







最近在学习飞桨(PaddlePaddle),在看官方文档时感觉内容很多,有点混乱,同时也发现PaddlePaddle官网上的一些说明文档与Github上的描述不一致,在学习的时候有时会有感到困惑。所以想自己从说明文档中摘出之前自己感到困惑的部分内容,方便以后自己归纳学习。
1. 简介
Paddle-Lite 框架不同于普通的移动端预测基于类 Caffe 的架构,Lite 架构最早的设计目标来源于 Paddle Server 和 Mobile 两种场景的要求,其中 Server 端需要有完善的图分析和优化能力,而 Mobile 端要求有轻量级部署的能力,两种场景共同的要求是高性能,多硬件支持等。
因此,Paddle-Lite 框架作为 PaddleMobile 新一代架构,重点支持移动端推理预测,特点高性能、多硬件、轻量级。支持PaddleFluid/TensorFlow/Caffe/ONNX模型的推理部署,目前已经支持 ARM CPU, Mali GPU, Adreno GPU, Huawei NPU 等多种硬件,正在逐步增加 X86 CPU, Nvidia GPU 等多款硬件,相关硬件性能业内领先。
除此之外,Paddle-Lite 框架还具有许多其他的有点,总结列举如下:多硬件支持、高性能、量化支持、轻量级部署、强大的图分析和优化能力、支持任意硬件的混合调度。
2. PaddleLite是如何工作的?
如下图所示, Paddle Lite 整个推理的过程,可以简单分成分析( Analysis phase )和执行( Execution phase )两个阶段,分析阶段包括 Paddle 模型文件的加载和解析、计算图的转化、图分析和优化、运行时程序的生成和执行等步骤。每个步骤的具体操作过程如下面的流程图所示,详细解析请看下面每个小节的内容在这里插入代码片。
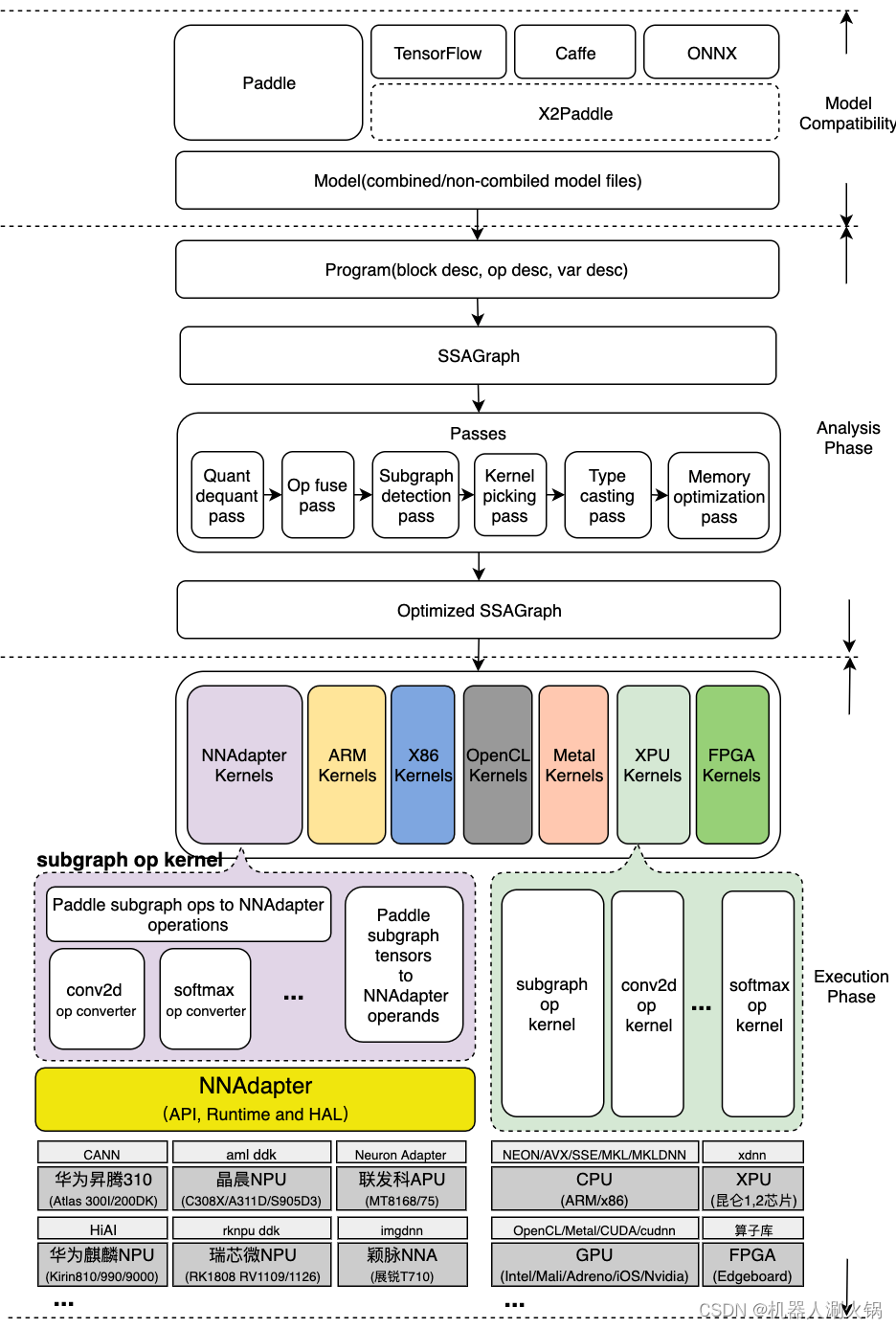
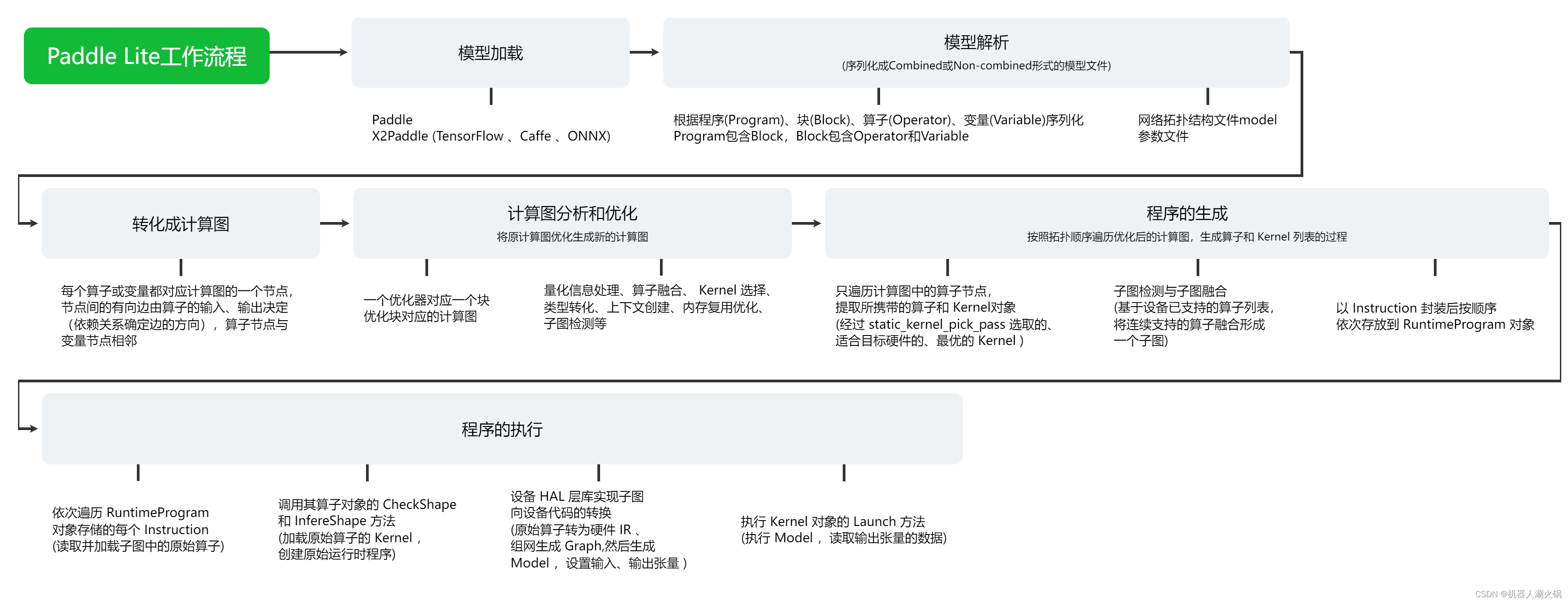
2.1 模型文件的加载和解析
Paddle 模型由程序( Program )、块( Block )、算子( Operator )和变量( Variable )组成(如下图所示,程序由若干块组成,块由若干算子和变量组成,变量包括中间变量和持久化变量,如卷积的权值),经序列化保存后形成 Combined 和 Non-combined 两种形式的模型文件, Non-combined 形式的模型由一个网络拓扑结构文件 model 和一系列以变量名命名的参数文件组成, Combined 形式的模型由一个网络拓扑结构文件 model 和一个合并后的参数文件 params 组成,其中网络拓扑结构文件是基于 Protocol Buffers 格式以 Paddle proto 文件规则序列化后的文件。现在以 Non-combined 格式的 Paddle 模型为例,将网络拓扑结构文件(要求文件名必须是 model )拖入到 Netron 工具即可图形化显示整个网络拓扑结构。
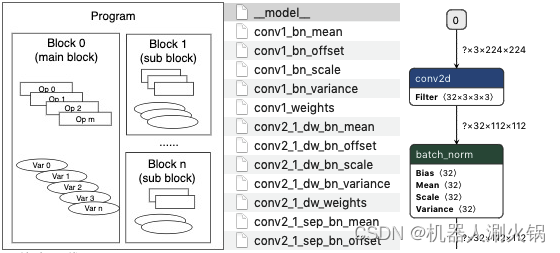
了解更多细节,可以访问具体的代码实现
2.2 计算图的转化
将每个块按照如下规则生成对应的计算图的过程:每个算子或变量都对应计算图的一个节点,节点间的有向边由算子的输入、输出决定(依赖关系确定边的方向),算子节点与变量节点相邻。为了方便调试,分析阶段的各个步骤都会将计算图的拓扑结构以 DOT 格式的文本随 log 打印,可以将 DOT 文本复制、粘贴到 webgraphviz 进行可视化,如下图所示,黄色矩形节点为算子,椭圆形节点为变量。
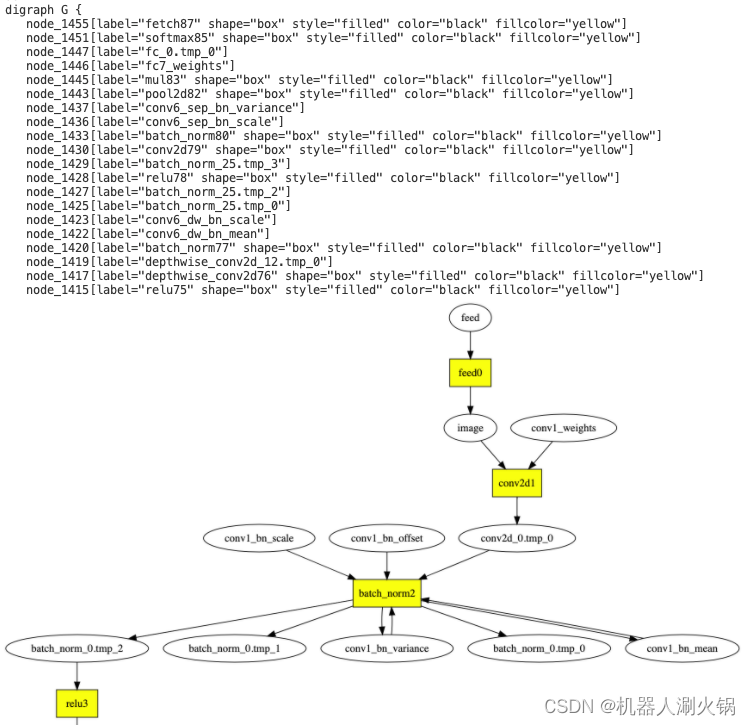
了解更多细节,可以访问具体代码实现
2.3 图分析和优化
将一系列 pass (优化器,用于描述一个计算图优化生成另一个计算图的算法过程)按照一定的顺序依次应用到每个块对应的计算图的过程,包括量化信息处理、算子融合、 Kernel 选择、类型转化、上下文创建、内存复用优化和子图检测等,实现不同设备的适配、高效的计算和更少的内存占用。其中,算子融合作为一种行之有效的优化策略,普遍存在于各种推理框架中,它通过相邻算子间的融合,减少访存和计算量,有效提高模型的整体性能,例如前一步骤的计算图中, conv_bn_fuse_pass 、 conv_activation_fuse_pass 分别以 conv2d + batch_norm 和 conv2d + relu 为 pattern ,先后搜索整个计算图并完成融合,如下图所示, conv2d + batch_norm + relu 结构,经过前面的 pass 处理后只保留了 1 个 conv2d 算子。

了解更多细节,可以访问具体代码实现
Pass 的注册方法、管理机制可以参考文档新增 Pass , Pass 列表是指按照规定的顺序处理的 Pass 的集合,它使用 std::vectorstd::string 存储,每个元素代表已注册到框架的 Pass 的名称,如果需要在 Pass 列表中新增一个 Pass ,只需在合适的位置增加一个字符串即可,例如,为了可视化 conv_bn_fuse_pass 优化后的计算图,可以在它后面增加一个名为 graph_visualize_pass 的特殊 Pass ,用于在 log 中生成以 DOT 文本的表示计算图结构。
diff --git a/lite/core/optimizer/optimizer.cc b/lite/core/optimizer/optimizer.cc
--- a/lite/core/optimizer/optimizer.cc
+++ b/lite/core/optimizer/optimizer.cc
class Optimizer {
"weight_quantization_preprocess_pass", //
"lite_conv_elementwise_fuse_pass", // conv-elemwise-bn
"lite_conv_bn_fuse_pass", //
+ "graph_visualize_pass",
"lite_conv_elementwise_fuse_pass", // conv-bn-elemwise
"lite_conv_conv_fuse_pass", //
// TODO(Superjomn) Refine the fusion related design to select fusion
2.4 运行时程序的生成和执行
按照拓扑顺序遍历优化后的计算图,生成算子和 Kernel 列表的过程,它基于 generate_program_pass 实现。具体地,只遍历计算图中的算子节点,提取所携带的算子和 Kernel (经过 static_kernel_pick_pass 选取的、适合目标硬件的、最优的 Kernel )对象,以 Instruction 封装后按顺序依次存放到 RuntimeProgram 对象。运行时程序的执行也非常简单,即依次遍历 RuntimeProgram 对象存储的每个 Instruction ,调用其算子对象的 CheckShape 和 InfereShape 方法,最后执行 Kernel 对象的 Launch 方法。
来源: https://paddle-lite.readthedocs.io/zh/develop/develop_guides/add_hardware.html
















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











