







本文讲的都是建模后的可解释性方法。建模之前可解释性方法或者使用本身具备可解释性的模型都不在本文范围内~
模型通常会考虑以下问题:
- 哪些特征在模型看到是最重要的?
- 从大量的记录整体来考虑,每一个特征如何影响模型的预测的?
- 关于某一条记录的预测,每一个特征是如何影响到最终的预测结果的?
这就是可解释性机器学习需要解决的问题,也是他的价值所在:
- 可靠性
- 易于调试
- 启发特征工程思路
- 指导后续数据采集的方向
- 指导人为决策
- 建立模型和人之间的信任
本文主要讲三种方法:
- 特征重要性(模型自带Feature Importance)
- Permutation Importance
- SHAP
当然,还有很多其他方法,部分依赖图(PDP)和个体条件期望图(ICE)、局部可解释不可知模型(LIME)、RETAIN、逐层相关性传播(LRP)。本文只写了我接触到的一小部分哈,实际工作用到可在拓展学习。
1、特征重要性(Feature Importance)
- 特征重要性的作用 -> 快速的让你知道哪些因素是比较重要的,但是不能得到这个因素对模型结果的正负向影响,同时传统方法对交互效应的考量会有些欠缺。
- 如果想要知道哪些变量比较重要的话。可以通过模型的feature_importances_方法来获取特征重要性。例如xgboost的feature_importances_可以通过特征的分裂次数或利用该特征分裂后的增益来衡量。
- 计算方法是:Mean Decrease Impurity。思想:一个特征的意义在于降低预测目标的不确定性,能够更多的降低这种不确定性的特征就更重要。即特征重要性计算依据某个特征进行决策树分裂时,分裂前后的信息增益(基尼系数).
import pandas as pd
from sklearn.datasets import load_iris
import xgboost as xgb
iris = load_iris()
df = pd.DataFrame(iris.data,columns=iris.feature_names) #转化成DataFrame格式
target = iris.target
xgb_model = xgb.XGBClassifier()
clf = xgb_model.fit(df.values, target)
a=clf.feature_importances_
features = pd.DataFrame(sorted(zip(a,df.columns),reverse=True))2、Permutation Importance
常规思路,很容易想到,在训练模型的时候可以直接输出特征重要性,但这个特征对整体的预测效果有多大影响?可以用Permutation Importance(排列重要性)进行计算。
PI思想:基于“置换检验”的思想对特征重要性进行检测,,一定是在model训练完成后,才可以计算的。简单来说,就是改变数据表格中某一列的数据的排列,保持其余特征不动,看其对预测精度的影响有多大。
计算步骤:
1、用上全部特征,训练一个模型。
2、验证集预测得到得分。
3、验证集的一个特征列的值进行随机打乱,预测得到得分。
4、将上述得分做差即可得到特征x1对预测的影响。
5、依次将每一列特征按上述方法做,得到每二个特征对预测的影响。
- 我们使用ELI5库可以进行Permutation Importance的计算。
- ELI5是一个可以对各类机器学习模型进行可视化和调试Python库,并且针对各类模型都有统一的调用接口。
- ELI5中原生支持了多种机器学习框架,并且也提供了解释黑盒模型的方式。
import eli5
from eli5.sklearn import permutationImportance
perm = PermutationImportance(xgb_model, random_state = 1).fit(df, target) # 实例化
eli5.show_weights(perm)
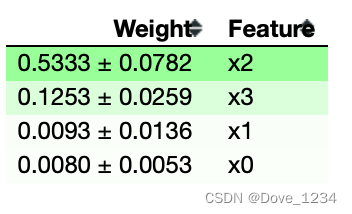
结果分析:
- 靠近上方的绿色特征,表示对模型预测较为重要的特征;
- 为了排除随机性,每一次 shuffle 都会进行多次,然后取结果的均值和标准差;
- ±后面的数字表示多次随机重排之间的差异值。
这个例子里,最重要的特征是第三个 ‘petal length (cm)’, 和feature_importances_输出结果一致。
3、SHAP(SHapley Additive exPlanation)
以上都是全局可解释性方法,那局部可解释性,即单个样本来看,模型给出的预测值和某些特征可能的关系,这就可以用到SHAP。
当然shap也有全局可解释性哈,本文不介绍~
SHAP 属于模型事后解释的方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。
SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。
对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。
基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAP baseline value.
SHAP(SHapley Additive exPlanation)是Python开发的一个"模型解释"包,可以解释任何机器学习模型的输出。
import shap #Python的可解释机器学习库 pip install shap
shap.initjs() # notebook环境下,加载用于可视化的JS代码
#模型还是用之前训练的
#xgb_model = xgb.XGBClassifier()
#clf = xgb_model.fit(df.values, target)
#在SHAP中进行模型解释需要先创建一个explainer,
#SHAP支持很多类型的explainer(例如deep, gradient, kernel, linear, tree, sampling)
#我们先以tree为例,因为它支持常用的XGB、LGB、CatBoost等树集成算法。
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(df) # 传入特征矩阵,计算SHAP值
j = 60
y_base = explainer.expected_value
player_explainer = pd.DataFrame()
player_explainer['feature'] = df.columns
player_explainer['feature_value'] = df.iloc[j].values
player_explainer['shap_value_1'] = shap_values[1][j]
player_explainer
# len(shap_values)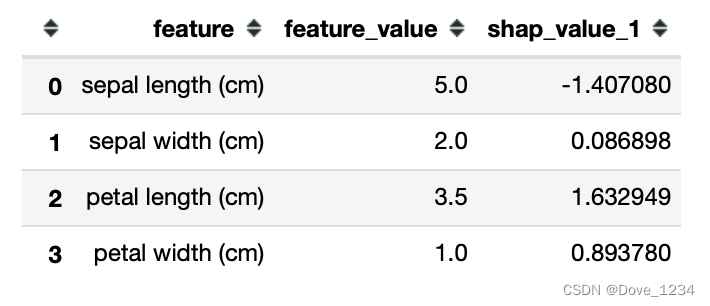
# 可视化一个prediction的解释 如果不想用JS,传入matplotlib=True
shap.force_plot(explainer.expected_value[1], shap_values[1][j], df.iloc[j,:])
结果分析:
- base value:全体样本Shap平均值,模型在数据集上的输出均值0.5671;
- f(x):当前样本的Shap输出值,模型在单个样本的输出值1.84;
- 正向作用特征:petal length (cm)取值为3.5,petal length(cm)取值为1,具有正向影响;长度表示特征影响的程度。
- 反向作用的特征:sepal length (cm)取值为5,具有有负向影响。
- 引起预测降低的特征值是蓝色的,最大的影响源自 sepal length (cm)=5 的时候,但 petal length (cm)= 3.5 的值则对提高预测的值具有比较有意义的影响;所有特征共同作用下预测结果为1.84。
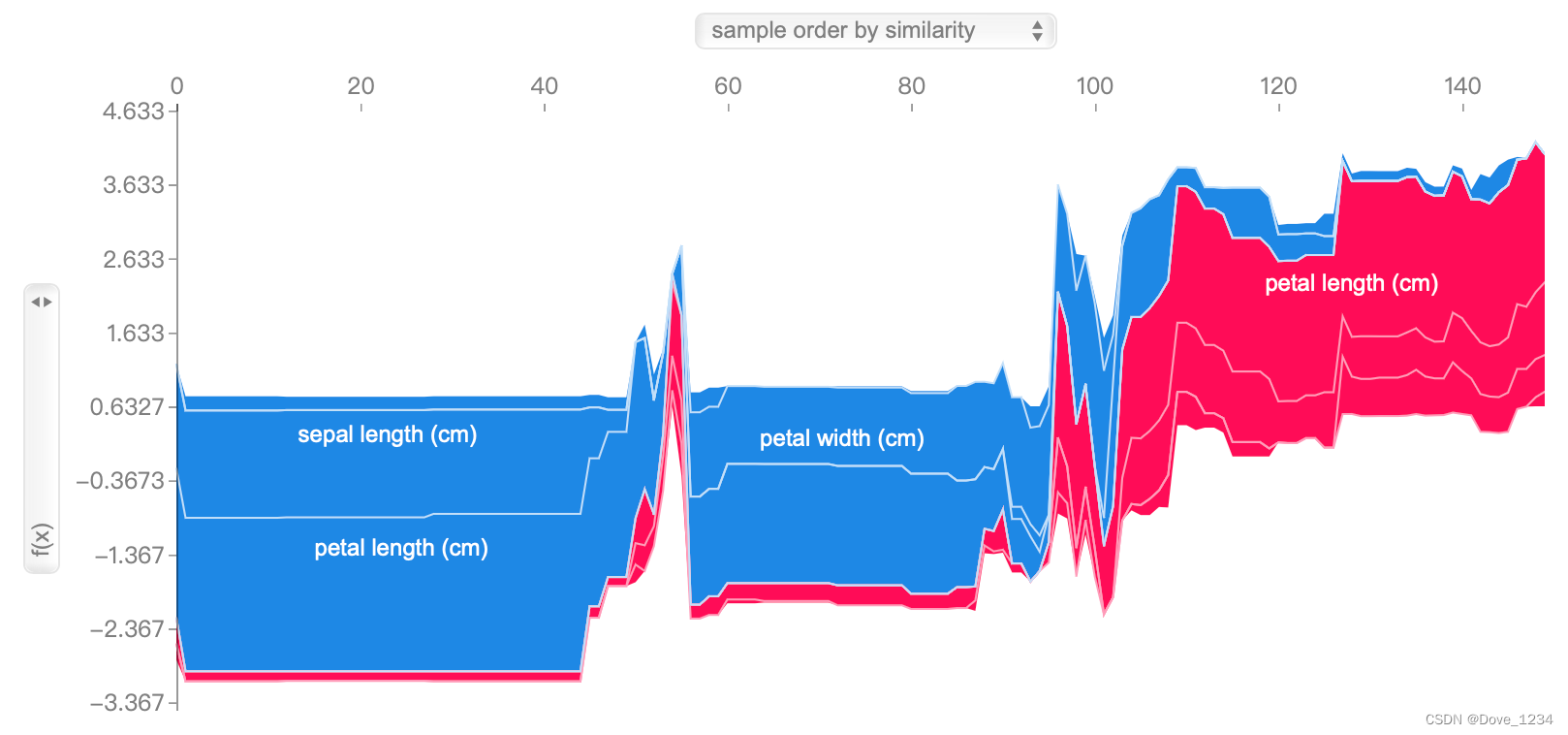
#多个预测的解释
shap.force_plot(explainer.expected_value[1], shap_values[1], df) #鼠标可以放图上面显示具体数值
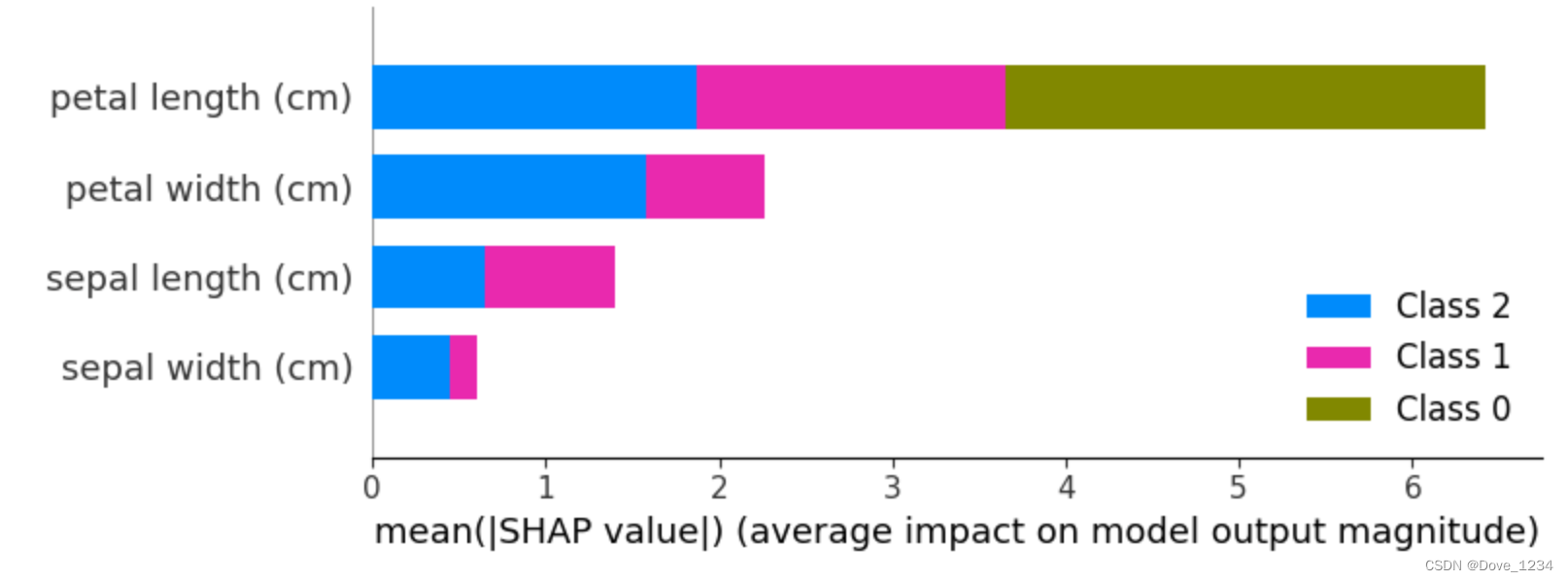
整体特征重要性:
#summary plot 为每个样本绘制其每个特征的SHAP值,这可以更好地理解整体模式,并允许发现预测异常值。
shap.summary_plot(shap_values, df)
shap.summary_plot(shap_values[1], df)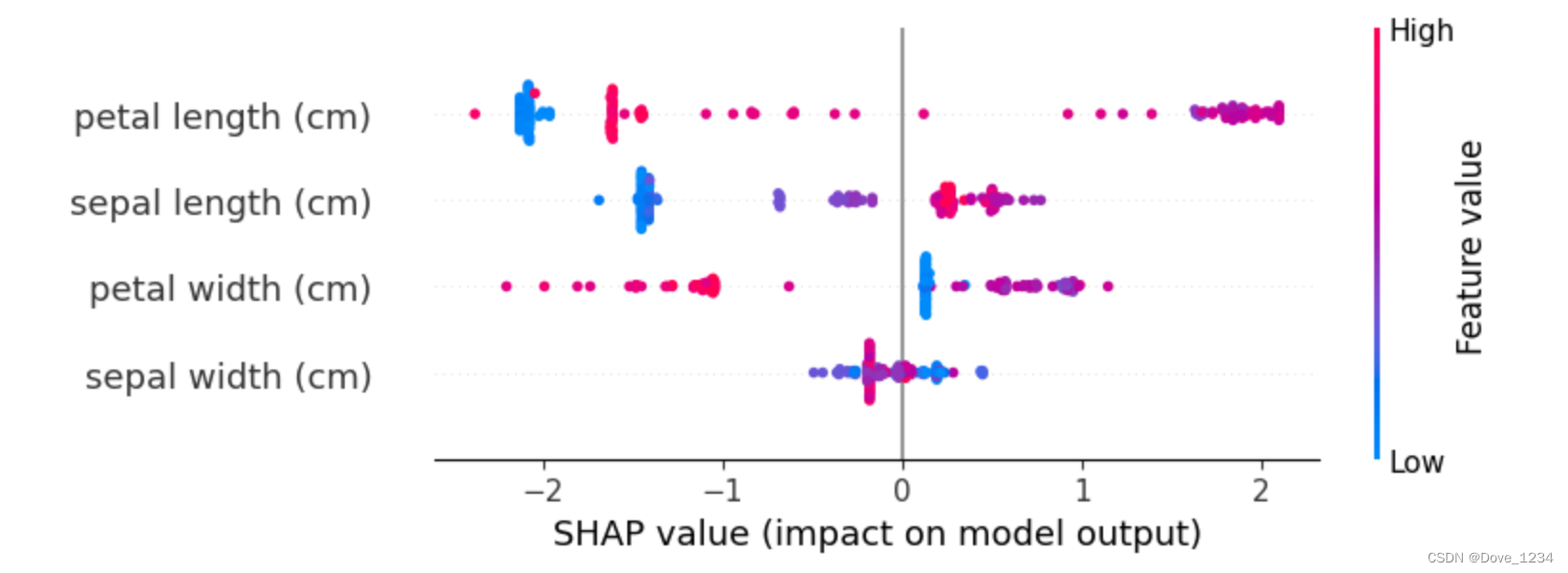
取值为1的情况。每一行代表一个特征,横坐标为SHAP值。一个点代表一个样本,颜色表示特征值(红色高,蓝色低)。
- 每个点是一个样本(人),图片中包含所有样本
- X轴:样本按Shap值排序-
- Y轴:特征按Shap值排序
- 颜色:特征的数值越大,越红
shap.dependence_plot('sepal length (cm)', shap_values[1], df, interaction_index="petal length (cm)")
#排除所有特征的影响,描述age和capital_gain的关系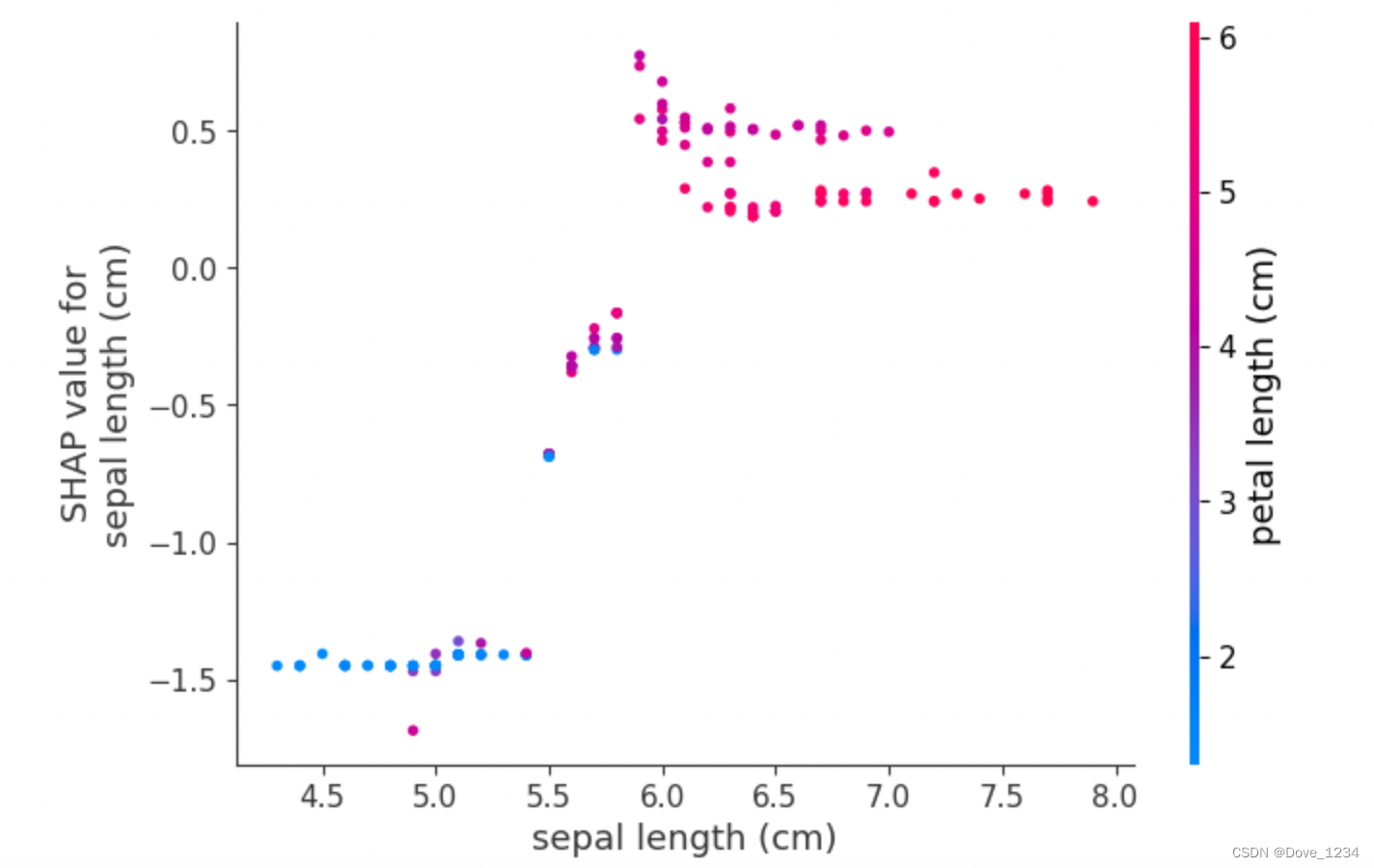
注:本文为转载内容,已对原文中无法跑通代码进行修改。
原文链接:
可解释性机器学习_Feature Importance、Permutation Importance、SHAP_LMY的博客的博客-CSDN博客_feature importance
















 9541
9541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









