







课程链接:YOLOv10原理与实战训练自己的数据集_在线视频教程-CSDN程序员研修院
YOLOv10是最近提出的YOLO的改进版本。在后处理方面,提出了一致性双重分配策略用于无NMS训练,从而实现了高效的端到端检测。在模型架构方面,引入了全面的效率-准确性驱动模型设计策略,改善了性能-效率权衡。
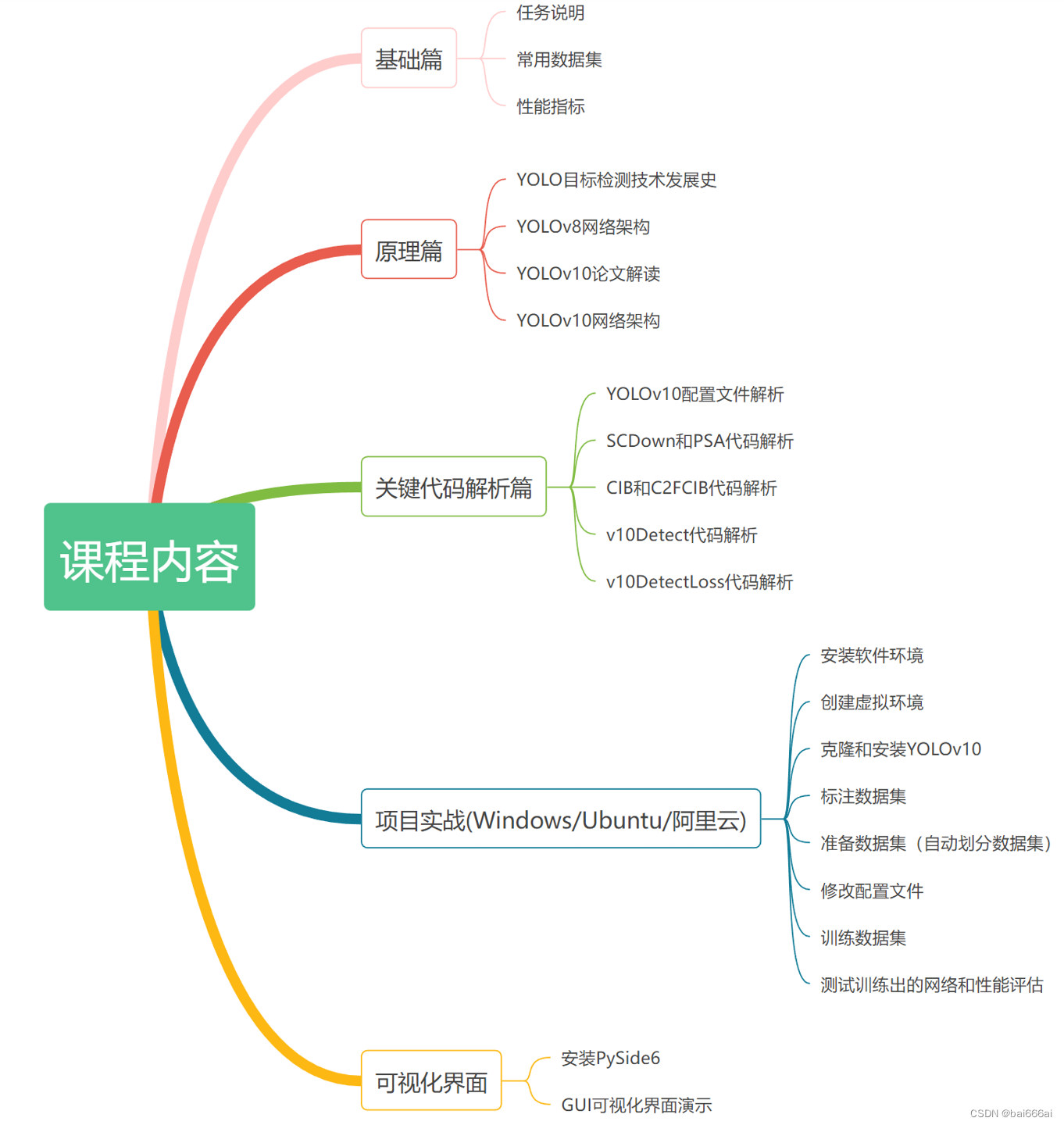
本课程讲解YOLOv10的论文、网络架构等原理并解析关键代码,并进行训练自己数据集的项目实战。
本课程将手把手地教大家使用labelImg标注和使用YOLOv10训练自己的数据集,完成一个多目标检测实战项目,可检测图像和视频中的足球和梅西两个目标类别。
本课程分别在Windows、Ubuntu和阿里云免费GPU算力平台上做手把手的项目操作演示。GPU免费算力的领取方式和阿里云平台上的项目实战操作流程可见课程视频。
课程项目内容包括:安装软件环境(Nvidia显卡驱动、cuda和cudnn)、安装PyTorch、安装YOLOv10、使用labelImg标注自己的数据集、准备自己的数据集(自动划分训练集和验证集)、修改配置文件、训练自己的数据集、测试训练出的网络模型和性能统计。
课程还提供PySide6开发的YOLOv10的可视化界面代码并进行了操作演示。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











