







目标检测demo,方法YOLOv5流程
1.找目标检测的项目代码
从github上面找个简单yolov5项目,或者从kaggle上面找一个相关代码。推荐使用kaggle它上面是用类似于jupyter页面的样式,可以看到一步一步具体的实现步骤。
1.1 下载yolov5代码
- 可以用如下代码下载yolov5的代码,并下载对应包的版本环境。
!git clone https://github.com/ultralytics/yolov5
%cd ./yolov5
!pip install -r requirements.txt
1.2 如果在服务器中下载报错。
(clone报错fatal: unable to access ‘https://github.com/…’: Failed to connect to github.com port 443 after 21096 ms: Couldn’t connect to server)

-
原因是本机代理端口和git端口不一致。
解决方法:
第一步、找到本机代理端口号(红框部分)
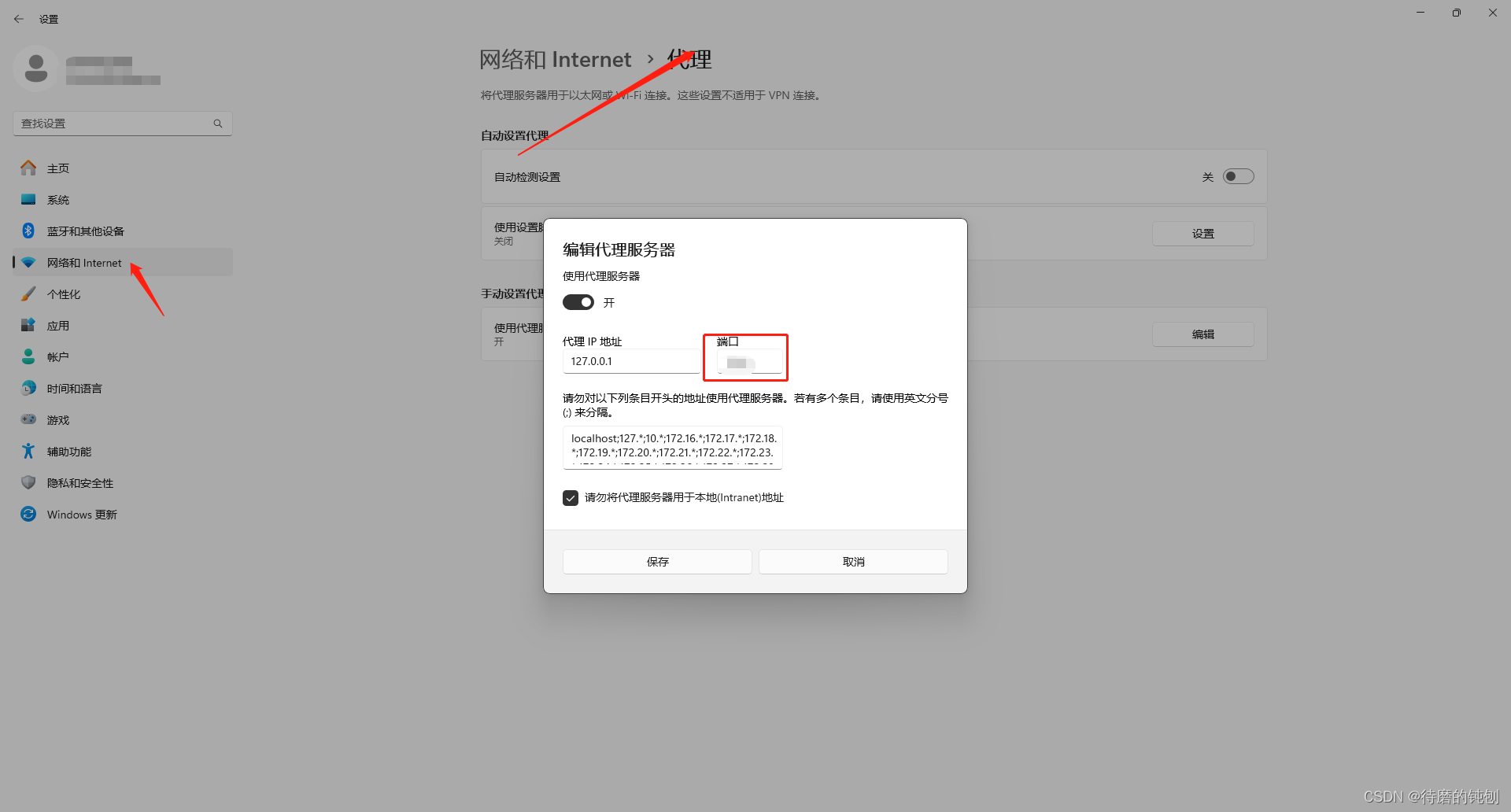
第二步、修改git端口号
在git-bash执行如下两条指令
git config --global http.proxy http://127.0.0.1:红框端口号
git config --global https.proxy http://127.0.0.1:红框端口号
解决问题!
- 服务器上代理端口和git端口不一致的话,暂未找到方法。
可以通过clone在本地然后用传输命令传在服务器上。
#下载文件命令
scp -r username(服务器名字)@ip(服务器ip):/home/DataManagement/Dataset/data.zip(文件的位置) ./(复制的位置)
#上传文件命令
scp -r ./要上传的文件 username(服务器名字)@ip(服务器ip):/home/DataManagement/Dataset/(要传的位置)
1.1 查看GPU能否用
查看自己的GPU能不能用。
import torch
from IPython.display import Image
print('torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
2.yolov5数据集处理划分
整理好需要的数据集。我的数据集是一个1600张图像的一个目标的检测。
- 我的数据集结构:
train: ./datasets//images
train: ./datasets//labels
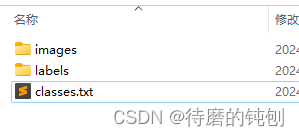
- yolov5需要的数据结构。
train: ./datasets/train/images
val: ./datasets/valid/images
test:./datasets/test/images
方法一:直接导入用sklearn的train_test_split库进行数据集划分。
# 数据集根目录
dataset_root =r'E:\demo\yolov5_demo\datasets'
# 获取所有图像文件的路径
image_files = [os.path.join(dataset_root, 'images', filename) for filename in os.listdir(os.path.join(dataset_root, 'images'))]
# 获取所有标签文件的路径
label_files = [os.path.join(dataset_root, 'labels', filename) for filename in os.listdir(os.path.join(dataset_root, 'labels'))]
# 划分数据集
image_train, image_temp, label_train, label_temp = train_test_split(image_files, label_files, test_size=0.4, random_state=42)
image_val, image_test, label_val, label_test = train_test_split(image_temp, label_temp, test_size=0.5, random_state=42)
# 打印划分后的数据集大小
print(f"Training set size: {len(image_train)}")
print(f"Validation set size: {len(image_val)}")
print(f"Testing set size: {len(image_test)}")
方法二:split.py完整代码
import os
import shutil
import random
random.seed(0) # 确保随机操作的可复现性
def split_data(file_path, xml_path, new_file_path, train_rate, val_rate, test_rate):
# 存储图片和标注文件的列表
each_class_image = []
each_class_label = []
# 将图片文件名添加到列表
for image in os.listdir(file_path):
each_class_image.append(image)
# 将标注文件名添加到列表
for label in os.listdir(xml_path):
each_class_label.append(label)
# 将图片和标注文件打包成元组列表并随机打乱
data = list(zip(each_class_image, each_class_label))
total = len(each_class_image)
random.shuffle(data)
# 解压元组列表,回到图片和标注文件列表
each_class_image, each_class_label = zip(*data)
# 按照指定的比例分配数据到训练集、验证集和测试集
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
# 定义复制文件到新路径的操作
def copy_files(files, old_path, new_path1):
# 遍历列表中的每一个文件名
for file in files:
# 打印当前处理的文件名,这只是为了在处理过程中输出信息,便于跟踪进度
print(file)
# 使用os.path.join连接旧路径和新文件名,形成完整的旧文件路径
old_file_path = os.path.join(old_path, file)
# 检查新的路径是否存在,如果不存在则创建新的路径,这可以确保复制操作不会因为路径不存在而出错
if not os.path.exists(new_path1):
os.makedirs(new_path1)
# 使用os.path.join连接新路径和新文件名,形成完整的新文件路径
new_file_path = os.path.join(new_path1, file)
# 使用shutil模块的copy函数复制旧文件到新路径,生成与旧文件相同的新的文件
shutil.copy(old_file_path, new_file_path)
# 复制训练、验证和测试的图片和标注文件到指定目录
copy_files(train_images, file_path, os.path.join(new_file_path, 'train', 'images'))
copy_files(train_labels, xml_path, os.path.join(new_file_path, 'train', 'labels'))
copy_files(val_images, file_path, os.path.join(new_file_path, 'val', 'images'))
copy_files(val_labels, xml_path, os.path.join(new_file_path, 'val', 'labels'))
copy_files(test_images, file_path, os.path.join(new_file_path, 'test', 'images'))
copy_files(test_labels, xml_path, os.path.join(new_file_path, 'test', 'labels'))
# 判断当前脚本是否为主程序入口,即直接运行该脚本
if __name__ == '__main__':
# 定义文件路径变量,指向数据集的图像文件所在路径
file_path = "D:\yolov5demo\datasets\image"
# 定义xml路径变量,指向数据集的标注文件所在路径
xml_path = "D:\yolov5demo\datasets\labels"
# 定义新文件路径变量,指向输出结果文件的新路径
new_file_path = "D:\yolov5demo\datasets\ImageSets"
# 调用split_data函数,分割数据集,并将结果分别存储到指定的路径中
split_data(file_path, xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)

3 在服务器中训练模型
3.1登录服务器
- 确认服务器地址
在登录服务器之前,需要确认服务器的地址或IP地址。通常,服务器管理员会提供给用户一个服务器地址,用户需要将该地址输入到登录界面的相应位置。
- 打开终端或命令提示符
在电脑上登录服务器,通常需要打开终端(Mac或Linux系统)或命令提示符(Windows系统)。这些工具提供了用户与服务器进行交互的界面。
- 输入登录命令
一旦打开了终端或命令提示符,用户需要输入登录命令来连接到服务器。根据不同的操作系统,登录命令可能会有所不同。p
例如,对于基于UNIX或类UNIX系统的服务器(如Linux、Mac),常用的登录命令为:
ssh username@server_addressp
其中,username是用户在服务器上的用户名,server_address是服务器的地址。
对于Windows系统,可以使用SSH客户端软件(如PuTTY)来实现登录。用户需要输入服务器地址和端口号,并使用用户名和密码进行身份验证。一旦输入了登录命令并按下回车键,系统就会开始尝试连接到服务器。
- 输入密码
如果连接成功,系统将提示用户输入密码。用户需要输入正确的密码来完成身份验证。在输入密码时,密码不会显示在屏幕上,这是为了确保安全。有些服务器可能还要求用户使用其他身份验证方法,如密钥对。用户需要提供有效的密钥来完成身份验证。
- 连接服务器
一旦成功输入了正确的密码或密钥,系统将连接到服务器。此时,用户就可以开始操作服务器上的资源了。通过服务器登录,用户可以执行各种操作,如上传和下载文件、运行应用程序、查看和修改配置文件等。在完成操作后,用户可以通过退出命令来断开与服务器的连接。参考
3.2使用jupyter notebook

这张图是copy的原地址
用下面这行命令启动jupyter。当然也可以直接在服务器里面运行代码。
jupyter-notebook --ip 0.0.0.0 --port 9630 --allow-root --no-browser
3.3 训练模型
python train.py --img 640 --batch 16 --epochs 5 --data data.yaml --weights yolov5s.pt --workers 0


这里注意data.yaml文件里的路径最好写绝对路径,不然容易报错。
训练五轮的结果。

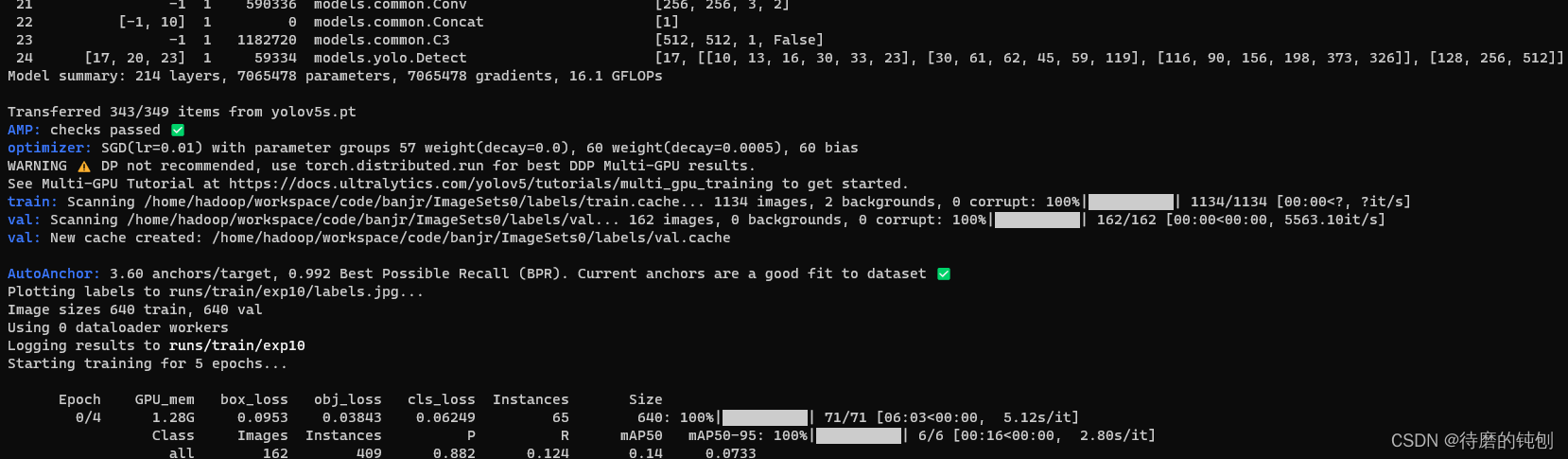
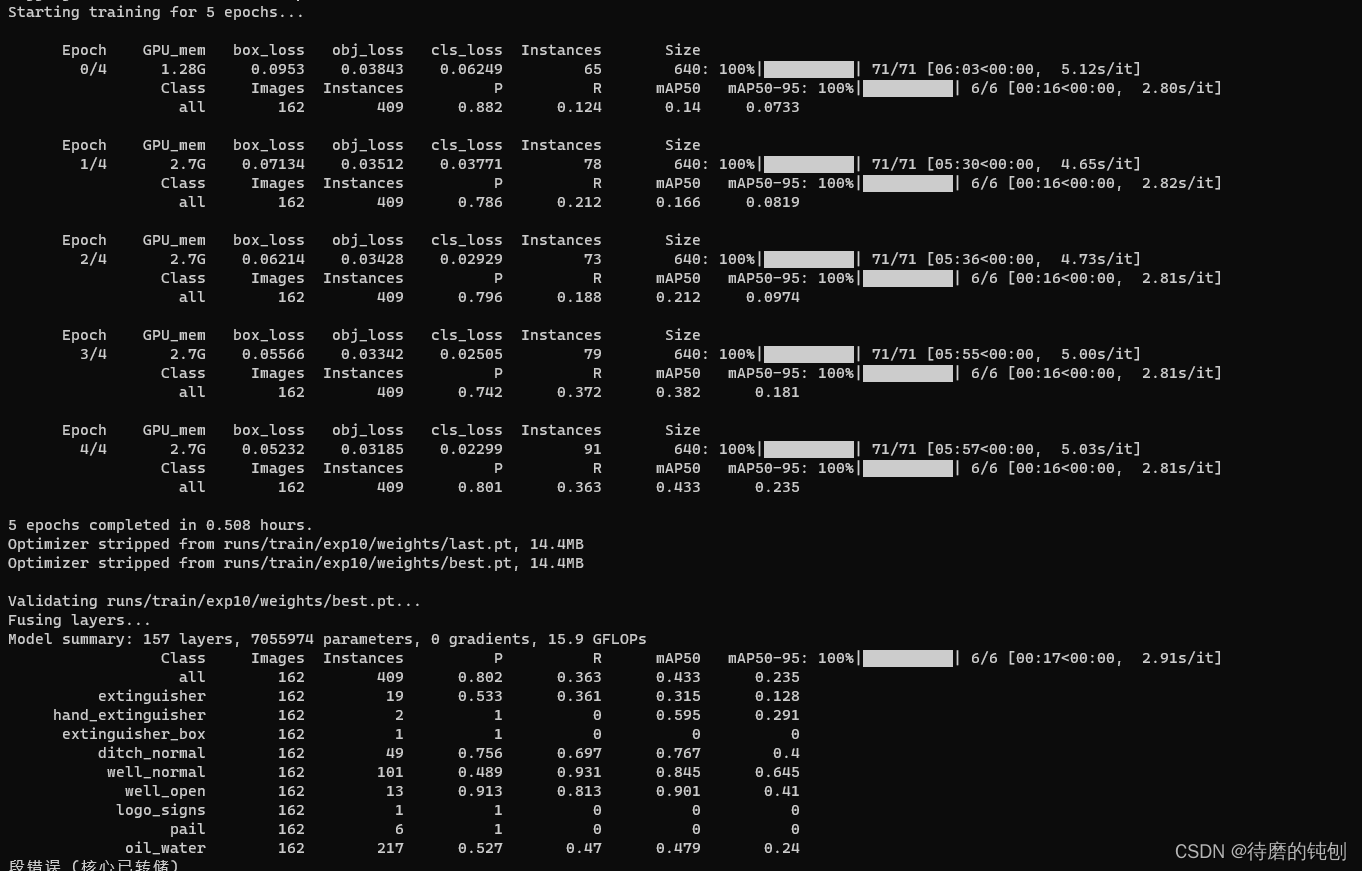
总是报错“段错误(核心已转储)”—因为显存不够。
训练100轮。
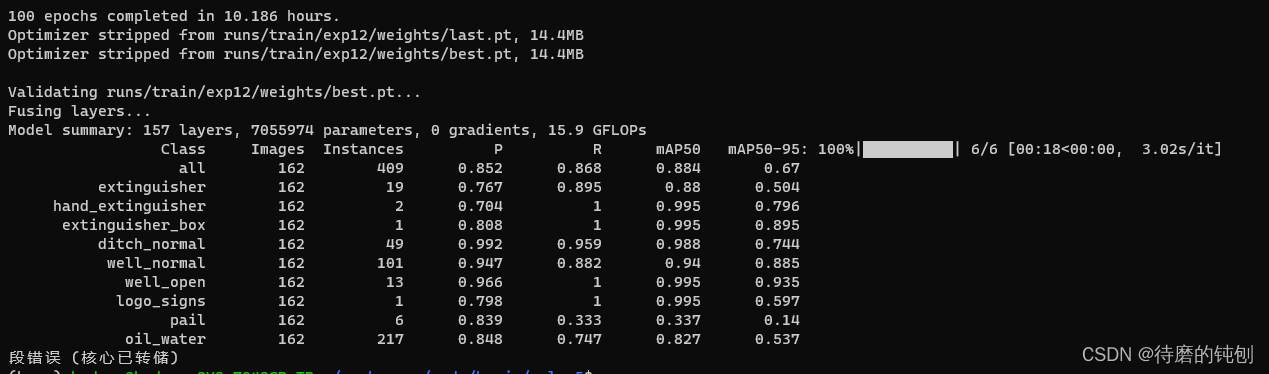
使用 --device 0,1,2,3可以确定使用那个GPU来训练。
python train.py --img 640 --batch 16 --epochs 5 --data ../data.yaml --weights yolov5s.pt --workers 0 --device 0,1,2,3
自测:

















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









