_scope('conv2') as scope:
weights = tf.get_variable('weights',
shape = [5,5,64,64],
dtype = tf.float32,
initializer = tf.truncated_normal_initializer(stddev = 0.005,dtype = tf.float32))
conv = tf.nn.conv2d(norm1,weights,[1,1,1,1],padding = 'SAME')
biases = tf.get_variable('biases',
shape = [64],
dtype = tf.float32,
initializer = tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv,biases)
conv2 = tf.nn.relu(pre_activation,name = scope.name)
# pooling 2 and norm 2
norm2 = tf.nn.lrn(conv2,4,bias = 1.0,alpha=0.001/9.0,beta=0.75,
name = 'norm2')
pool2 = tf.nn.max_pool(norm2,ksize = [1,3,3,1],strides = [1,2,2,1],
padding = 'SAME',name = 'pool2')
print([conv2,norm2,pool2])
#local3--fc
with tf.variable_scope('local3') as scope:
reshape = tf.reshape (pool2,shape = [batch_size, -1])
dim = reshape.get_shape()[1].value
weights = tf.get_variable('weights', shape=[dim, 384],
dtype = tf.float32,
initializer = tf.truncated_normal_initializer(stddev=0.04,dtype=tf.float32))
biases = tf.get_variable('biases', [384],
dtype = tf.float32,
initializer = tf.constant_initializer(0.1))
local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
#local4
with tf.variable_scope('local4') as scope:
weights = tf.get_variable('weights', shape=[384, 192],
dtype = tf.float32,
initializer = tf.truncated_normal_initializer(stddev=0.04,dtype=tf.float32))
biases = tf.get_variable('biases', [192],
dtype = tf.float32,
initializer = tf.constant_initializer(0.1))
local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name=scope.name)
#local5
with tf.variable_scope('softmax_linear') as scope:
weights = tf.get_variable('weights', shape=[192, n_classes],
dtype = tf.float32,
initializer = tf.truncated_normal_initializer(stddev=1/192.0,dtype=tf.float32))
biases = tf.get_variable('biases', [n_classes],
dtype = tf.float32,
initializer = tf.constant_initializer(0.0))
softmax_linear = tf.add(tf.matmul(local4, weights) ,biases, name='softmax_linear')
return softmax_linear
# losses
def losses(logits, labels):
'''
args:
logits: logits tensor, float, [batch_size, n_classes]
labels: labels tensor,tf.int32,[batch_size]
returns:
loss tensor of float type
'''
with tf.variable_scope('loss') as scope:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels= labels,
name='cross_entropy_per_example')
loss = tf.reduce_mean(cross_entropy, name='loss')
tf.summary.scalar(scope.name+'/loss',loss)
return loss
#training
def train(loss,learning_rate):
'''
args:
loss:loss tensor
returns:
train_op: the op for training
'''
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate)
global_step = tf.Variable(0,name='global_step', trainable=False)
train_op = optimizer.minimize(loss,global_step = global_step)
return train_op
#evaluation
def evalution(logits, labels):
with tf.variable_scope('accuracy') as scope:
correct = tf.nn.in_top_k(logits, labels,1)
correct = tf.cast(correct,tf.float16)
accuracy = tf.reduce_mean(correct)
tf.summary.scalar(scope.name+'/accuracy',accuracy)
return accuracy
#run training
train_dir = 'D:/tensorflow/cifar10/cifar-10-batches-bin/'
logits_train_dir = 'D:/tensorflow/cifar10/logits/'
if not os.path.exists(logits_train_dir):
os.makedirs(logits_train_dir)
train_batch,train_label_batch = input_cifar10.input_cifar10(train_dir,
is_train =True,
batch_size = BATCH_SIZE,
shuffle= False)
logits_train = model_cifar.inference(train_batch,BATCH_SIZE,n_class)
loss = model_cifar.losses(logits_train,train_label_batch)
train_op = model_cifar.train(loss,learning_rate)
accuracy = model_cifar.evalution(logits_train,train_label_batch)
summary_op = tf.summary.merge_all()
sess = tf.Session()
train_writer = tf.summary.FileWriter(logits_train_dir,sess.graph)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess = sess, coord = coord)
try:
for step in np.arange(MAX_STEP):
if coord.should_stop():
break
_,train_loss,train_accuracy = sess.run([train_op,loss,accuracy])
if step % 100 == 0:
print('Step %d, train loss = %.2f, train_accuracy = %.2f' %(step,train_loss,train_accuracy))
summary_str = sess.run(summary_op)
train_writer.add_summary(summary_str, step)
if step % 200 == 0:
checkpoint_path = os.path.join(logits_train_dir, 'model.ckpt')
saver.save(sess,checkpoint_path,global_step = step)
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()
coord.join(threads)
3.评估模型
import os
import tensorflow as tf
import numpy as np
import input_cifar10
import model_cifar
import math
import datetime
# constant
BATCH_SIZE = 128
test_dir = 'D:/tensorflow/cifar10/cifar-10-batches-bin/'
checkpoint_dir = 'D:/tensorflow/cifar10/logits/'
n_tests = 10000
#test_dir_logits2 = 'D:/tensorflow/cifar10/logits2/'
with tf.Graph().as_default() as g:
images,labels = input_cifar10.input_cifar10(test_dir,
is_train =False,
batch_size = BATCH_SIZE,
shuffle= False)
#inferenece model
logits = model_cifar.inference(images,batch_size = BATCH_SIZE,n_classes = 10)
#calculate predictions
top_k_op = tf.nn.in_top_k(logits,labels,1)
saver = tf.train.Saver(tf.global_variables())
#summary_op = tf.summary.merge_all()
#summary_writer = tf.summary.FileWriter(test_dir_logits2, g)
with tf.Session() as sess:
print('Reading checkpoints...')
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
print('loading success,global_step is %s' % global_step)
else:
print('No checkpoint file found')
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess = sess, coord = coord)
try:
num_iter = int(math.ceil(n_tests/ BATCH_SIZE))
true_count = 0 # Counts the number of correct predictions.
total_sample_count = num_iter * BATCH_SIZE
step = 0
while step < num_iter and not coord.should_stop():
predictions = sess.run([top_k_op])
true_count += np.sum(predictions)
step += 1
# Compute precision @ 1.
precision = true_count / total_sample_count
print('precision = %.3f' % precision)
except Exception as e: # pylint: disable=broad-except
coord.request_stop(e)
finally:
coord.request_stop()
coord.join(threads)代码解析
1.cnn神经网络读取固定长度二进制文件的基本流程
(1).read data(FixedLengthRecordReader,decode_raw)
(2).generate batch
(3).feed in tensorflow graph
(4)train
(5)validation
2.网络
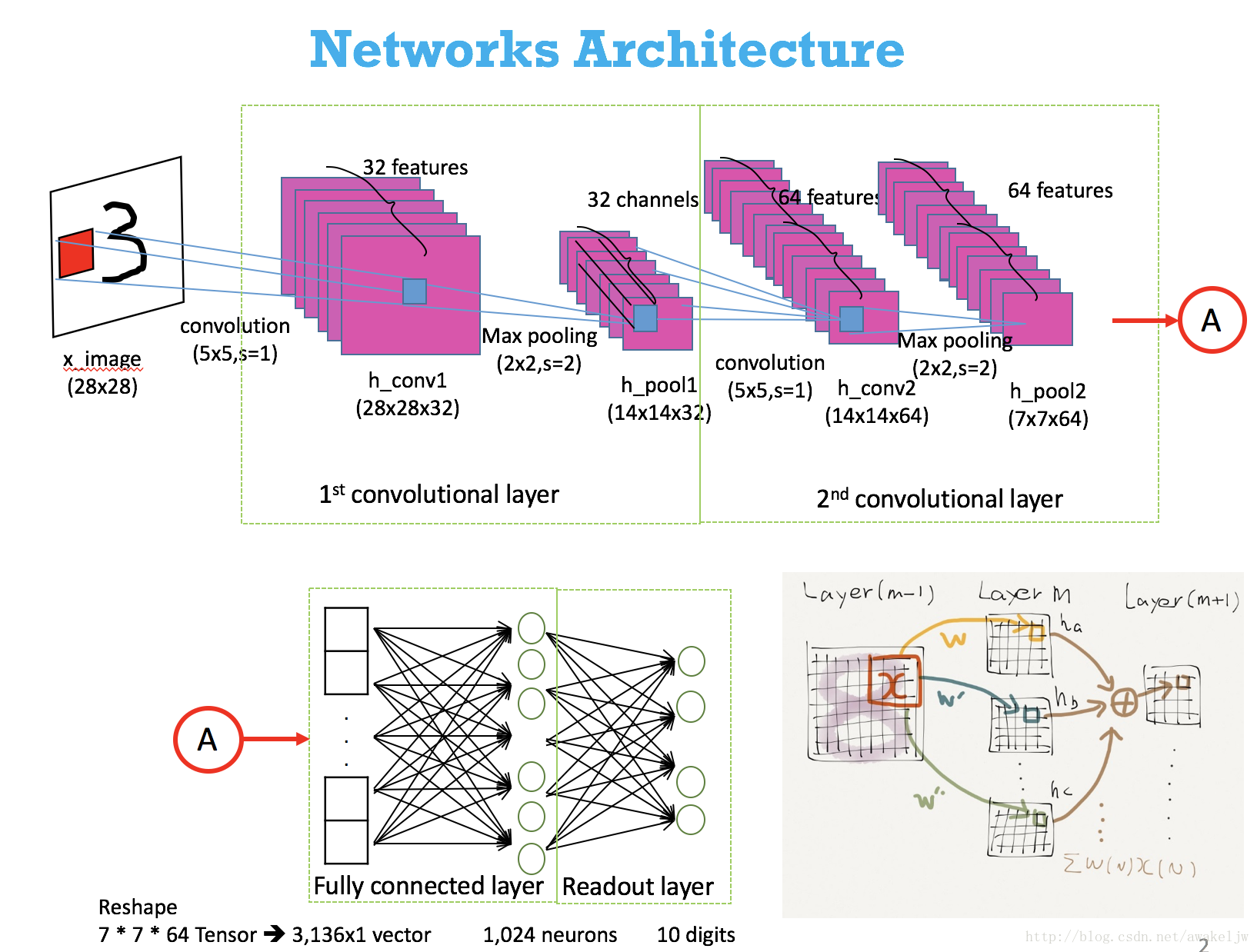
input = [batch, in_channels, in_height, in_width]
输出神经网络的卷积层及池化层,可以发现卷积层与原始图像的尺寸一致,这是因为代码中采用zero-padding的填补方式,保证图像的大小不至于因为卷积而缩小。
input = [BATCH_SIZE = 128,32,32,3]
CONV1 = [128,32,32,64]
POOL1 = [128,16,16,64]
CONV2 = [128,16,16,64]
POOL2 = [128,8,8,64]
LOCAL3 = [128,384]
……
3.strides and ksize
ksize表示卷积核的大小[height,width,in_channels, out_channels]
stides表示卷积核的滑移距离,strides = [batch , in_height , in_width, in_channels]
4.padding:表示填充方式:“SAME”表示采用填充的方式,简单地理解为以0填充边缘,但还有一个要求,左边(上边)补0的个数和右边(下边)补0的个数一样或少一个,“VALID”表示采用不填充的方式,多余地进行丢弃。具体公式:
“SAME”: output_spatial_shape[i]=(input_spatial_shape[i] / strides[i])
“VALID”: output_spatial_shape[i]=((input_spatial_shape[i]-(spatial_filter_shape[i]-1)/strides[i])
参考文献
1.https://www.leiphone.com/news/201705/HH3BbIfCqAtOAMbu.html
2.http://m.blog.csdn.net/v_JULY_v/article/details/51812459
3.https://www.zhihu.com/question/52668301
4.http://m.blog.csdn.net/u011974639/article/details/75363565

















 2890
2890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









