







参考:
Brown 数据集和评价指标
https://blog.csdn.net/honyniu/article/details/87923274
Liberty_NotreDame_Yosemite数据集
https://blog.csdn.net/u013247002/article/details/82182404
torch官方python数据载入文件:
https://github.com/pytorch/vision/blob/master/torchvision/datasets/phototour.py
还有当时自己写的博客,但是当时不太理解:
项目解析-affnet项目
https://blog.csdn.net/baidu_40840693/article/details/103235793
numpy显示opencv匹配点-affnet项目
https://blog.csdn.net/baidu_40840693/article/details/103129607
数据集下载地址:
http://phototour.cs.washington.edu/patches/default.htm
http://matthewalunbrown.com/patchdata/patchdata.html

有的是通过Dog计算的patch,有的是通过Harris计算的patch

Each dataset consists of a series of corresponding patches, which are obtained by projecting 3D points from Photo Tourism reconstructions back into the original images.
这些patches是通过将Photo Tourism重建中的3D点投影回原始图像而获得的.
该数据集评价指标FPR95(看完后面的再来看这个)
def ErrorRateAt95Recall(labels, scores): recall_point = 0.95 # Sort label-score tuples by the score in descending order. temp = zip(labels, scores) #operator.itemgetter(1)按照第二个元素的次序对元组进行排序,reverse=True是逆序,即按照从大到小的顺序排列 #sorted_scores.sort(key=operator.itemgetter(1), reverse=True) sorted_scores = sorted(temp, key=operator.itemgetter(1), reverse=True) # Compute error rate # n_match表示测试集正样本数目 n_match = sum(1 for x in sorted_scores if x[0] == 1) n_thresh = recall_point * n_match tp = 0 count = 0 for label, score in sorted_scores: count += 1 if label == 1: tp += 1 if tp >= n_thresh: break return float(count - tp) / count
指标:FPR95—— 95% 的匹配关系都正确的情况下,其中非匹配关系错误的比例。
对求出来每组patch对之间的距离从小到大排序,选取95%的匹配关系都包含在内的值作为匹配与非匹配的阈值,这阈值内的数据中会有错误的匹配对(FP),阈值外会有正确的匹配对(TN),最终的FPR=FP/(FP+TN)

扯一点远的,关于怎么通过特征点导出patch,参考:
https://github.com/ducha-aiki/extract-patches-old
https://github.com/ducha-aiki/extract_patches
边缘缺失部分通过复制邻近像素补全,没有黑边效应
def extract_patches(kpts, img, PS=32, mag_factor = 10.0, input_format = 'cv2'):
"""
Extracts patches given the keypoints in the one of the following formats:
- cv2: list of cv2 keypoints
- cv2+A: tuple of (list of cv2 keypoints, Nx2x2 np array)
- ellipse: Nx5 np array, single row is [x y a b c]
- xyA: Nx6 np array, single row is [x y a11 a12 a21 a22]
- LAF: Nx2x3 np array, single row is [a11 a12 x; a21 a22 y]
Returns list of patches.
Upgraded version of
mag_factor is a scale coefficient. Use 10 for extracting OpenCV SIFT patches,
1.0 for OpenCV ORB patches, etc
PS is the output patch size in pixels
"""
if input_format == 'cv2':
Ms, pyr_idxs = convert_cv2_keypoints(kpts, PS, mag_factor)
elif input_format == 'cv2+A':
Ms, pyr_idxs = convert_cv2_plus_A_keypoints(kpts[0], kpts[1], PS, mag_factor)
elif (input_format == 'ellipse') or (input_format == 'xyabc'):
assert kpts.shape[1] == 5
Ms, pyr_idxs = convert_ellipse_keypoints(kpts, PS, mag_factor)
elif input_format == 'xyA':
assert kpts.shape[1] == 6
Ms, pyr_idxs = convert_xyA(kpts, PS, mag_factor)
elif input_format == 'LAF':
assert len(kpts.shape) == 3
assert len(kpts.shape[2]) == 3
assert len(kpts.shape[1]) == 2
Ms, pyr_idxs = convert_LAFs(kpts, PS, mag_factor)
else:
raise ValueError('Unknown input format',input_format)
return extract_patches_Ms(Ms, img, pyr_idxs, PS)
def extract_patches_Ms(Ms, img, pyr_idxs = [], PS=32):
"""
Builds image pyramid and rectifies patches around keypoints
in the tranformation matrix format
from the appropriate level of image pyramid,
removing high freq artifacts. Border mode is set to "replicate",
so the boundary patches don`t have crazy black borders
Returns list of patches.
Upgraded version of
https://github.com/vbalnt/tfeat/blob/master/tfeat_utils.py
"""
assert len(Ms) == len(pyr_idxs)
import cv2
import math
img_pyr = build_image_pyramid(img, PS/2.0)
patches = []
for i, M in enumerate(Ms):
patch = cv2.warpAffine(img_pyr[pyr_idxs[i]], M, (PS, PS),
flags=cv2.WARP_INVERSE_MAP + \
cv2.INTER_LINEAR + cv2.WARP_FILL_OUTLIERS, borderMode=cv2.BORDER_REPLICATE)
patches.append(patch)
return patches
def convert_cv2_keypoints(kps, PS, mag_factor):
"""
Converts OpenCV keypoints into transformation matrix
and pyramid index to extract from for the patch extraction
"""
Ms = []
pyr_idxs = []
for i, kp in enumerate(kps):
x,y = kp.pt
s = kp.size
a = kp.angle
s = mag_factor * s / PS
pyr_idx = int(math.log(s,2))
d_factor = float(math.pow(2.,pyr_idx))
s_pyr = s / d_factor
cos = math.cos(a * math.pi / 180.0)
sin = math.sin(a * math.pi / 180.0)
M = np.matrix([
[+s_pyr * cos, -s_pyr * sin, (-s_pyr * cos + s_pyr * sin) * PS / 2.0 + x/d_factor],
[+s_pyr * sin, +s_pyr * cos, (-s_pyr * sin - s_pyr * cos) * PS / 2.0 + y/d_factor]])
Ms.append(M)
pyr_idxs.append(pyr_idx)
return Ms, pyr_idxsfrom extract_patches import extract_patches
show_idx = 300
PATCH_SIZE = 65
mrSize = 5.0
t=time()
patches = extract_patches(kps1, img1, PATCH_SIZE, mrSize, 'cv2')
print ('pyr OpenCV version for 500 kps, [s]', time()-t)
print (kps1[0])
fig = plt.figure(figsize=(12, 16))
fig.add_subplot(1, 3, 1)
plt.imshow(patches[show_idx])
继续扯回来
解压yosemite
有1024*1024的bmp文件, 每个bmp文件由16*16个子图像构成,每个子图像的大小是64*64像素,提取顺序是从左到右,从上到下
比如该数据集从patches0000.bmp--patches2474.bmp,有2475*16*16=633600个子图像, 但是最后一张图少了13个子图像,那就是633587
info.txt 有633587行,每行有两列,第二列暂时没有使用不用管,第一列表示的意思是, 该子图像是三维点云中的某个3D点(3D point ID)的2D投影图像
从下面文件可知,1-2这两个子图像是同一个3D点(ID=0)的不同2D图像上的投影,3-6这四个子图像是同一个3D点(ID=1)的不同2D图像上的投影,
interest.txt 有633587行,包含了兴趣点(也可理解为特征点)的信息,每一行对应一个patch
有5列数据,分别代表: image_ID(该patch来自哪个2D 图像),x(2D 图像),y(2D 图像), orientation, scale (log2 units)
为了确保 (匹配 不匹配) 这两个评价标准足够的不同,所以不匹配时候,两个patch的这些值应该差距足够大or足够小
sim.txt 有633587行 暂时不知道是什么
m50_1000_1000_0.txt
m50_2000_2000_0.txt
m50_5000_5000_0.txt
....
m50_100000_100000_0.txt
m50_200000_200000_0.txt
m50_500000_500000_0.txt
文件m50_n1_n2_0.txt的n1和n2分别表示match和non-match的数量(但实际行数目只有比如1000,就是1000行,这1000行有匹配对,有不匹配对),文件中每一行数据含义为:
patch_ID1,3D_point_ID1,unused1,patch_ID2,3D_point_ID2,unused2
官方原文是:
"matches" have the same 3DpointID, and correspond to interest points that were detected with 5 pixels in position, and agreeing to 0.25 octaves of scale and pi/8 radians in angle. "non-matches" have different 3DpointID's, and correspond to interest points lying outside a range of 10 pixels in position, 0.5 octaves of scale and pi/4 radians in angle.
大致意思是:
匹配的patch对,他们的(3D point ID)相同,且xy应该相距 < 5个像素, 且 orientation(angle)相差不要超过pi/8弧度值, scale(octaves)相差不要超过0.25
不匹配的patch对,他们的(3D point ID)不相同,且xy应该相距 > 10个像素, 且 orientation(angle)相差大于pi/4弧度值, scale(octaves)相差大于0.5
m50_1000_1000_0.txt 有1000行
有匹配的有不匹配的.我们找出两个:
第一个不匹配,第二个匹配
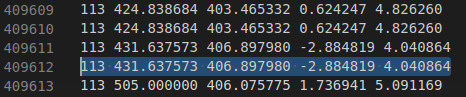
467111 175415 0 563000 210688 0 0
409610 154642 0 409611 154642 0 0interest.txt :
第467111个patch vscode从1开始,467111是下表从0开始的数,所以vscode取467112
第563000个patch
第409610个patch
第409611个patch

对于训练中具体怎么使用:
def read_image_file(data_dir: str, image_ext: str, n: int) -> torch.Tensor: """Return a Tensor containing the patches """ def PIL2array(_img: Image.Image) -> np.ndarray: """Convert PIL image type to numpy 2D array """ return np.array(_img.getdata(), dtype=np.uint8).reshape(64, 64) def find_files(_data_dir: str, _image_ext: str) -> List[str]: """Return a list with the file names of the images containing the patches """ files = [] # find those files with the specified extension for file_dir in os.listdir(_data_dir): if file_dir.endswith(_image_ext): files.append(os.path.join(_data_dir, file_dir)) return sorted(files) # sort files in ascend order to keep relations patches = [] list_files = find_files(data_dir, image_ext) for fpath in list_files: img = Image.open(fpath) for y in range(0, 1024, 64): for x in range(0, 1024, 64): patch = img.crop((x, y, x + 64, y + 64)) patches.append(PIL2array(patch)) return torch.ByteTensor(np.array(patches[:n]))read_matches_files也验证了
patch_ID1,3D_point_ID1,unused1,patch_ID2,3D_point_ID2,unused2
匹配的patch对,他们的(3D point ID)相同
不匹配的patch对,他们的(3D point ID)不相同
def read_matches_files(data_dir: str, matches_file: str) -> torch.Tensor: """Return a Tensor containing the ground truth matches Read the file and keep only 3D point ID. Matches are represented with a 1, non matches with a 0. """ matches = [] with open(os.path.join(data_dir, matches_file), 'r') as f: for line in f: line_split = line.split() matches.append([int(line_split[0]), int(line_split[3]), int(line_split[1] == line_split[4])]) return torch.LongTensor(matches)def __getitem__(self, index: int) -> Union[torch.Tensor, Tuple[Any, Any, torch.Tensor]]: """ Args: index (int): Index Returns: tuple: (data1, data2, matches) """ if self.train: data = self.data[index] if self.transform is not None: data = self.transform(data) return data m = self.matches[index] data1, data2 = self.data[m[0]], self.data[m[1]] if self.transform is not None: data1 = self.transform(data1) data2 = self.transform(data2) return data1, data2, m[2]题外话-------点云的来源:
http://phototour.cs.washington.edu/











后记----------------当然除了上述使用方式,
还有在度量学习中的使用方式,最新的论文tfnet hardnet都使用该方式:
关于度量学习参考如下文章:
https://zhuanlan.zhihu.com/p/72516633
https://www.cnblogs.com/luckforefforts/p/13642695.html
PhotoTour数据集修改一下官方代码,可以使用triplets三元组的数据输入方式
https://github.com/vbalnt/tfeat/blob/master/phototour.py
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (data1, data2, matches)
"""
# fix the random seed issue with numpy and multiprocessing
#seed = random.randrange(4294967295)
#np.random.seed(seed=seed)
# testing mode: 100k pairs from Brown's original paper
# note: testing mode can only be pairs
if not self.train:
m = self.matches[index]
data1, data2 = self.data[m[0]], self.data[m[1]]
patches = [data1, data2]
patches = [p.numpy() for p in patches]
data1,data2 = resize_patches(patches,32)
# data1, data2 = norm_patches(patches)
return data1, data2, m[2]
# train mode: either random pairs or random triplets
if self.train:
if self.mode == 'pairs':
lbl = random.randint(0, 1)
if lbl==0: #negative pair
idx_L = random.randrange(self.data_len)
L_label = self.labels[idx_L]
idx_R = random.randrange(self.data_len)
R_label = self.labels[idx_R]
while R_label==L_label :
idx_R = random.randrange(self.data_len)
R_label = self.labels[
idx_R]
else: #positive pair
idx_L = random.randrange(self.data_len)
L_label = self.labels[idx_L]
label_search_range_start = max(0,idx_L-20)
label_search_range_end = min(self.data_len,idx_L+20)
sub_labels = self.labels[label_search_range_start:label_search_range_end]
mask_pos = np.where(sub_labels==L_label)[0]
idx_L,idx_R = np.random.choice(mask_pos,2, replace=False)
idx_L = idx_L + label_search_range_start
idx_R = idx_R + label_search_range_start
data1, data2 = self.data[idx_L], self.data[idx_R]
patches = [data1,data2]
patches = [p.numpy() for p in patches]
[data1,data2] = resize_patches(patches,32)
return data1,data2,lbl
elif self.mode == 'triplets':
idx_a = random.randrange(self.data_len)
a_label = self.labels[idx_a]
idx_n = random.randrange(self.data_len)
n_label = self.labels[idx_n]
while n_label==a_label :
idx_n = random.randrange(self.data_len)
n_label = self.labels[idx_n]
#find the next idx_p
label_search_range_start = max(0,idx_a-20)
label_search_range_end = min(self.data_len,idx_a+20)
sub_labels = self.labels[label_search_range_start:label_search_range_end]
mask_pos = np.where(sub_labels==a_label)[0]
idx_a,idx_p = np.random.choice(mask_pos,2, replace=False)
idx_a = idx_a + label_search_range_start
idx_p = idx_p + label_search_range_start
data_a, data_p, data_n = self.data[idx_a], self.data[idx_p], self.data[idx_n]
patches = [data_a, data_p, data_n]
patches = [p.numpy() for p in patches]
if self.augment:
patches = augment_patches(patches)
patches = resize_patches(patches,32)
# patches = norm_patches(patches)
return patches
else:
raise ValueError('Uknown training output mode. Valid ones are pairs,triplets')还有hardnet中实现的TripletPhotoTour:
https://github.com/DagnyT/hardnet/blob/master/code/HardNetMultipleDatasets.py
affnet中的实现:
https://github.com/ducha-aiki/affnet/blob/master/dataset.py
Learning Local Descriptors with a CDF-Based Dynamic Soft Margin中的实现:
https://github.com/lg-zhang/dynamic-soft-margin-pytorch/tree/master/datasets
https://gfx.cs.princeton.edu/pubs/Zhang_2019_LLD/softmargin.pdf
还有一些实现:
https://github.com/ducha-aiki/HardNet_MultiDataset
还有其他实现:一个已经写好的评估代码:
一个非常好的研究特征匹配的博客:
https://ducha-aiki.github.io/wide-baseline-stereo-blog/
他一般使用我们之前了解的可微分opencv库https://github.com/kornia/kornia
可微分的「OpenCV」:这是基于PyTorch的可微计算机视觉库Kornia
https://blog.csdn.net/baidu_40840693/article/details/103921378
https://ducha-aiki.github.io/wide-baseline-stereo-blog/2020/09/23/local-descriptors-validation.html
https://github.com/ducha-aiki/brown_phototour_revisited
https://github.com/ducha-aiki/brown-revisited

当然我们说的另外一个数据集HPatches也可以使用这样的方式:
https://github.com/vbalnt/tfeat/blob/master/hpatches.py
https://github.com/DagnyT/hardnet/blob/master/code/HardNetHPatchesSplits.py
顺便通过https://github.com/ducha-aiki发现了一个特征检测器评估的框架:
https://github.com/lenck/vlb-deteval


还有一个新的仿射评估数据集:















 1120
1120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









