






DDR3自学笔记

人在江湖身不由己
关注他
LogicJitterGibbs 等 242 人赞同了该文章
前言
在现在的嵌入式系统中DDR存储器是不可或缺的一部分,其中使用了大量新技术,并且由于其高速特性也对硬件设计造成挑战。我以前的设计都是以MCU和低端的FPGA为主,都是内嵌RAM。最近刚刚接触DDR技术,把自己所看的多篇文章,整理成一篇学习笔记,以便以后深入扩展。
一、DDR3技术简介
1.1名词解释
第三代双倍数据率同步动态随机存取存储器(Double-Data-Rate Three Synchronous Dynamic Random Access Memory,一般称为DDR3 SDRAM)
1.2技术图谱
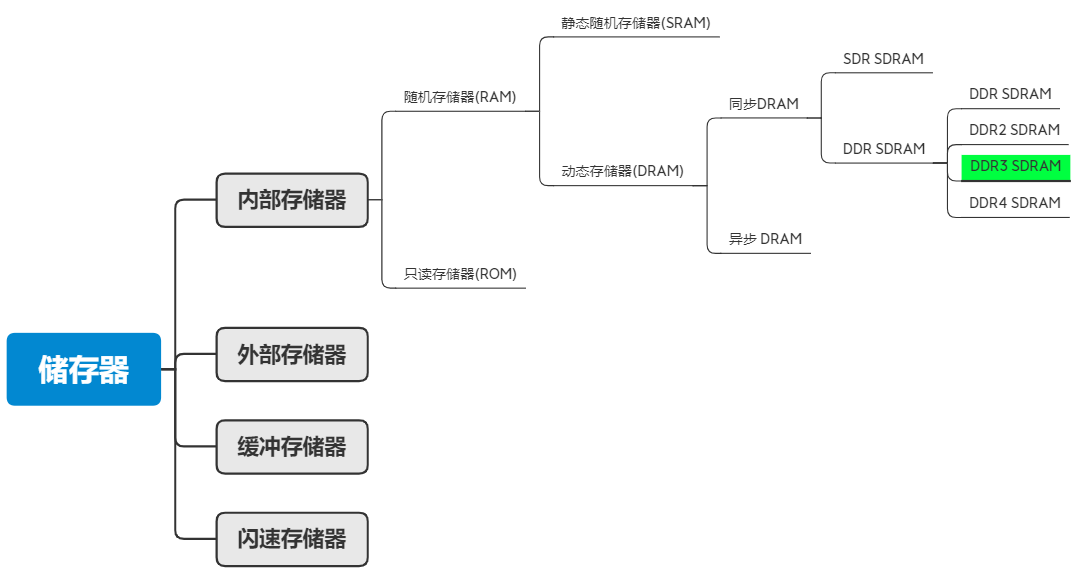
存储器家族庞大而复杂,但是总体上分类清晰明确。下面这张脑图指示出了DDR3技术所在的技术位置,这有利于我们理解DDR3技术。

存储器一般来说可以分为内部存储器(内存),外部存储器(外存),缓冲存储器(缓存)以及闪存这几个大类。内存也称为主存储器,位于系统主机板上,可以同CPU直接进行信息交换。其主要特点是:运行速度快,容量小。
其中内存有多种不同的形式分别如下:
RAM(Random Access Memory) 随机存储器。存储单元的内容可按需随意取出或存入,且存取的速度与存储单元的位置无关的存储器。这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使用的程序。 按照存储信息的不同,随机存储器又分为静态随机存储器(Static RAM,SRAM)和动态随机存储器(Dynamic RAM,DRAM)。静态随机存储器SRAM(Static RAM)不需要刷新电路即能保存它内部存储的数据。
动态随机存储器DRAM(Dynamic RAM)则每隔一段时间,要刷新充电一次,否则内部的数据即会消失。
有一种动态随机存储器SDRAM(Synchronous DRAM)即同步动态随机存取存储器。同步是指 Memory工作需要同步时钟,内部的命令的发送与数据的传输都以它为基准;动态是指存储阵列需要不断的刷新来保证数据不丢失;随机是指数据不是线性依次存储,而是自由指定地址进行数据读写,DDR,DDR2以及DDR3就属于SDRAM的一类。当然DRAM对应的还有异步DRAM,只是好像比较少见。
同步SDRAM根据时钟边沿读取数据的情况分为SDR和DDR技术,DDR从发展到现在已经经历了四代,分别是:第一代DDR SDRAM,第二代DDR2 SDRAM,第三代DDR3 SDRAM,第四代,DDR4 SDRAM。
来自 <https://www.cnblogs.com/liujinggang/p/9782796.html>
好的,我们终于讲清楚了DDR3在庞大存储器家族中的技术分支上的位置。其实回头一看Double-Data-Rate Three Synchronous Dynamic Random Access Memory这个名字就已经清晰地表示了DDR3在技术图谱上的位置。
1.3基本技术原理
DDR里面主要使用了Double Data Rate 和 Prefetch两项技术。
实际上,无论是 SDR 还是 DDR 或 DDR2、3,内存芯片内部的核心时钟基本上是保持一致的,都是 100MHz 到 200MHz(某些厂商生产的超频内存除外)。
DDR即 Double Data Rate 技术使数据传输速度较 SDR 提升了一倍。如下图所示,SDR 仅在时钟的上升沿传输数据,而 DDR 在时钟信号上、下沿同时传输数据。例如同为133MHz 时钟,DDR 却可以达到 266Mb/s 的数传速度。

芯片内部数据数据传输速度的提升则是通过 Prefetch 技术实现的。
所谓 Prefetch 简单的说就是在一个内核时钟周期同时寻址多个存储单元并将这些数据以并行的方式统一传输到 IO Buffer 中,之后以更高的外传速度将 IO Buffer 中的数据传输出去。这个更高的速度在 DDR I 上就是通过 Double Data Rate 实现的,也正因为如此,DDR I 外部 Clock 管脚的频率与芯片内部的核心频率是保持一致的。如下图所示为 DDR I 的Prefetch 过程中,在 16 位的内存芯片中一次将 2 个 16bit 数据从内核传输到外部MUX 单元,之后分别在 Clock 信号的上、下沿分两次将这 2 x 16bit 数据传输给北桥或其他内存控制器,整个过程经历的时间恰好为一个内核时钟周期。

发展到 DDR2, 芯片内核每次 Prefetch 4 倍的数据至 IO Buffer 中,为了进一步提高外传速度,芯片的内核时钟与外部接口时钟(即我们平时接触到的Clock 管脚时钟)不再是同一时钟,外部 Clock 时钟频率变为内核时钟的 2 倍。同理, DDR3 每次 Prefetch 8 倍的数据,其芯片 Clock 频率为内核频率的 4 倍, 即 JEDEC标准(JESD79-3)规定的 400MHz 至 800MHz,再加上在 Clock 信号上、下跳变沿同时传输数据,DDR3 的数据传输速率便达到了 800MT/s 到 1600MT/s。具体到内存条速度,我们以 PC3-12800 为例,其采用的 DDR3-1600 芯片核心频率为 200MHz,经过Prefetch 后 Clock 信号频率到达 800MHz,再经过 Double Data Rate 后芯片数据传输速率为 1600 MT/s,内存条每次传输 64 bits或者说 8 bytes数据,1600*8 便得到12800MB/s 的峰值比特率。
1.4.技术演进和主要技术标准
下面这个表格来自维基百科,列举了DDR3的标准,我们可以看到各种标准的速率:

目前市面上比较主要的标准是DDR3-800和DDR3-1600。
看技术标准还是要回到官方标准。网上能找的文档是JESD79-3C的标准,发布于2008年。下面是下在链接。
http://mermaja.act.uji.es/docencia/is37/data/DDR3.pdf
比较新的标准应该JESD79-3F,但是网上下载不到。
为了更好地理解DDR技术的演进,可以看下面这张表格,对比了前三代DDR技术。

来自 <https://www.cnblogs.com/liujinggang/p/9782796.html>
二、DDR3技术细节
DDR3市场上芯片型号众多,参数也非常复杂,为了兼顾系统性和细节清晰,我们以MT41J128M8 为例进行介绍(网上有文章就是以这款芯片为列的),可以下载到完整的数据手册。
来自陶老师的吐槽:
贼讨厌棒子公司和部分国内公司,在网上很少看到他们的数据手册,神经病一样,明明公开卖一块芯片,却必须通过代理商去要数据手册,浪费工程师时间。
2.1管脚信号描述
管脚信号的解析其实涉及读写时序、工作电压、数据传输方式,这里我们先介绍管脚,先对DDR芯片有个直观的认识,等看完后面的内容在回过来看这里就觉得非常清楚了。
下图是MT41J128M8 的管脚图

2.1.1.电源线

2.1.2.时钟线

2.1.3.地址

2.1.4.数据线

2.1.5.控制线

2.1.6和处理器的连接框图
DDR3芯片管脚很多,看上去很乱,下面这是一个两片16bit DDR3和海思Hi3521的接线示意图。

这里可以下载到参考资料
http://www.datasheet-pdf.com/PDF/Hi3521-Datasheet-HiSilicon-1204692
2.2工作电压和频率
2.2.1工作电压
DDR1、DDR2 和 DDR3 存储器的电压分别为 2.5、1.8 和 1.5V,因此与采用 3.3V 的正常SDRAM 芯片组相比,它们在电源管理中产生的热量更少,效率更高。
DDR3 的工作电压降低至 1.5V,实际上 JEDEC 标准规定1.575V 为 DDR3 的最大安全工作电压。

2.2.2 工作频率速率
DDR的核心频率:
核心频率就是内存的工作频率,也就是前面图表中的内存时钟,一般是 100MHz 到 200MHz。
对于DDR3-1600,核心频率就是200MHz。
时钟频率:
时钟频率是指DDR芯片IO管脚CK和CK#上的时钟信号的频率。DDR3的时钟频率是核心频率的4倍。
对于DDR3-1600,时钟频率就是800MHz
数据传输频率:
DDR内存在IO时钟的上下边沿都传输数据,所以数据传输频率是时钟频率的2倍。
对于DDR3-1600,数据传输速率就是1600MT/s
一般我们以数据速率来表述DDR的速率。
2.3寻址和容量计算
2.3.1寻址
存储器就是一个巨大的仓库,里面存放了大量的数据,一个重要的工作就是确认每个数据存放在哪里。我们给每个最基础的存储单元一个地址,找到自动化个地址,我们就可以存放或者读取数据了,找到这个地址的过程就叫寻址。
DDR3芯片的寻址的流程是先指定Bank地址,再指定行地址,然后指列地址最终的确寻址单元。
一个内存条上往往有多个内存芯片。我们把其中一个128MB Chip拆开来看,以MT41J128M8 为例,它是由8个Bank组成,每个Bank核心是个一个存储矩阵,就像一个大方格子阵。这个格子阵有很多列(Column)和很多行(Row),这样我们想存取某个格子,只需要告知是哪一行哪一列就行了。
下图是DDR3内部Bank示意图,这是一个N*N的阵列,B1代表Bank地址编号,C代表列地址编号,R代表行地址编号。

2.3.2容量计算
存储单元的Bank数量、地址空间大小和数据宽度决定了一个内存芯片的容量大小,内存条上内存芯片的数量决定了内存条的大小。
MT41J128M8 的数据宽度是8位,每个bank有16k的行数,1k的列数,所以寻址空间是16k*1k=16M,每个芯片有8个bank,所以单块芯片的容量是8*(16k*1k)*8bit=1Gbit。
下图为MT41J128M8内部结构,行(Row)地址线复用14根,列(Column)地址线复用10根,Bank数量为8个,IO Buffer 通过8组数位线(DQ0-DQ7)来完成对外的通信。

如果我们要做成容量为1GB的内存条则需要8颗这样的DDR3内存芯片,每颗芯片含8根数位线(DQ0-DQ7)则总数宽为64bit,这样正好用了一个Rank。
假果还用128MB的DDR3芯片去做2GB内存条,结果就会有所不同。我们最好选用4根数位线(DQ0-DQ3),数量是16颗,这样也是用了一个Rank。
说明:构成CPU总线宽度的内存芯片的集合叫一个Rank。对于一个64bit的CPU,每个MT41J128M8 贡献8bit,8个MT41J128M8 构成一个Rank。前面讲的是芯片的寻址,所以没有讲Rank。
2.4数据操作
这块我现在还理解的不够透彻,整理的比较混乱,以后有时间再更新。
2.4.1.DDR3内部状态
下面这张图叫做Simplified State Diagram,当然,我感觉并不simple!硬件狗可以选择性跳过。

对上面这张图进行下面的操作拆解,就会看上去好多了。
1.启动:
上电->解复位->初始化->ZQCL->IDLE
2.读数据:
IDLE->行激活->读数据(一次或者多次突发)->预充电->IDLE
3.写数据
IDLE->行激活->写数据(一次或者多次突发)->预充电->IDLE
4.刷新:
IDLE->Refreshing->IDLE
5.自刷新:
IDLE->Self Refreshing->IDLE
6.自动定期校准
IDLE->ZQ Calibration->IDLE 一般在外部温度改变或者电压改变的时候进行
7.动态配置更新
IDLE->MRS、MPR->IDLE
接下来我们主要看读写数据操作,毕竟这是最频繁也是和硬件设计相关的操作。
2.4.2读写操作
DDR3的读时序的时序图如下图所示

一个完整的读操作包含以下步骤:
1.发出Acitive命令
2.发出读命令
3.数据经过一定延时传到端口。这个延时后面要细讲
4.将当前cache里面的数据刷回到存储阵列并关闭当前工作行(携带命令和BA信息),A10的电平决定了是否发布自动预充电命令
写入命令也是类似的,详见
https://wenku.baidu.com/view/ba28e6d533687e21af45a9fc.html?sxts=1576389460606
下表列举了一些命令执行时控制线上的电平。

接下来介绍几个概念,比较复杂
1.tRCD
在实际工作中,逻辑Bank地址与相应的行地址是同时发出的,此时这个命令称之为“行激活”(Row Active)。在此之后,将发送列地址寻址命令与具体的操作命令(是读还是写),这两个命令也是同时发出的,所以一般都会以“读/写命令”来表示列寻址。根据相关的标准,从行有效到读/写命令发出之间的间隔被定义为tRCD,即RAS to CAS Delay(RAS至CAS延迟,RAS就是行地址选通脉冲,CAS就是列地址选通脉冲),我们可以理解为行选通周期。tRCD是DDR的一个重要时序参数,广义的tRCD以核心时钟周期(tCK,Clock Time)数为单位,比如tRCD=3,就代表延迟周期为两个时钟周期,具体到确切的时间,则要根据时钟频率而定。以DDR3-800为例,通过上一节的学习可知,DDR3-800的数据传输频率(等效频率)为800MHz,由于DDR3的预取(Prefetch)位宽为8位,所以核心频率为100MHz(800MHz/8),核心时钟的周期为10ns,如果tRCD=3,则表示延时为30ns。

上图是tRCD=3的时序图,NOP=Not Operation,表示无操作,灰色区域表示Don’t Care。
2.CL
相关的列地址被选中以后,将会触发数据传输,但从存储单元中输出到真正出现在内存芯片的I/O接口之间还需要一定的时间(数据触发本身就有延时,而且还需要进行信号放大),这段时间就是列地址脉冲选通潜伏期(CAS Latency,CL),CL的数值与tRCD一样,以时钟周期数表示。比如DDR3-800的有效频率(传输数据频率)为800MHz,由于DDR3的预取数为8,所以核心频率为100MHz,核心周期为10ns,如果CL=2,那么就意味着列地址脉冲选通潜伏期为20ns。CL只针对读取操作有效。
3.tAC
由于芯片体积的原因,存储单元中的电容容量很小,所以信号要经过放大来保证其有效的识别性,这个放大/驱动工作由Sense Amplifier负责,一个存储体对应一个Sense Amplifier通道。但它要有一个准备时间才能保证信号的发送强度(事前还要进行电压比较以进行逻辑电平的判断),因此从数据I/O总线上有数据到数据输出之前的一个时钟上升沿开始,数据即已传向Sense Amplifier,也就是说此时数据已经被触发,经过一定的驱动时间最终传向数据I/O总线进行输出,这段时间我们称之为tAC(Access Time from CLK,时钟触发后的访问时间)。
Sense Amplifier在DDR结构中扮演的角色如下所示

tAC和CAS的示意图如下图所示

4.突发长度(Burst Lengths,简称BL)
目前内存的读写基本都是连续的,因为与CPU交换的数据量以一个Cache Line(即CPU内Cache的存储单位)的容量为准,一般为64字节。而现有的Rank位宽为8字节(64bit),那么就要一次连续传输8次,这就涉及到我们也经常能遇到的突发传输的概念。突发(Burst)是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输的周期数就是突发长度(Burst Lengths,简称BL)。
在进行突发传输时,只要指定起始列地址与突发长度,内存就会依次地自动对后面相应数量的存储单元进行读/写操作而不再需要控制器连续地提供列地址。这样,除了第一组数据的传输需要若干个周期(主要是之前的延迟,一般的是tRCD+CL)外,其后每个数据只需一个周期的即可获得。下图是CAS=2,BL=4时的时序图

突发连续读取模式:只要指定起始列地址与突发长度,后续的寻址与数据的读取自动进行,而只要控制好两段突发读取命令的间隔周期(与BL相同)即可做到连续的突发传输。
谈到了突发长度时。如果BL=4,那么也就是说一次就传送4×64bit的数据。但是,如果其中的第二组数据是不需要的,怎么办?还都传输吗?为了屏蔽不需要的数据,人们采用了数据掩码(Data I/O Mask,简称DQM)技术。通过DQM,内存可以控制I/O端口取消哪些输出或输入的数据。这里需要强调的是,在读取时,被屏蔽的数据仍然会从存储体传出,只是在“掩码逻辑单元”处被屏蔽。DQM由北桥控制,为了精确屏蔽一个P-Bank位宽中的每个字节,每个DIMM有8个DQM 信号线,每个信号针对一个字节。这样,对于4bit位宽芯片,两个芯片共用一个DQM信号线,对于8bit位宽芯片,一个芯片占用一个DQM信号,而对于 16bit位宽芯片,则需要两个DQM引脚。
5.行预充电有效周期tRP
在数据读取完之后,为了腾出读出放大器以供同一Bank内其他行的寻址并传输数据,内存芯片将进行预充电的操作来关闭当前工作行。还是以上面那个Bank示意图为例。当前寻址的存储单元是B1、R2、C6。如果接下来的寻址命令是B1、R2、C4,则不用预充电,因为读出放大器正在为这一行服务。但如果地址命令是B1、R4、C4,由于是同一Bank的不同行,那么就必须要先把R2关闭,才能对R4寻址。从开始关闭现有的工作行,到可以打开新的工作行之间的间隔就是tRP(Row Precharge command Period,行预充电有效周期),单位也是时钟周期数。
6.预充电
原本逻辑状态为1的电容在读取操作后,会因放电而变为逻辑0。由于SDRAM的寻址具有独占性,所以在进行完读写操作后,如果要对同一L-Bank的另一行进行寻址,就要将原先操作行关闭,重新发送行/列地址。在对原先操作行进行关闭时,DRAM为了在关闭当前行时保持数据,要对存储体中原有的信息进行重写,这个充电重写和关闭操作行过程叫做预充电,发送预充电信号时,意味着先执行存储体充电,然后关闭当前L-Bank操作行。预充电中重写的操作与刷新操作(后面详细介绍)一样,只不过预充电不是定期的,而只是在读操作以后执行的。
来自 <https://www.eda365.com/thread-66790-1-1.html>
7.数据选取脉冲(DQS)
DQS 是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每一颗芯片都有一个DQS信号线,它是双向的,在写入时它用来传送由北桥发来的DQS信号,读取时,则由芯片生成DQS向北桥发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,DQS生成时,芯片内部的预取已经完毕了,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。由于是并行传输,DDR内存对tAC也有一定的要求,对于DDR266,tAC的允许范围是±0.75ns,对于DDR333,则是±0.7ns,有关它们的时序图示见前文,其中CL里包含了一段DQS 的导入期。
DQS 在读取时与数据同步传输,那么接收时也是以DQS的上下沿为准吗?不,如果以DQS的上下沿区分数据周期的危险很大。由于芯片有预取的操作,所以输出时的同步很难控制,只能限制在一定的时间范围内,数据在各I/O端口的出现时间可能有快有慢,会与DQS有一定的间隔,这也就是为什么要有一个tAC规定的原因。而在接收方,一切必须保证同步接收,不能有tAC之类的偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。
2.5.DDR3中的几个技术
2.5.1 ODT(On-Die Termination)技术
ODT(On-Die Termination),是从DDR2 SDRAM时代开始新增的功能。其允许用户通过读写DDR2/3内部的MR1寄存器,来控制DDR3 SDRAM中各个信号内部终端电阻的连接或者断开。在DDR3 SDRAM中,ODT功能主要应用于:
1、DQ, DQS, DQS# and DM for X4 configuration
2、DQ, DQS, DQS#, DM, TDQS and TDQS# for X8 configuration
3、DQU, DQL, DQSU, DQSU#, DQSL, DQSL#, DMU and DML for X16 configuration
ODT(On-Die Termination)技术的目的是通过使DDR SDRAM控制器能够独立的打开或者关断DDR内部的终端电阻来提高存储器通道的信号完整性,在DLL关闭模式,ODT功能被禁用。
一个DDR通道,通常会挂接多个Rank,这些Rank的数据线、地址线等等都是共用;数据信号也就依次传递到每个Rank,到达线路末端的时候,波形会有反射,从而影响到原始信号;因此需要加上终端电阻,吸收余波。之前的DDR,终端电阻做在板子上,但是因为种种原因,效果不是太好,到了DDR2,把终端电阻做到了DDR颗粒内部,也就称为On Die Termination,Die上的终端电阻,Die是硅片的意思,这里也就是DDR颗粒。
ODT技术具体的内部结构图如下:

等效结构如下图所示

ODT终端电阻的电阻值RTT可通过模式寄存器MR1的A9,A6,A2来进行设置,设置的真值表为:

总的来说,ODT技术有以下三个优点:
1、去掉了主板上的终结电阻器等电器元件,这样会大大降低主板的制造成本,并且也使主板的设计更加简洁。
2、由于ODT技术可以迅速的开启和关闭空闲的内存芯片,在很大程度上减少了内存闲置时的功率消耗。
3、芯片内部终结电阻也要比主板的终端电阻具有更好的信号完整性。这也使得进一步提高DDR2内存的工作频率成为可能。
来自 <https://www.cnblogs.com/liujinggang/p/9782796.html>
2.5.2 write leveling
DR3 由于采取了fly by的结构,导致DQS和CK信号之间在DIMM条上存在一定延迟。
Write leveling就是用来调节DQS,CK在DIMM条上之间的相位关系使之满足tDQSS(注意这里的tDQSS是DDR3颗粒的时序要求)
Wrtie leveling是一个完全自动的过程,只要控制器支持write leveling就可以进行。
CPU不停的发送不同时延的DQS信号,颗粒会通过输入的DQS来采样输入的CK信号,如果采样到的CK信号一直为低,则会将DQ保持为低电平来告知控制器tDQSS相位关系还未满足,如果发现在某个DQS到来时,采样到此时的CK电平发现了迁越(由之前的低跳变为高),则认为此时DQS和CK已经满足tDQSS同时通过DQ向控制器发送一个高。此时就完成了一个write leveling过程。
最终调节的结果是由控制器来控制DQS的时延。如图:

来自 <https://www.cnblogs.com/fbi888/p/3154861.html>
三、PCB设计
3.1 互联通路拓扑
信号DQ、DM和DQS都是点对点的互联方式,所以不需要任何的拓扑结构,然而列外的是,在multi-rank DIMMs(Dual In Line Memory Modules)的设计中并不是这样的。在点对点的方式时,可以很容易的通过ODT的阻抗设置来做到阻抗匹配,从而实现其波形完整性。而对于 ADDR/CMD/CNTRL和一些时钟信号,它们都是需要多点互联的,所以需要选择一个合适的拓扑结构,下面的图中列出了一些相关的拓扑结构,其中Fly- By拓扑结构是一种特殊的菊花链,它不需要很长的连线,甚至有时不需要短线(Stub)。
对于DDR3,下面所有的拓扑结构都是适用的,然而前提条件是走线要尽可能的短。Fly-By拓扑结构在处理噪声方面,具有很好的波形完整性,然而在一个4 层板上很难实现,需要6层板以上,而菊花链式拓扑结构在一个4层板上是容易实现的。另外,树形拓扑结构要求AB的长度和AC的长度非常接近(如图2)。考虑到波形的完整性,以及尽可能的提高分支的走线长度,同事又要满足板层的约束要求,在基于4层板的DDR3设计中,最合理的拓扑结构就是带有最少短线(Stub)的菊花链式拓扑结构。

对于DDR2-800,这所有的拓扑结构都适用,只是有少许的差别。然而,菊花链式拓扑结构被证明在SI方面是具有优势的。
对于超过两片的SDRAM,通常,是根据器件的摆放方式不同而选择相应的拓扑结构。图3显示了不同摆放方式而特殊设计的拓扑结构,在这些拓扑结构中,只有A和 D是最适合4层板的PCB设计。然而,对于DDR2-800,所列的这些拓扑结构都能满足其波形的完整性,而在DDR3的设计中,特别是在1600 Mbps时,则只有D是满足设计的。

关于Fly-By的更多讨论可以参考
https://zhuanlan.zhihu.com/p/21281735
3.2 布线约束
对于数据线,每个BYTE与各自的DQS,DQM等长,即DQ0:7与DQS0,DQM。等长,DQ8:15与DQS1,DQM1等长,以此类推。
地址线的等长往往需要过孔来配合,具体的规则均绑定在过孔上和VTT端接电阻上,如下图。可以看到,CPU的地址线到达过孔的距离等长,过孔到达VTT端接电阻的距离也等长。
3.3. PCB的叠层(stackup)和阻抗
对于一块受PCB层数约束的基板(如4层板)来说,其所有的信号线只能走在TOP和BOTTOM层,中间的两层,其中一层为GND平面层,而另一层为 VDD 平面层,Vtt和Vref在VDD平面层布线。而当使用6层来走线时,设计一种专用拓扑结构变得更加容易,同时由于Power层和GND层的间距变小了,从而提高了PI。
互联通道的另一参数阻抗,在DDR2的设计时必须是恒定连续的,单端走线的阻抗匹配电阻50 Ohms必须被用到所有的单端信号上,且做到阻抗匹配,而对于差分信号,100 Ohms的终端阻抗匹配电阻必须被用到所有的差分信号终端,比如CLOCK和DQS信号。另外,所有的匹配电阻必须上拉到VTT,且保持50 Ohms,ODT的设置也必须保持在50 Ohms。
在 DDR3的设计时,单端信号的终端匹配电阻在40和60 Ohms之间可选择的被设计到ADDR/CMD/CNTRL信号线上,这已经被证明有很多的优点。而且,上拉到VTT的终端匹配电阻根据SI仿真的结果的走线阻抗,电阻值可能需要做出不同的选择,通常其电阻值在30-70 Ohms之间。而差分信号的阻抗匹配电阻始终在100 Ohms。

3.4. Layout
在实际的PCB设计时,考虑到SI的要求,往往有很多的折中方案。通常,需要优先考虑对于那些对信号的完整性要求比较高的。画PCB时,当考虑一下的一些相关因素,那么对于设计PCB来说可靠性就会更高。
1. 首先,要在相关的EDA工具里要设置好里设置好拓扑结构和相关约束。
2. 将BGA引脚突围,将ADDR/CMD/CNTRL引脚布置在DQ/DQS/DM字节组的中间,由于所有这些分组操作,为了尽可能少的信号交叉,一些独立的管脚也许会被交换到其它区域布线。
3. 由串扰仿真的结果可知,尽量减少短线(stubs)长度。通常,短线(stubs)是可以被削减的,但不是所有的管脚都做得到的。在BGA焊盘和存储器焊盘之间也许只需要两段的走线就可以实现了,但是此走线必须要很细,那么就提高了PCB的制作成本,而且,不是所有的走线都只需要两段的,除非使用微小的过孔和盘中孔的技术。最终,考虑到信号完整性的容差和成本,可能选择折中的方案。
4. 将Vref的去耦电容靠近Vref管脚摆放;Vtt的去耦电容摆放在最远的一个SDRAM外端;VDD的去耦电容需要靠近器件摆放。小电容值的去耦电容需要更靠近器件摆放。正确的去耦设计中,并不是所有的去耦电容都是靠近器件摆放的。所有的去耦电容的管脚都需要扇出后走线,这样可以减少阻抗,通常,两端段的扇出走线会垂直于电容布线。
5. 当切换平面层时,尽量做到长度匹配和加入一些地过孔,这些事先应该在EDA工具里进行很好的仿真。通常,在时域分析来看,差分线里的两根线的要做到延时匹配,保证其误差在+/- 2ps,而其它的信号要做到+/- 10 ps。
在DDR3中,VREF分成两部分:
一个是为命令与地址信号服务的VREFCA;另一个是为数据总线服务的VREFDQ。
在布局时,VREFCA、VREFDQ的滤波电容及分压电阻要分别靠近芯片的电源引脚,如图所示。

匹配电阻的布局
为了提高信号质量,地址、控制信号一般要求在源端或终端增加匹配电阻;数据可以通过调节ODT 来实现,所以一般建议不用加电阻。
布局时要注意电阻的摆放,到电阻端的走线长度对信号质量有影响。
布局原则如下:
对于源端匹配电阻靠近CPU(驱动)放,而对于并联端接则靠近负载端(FLy-BY靠近最后一个DDR3颗粒的位置放置而T拓扑结构是靠近最大T点放置)
而对于终端VTT上拉电阻要放置在相应网络的末端,即靠近最后一个DDR3颗粒的位置放置(T拓扑结构是靠近最大T点放置);注意VTT上拉电阻到DDR3颗粒的走线越短越好;走线长度小于500mil;每个VTT上拉电阻对应放置一个VTT的滤波电容(最多两个电阻共用一个电容);VTT电源一般直接在元件面同层铺铜来完成连接,所以放置滤波电容时需要兼顾两方面,一方面要保证有一定的电源通道,另一方面滤波电容不能离上拉电阻太远,以免影响滤波效果。

四、DDR3仿真
《HyperLynx 高速电路仿真实战》这本书的第10章讲解了DDR的仿真。可以去网上购买电子书。
小秘密:
我有电子版的,点赞后私信我,我可以告诉你怎么搞到,嘿嘿嘿!
五、参考资料
1.DDR3的工作原理
https://wenku.baidu.com/view/ba28e6d533687e21af45a9fc.html?sxts=1576389460606
2.DDR3 write leveling
https://www.cnblogs.com/fbi888/p/3154861.html
3.DDR3内存详解
http://www.360doc.com/content/14/0116/16/15528092_345730642.shtml
4.内存系列二:深入理解硬件原理
https://zhuanlan.zhihu.com/p/26327347
5.PCB设计要点-DDR3布局布线技巧及注意事项
https://zhuanlan.zhihu.com/p/24404369
6.FLY-BY,你不可不知的两大布线细节
https://zhuanlan.zhihu.com/p/21281735
后记
收集资料两周,花了一整个周末,写了好久,感觉眼睛都快写瞎了,但是PCB设计和仿真这块还是没有好好写,后面有时间在好好写一下,就比较完整了。
欢迎关注我的专栏,我会保持更新。
DRAM基本原理
文章标签: 职场和发展
版权
多个bank引入是为了解决bank内的读写间隙问题。如果一直操作同一个bank,比如读取完第一行再读取第二行,那么行与行之间要进行precharge,这个引入了读写间隙,降低io的利用率。因此我们可以在第一个bank precharge的时候操作第二个bank,就可以实现pipeline的读写。
跨BG的操作中间等待的时间,比同BG跨bank操作中间的等待时间短。本来两个bank之间的时间虽然比较短,但还不至于让两笔burst连起来,现在由于BG之间控制电路并行,两个BG之间的操作可以合并在一起,例如两个BL8可以拼成一个BL16。并且BG的引入不会增加预取数。
要从内存中读出,你要提供一个地址,而要向它写入,你还要提供数据。这个由用户提供的地址,通常被称为 "逻辑地址"。
这个逻辑地址在被提交给DRAM之前被翻译成物理地址。物理地址是由以下字段组成的:
• Bank Group
• Bank
• Row #行
• Column #列
然后,这些单独的字段被用来识别内存中的确切位置,以便进行读出或写入
再继续往下看,这就是你将在每个bank中看到的内容。
• Memory Arrays #内存阵列
• Row Decoder #行解码器
• Column Decoder #列解码器
• Sense Amplifiers #感应放大器
一旦识别了Bank Group和Bank,地址的Row部分将激活内存阵列中的一行。这一行称为word line(字线) ,激活它会将数据从内存阵列读取到Sense Amplifiers感应放大器 中。然后,列地址读出加载到Sense Amplifiers感应放大器 中的 部分字。列的宽度称为Bit Line(位线) 【即部分字的宽度】
列的宽度是标准的 - 它是 4 位、8 位或 16 位宽,DRAM 根据此列宽分为 x4、x8 或 x16。另外需要注意的是,DQ 数据总线的宽度与列宽相同。因此,为简化起见,您可以说 DRAM 是根据 DQ 总线的宽度进行分类的。
类比时间:一块DRAM芯片相当于一栋满是文件柜的大楼
Bank Group → 确定楼层
Bank Address → 确定你所需要的文件在该楼层的文件柜
Row Address → 识别文件在柜子里的哪个抽屉。将数据读入感应放大器,相当于打开/拉出文件抽屉。
Col Address → 识别该抽屉内的文件编号
在最底层,一个比特本质上是一个保持电荷的电容和一个充当开关的晶体管。
由于电容会随着时间的推移而放电,除非定期对电容器进行刷新,否则信息最终会消失。这就是DRAM中 "D "它指的是动态,而不是SRAM(静态随机存取存储器)

访问内存
• 对DDR4 SDRAM的读和写操作是以突发为导向的。它从一个选定的位置开始(由用户提供的地址指定),并继续进行4个或8个突发长度。
• 读取和写入操作是一个两步过程。它以 ACTIVATE 命令开始(ACT_n 和 CS_n 在一个时钟周期内变为低电平),然后是 RD 或 WR 命令。
• 与 ACTIVATE 命令同时注册的地址位用于选择要激活的 Bank Group、Bank和Row(x4/8 中的 BG0-BG1 和 x16 中的 BG0 选择 bank group;BA0-BA1 选择 bank;A0-A17 选择row)。此步骤也称为RAS - Row Address Strobe(RAS -行地址选通)
• 与读或写命令同时注册的地址位用于选择突发操作的起始列位置。此步骤也称为CAS - Column Address Strobe(CAS -列地址选通)。
• 每个bank只有一组感应放大器。在对同一bank的不同行进行读/写之前,必须使用PRECHARGE命令解除当前打开的row的激活。PRECHARGE相当于关闭柜子里当前的文件抽屉,它使感应放大器中的数据被写回row中。
• 可以使用 RDA(自动预充电读取)和 WRA(自动预充电写入)命令,而不是发出显式 PRECHARGE 命令来停用行。这些命令告诉 DRAM 在读取或写入操作完成后自动停用/预充电行。由于列地址只使用地址位A0-A9,A10在CAS期间是一个未使用的位,它被重载以指示自动预充电。
DRAM子系统
ASIC或FPGA需要什么来与DRAM对话。这就是所谓的DRAM子系统,它由三个部分组成:
• DRAM存储器本身,包括上述的所有内容
• DDR PHY物理层:PHY包含模拟驱动器,并提供调整寄存器的能力,以增加驱动强度或变更终止,以改善信号完整性。
• DDR控制器
• DRAM 被焊接在板上。 PHY 和控制器以及用户逻辑通常是同一 FPGA 或 ASIC 的一部分。
• 用户逻辑和控制器之间的接口可以是用户定义的,不需要是标准的。
• 当用户逻辑向控制器发出读或写请求时,它会发出一个逻辑地址
• 然后控制器将此逻辑地址转换为物理地址并向 PHY 发出命令。
• 控制器和 PHY 通过称为 DFI 接口的标准接口相互通信。















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









