







 超级会员免费看
超级会员免费看
引言:文献【1】中第88页,给出了最大熵模型的一般形式(其中的f为特征函数,后面我们还会讲到):
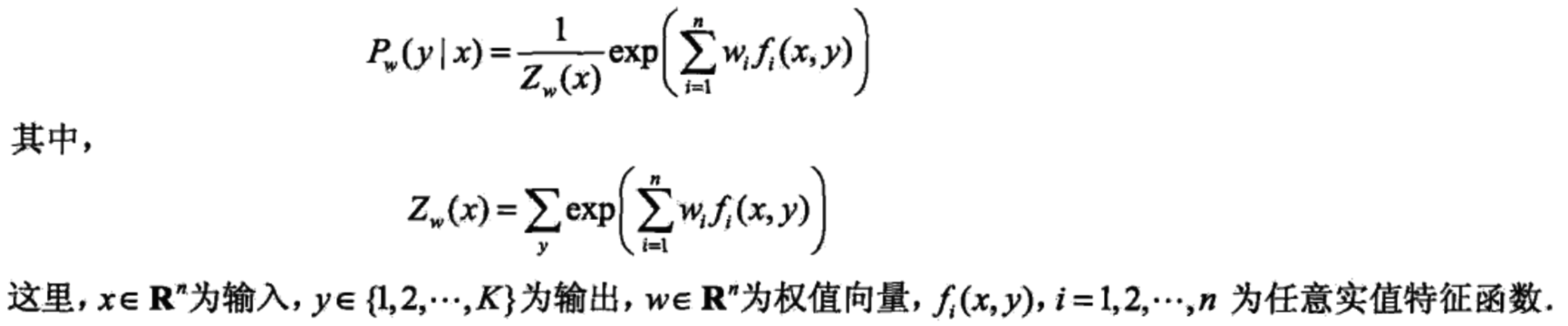
而文献【5】中我们从另外一种不同的角度也得出了多元逻辑回归的一般形式:
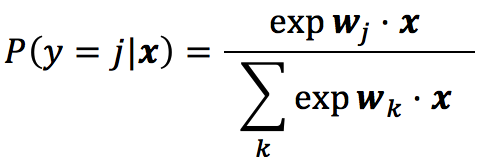
可见,尽管采用的方法不同,二者最终是殊途同归、万法归宗了。 所以我们说无论是多元逻辑回归,还是最大熵模型,又或者是Softmax,它们本质上都是统一的。本文就将从最大熵原理这个角度来推导上述最大熵模型的一般形式。
引言:文献【1】中第88页,给出了最大熵模型的一般形式(其中的f为特征函数,后面我们还会讲到):
而文献【5】中我们从另外一种不同的角度也得出了多元逻辑回归的一般形式:
可见,尽管采用的方法不同,二者最终是殊途同归、万法归宗了。 所以我们说无论是多元逻辑回归,还是最大熵模型,又或者是Softmax,它们本质上都是统一的。本文就将从最大熵原理这个角度来推导上述最大熵模型的一般形式。
 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文
























