






文章目录
1.公开数据集
摘要
白内障手术是眼科领域最常进行的显微手术之一。这种手术背后的目标是用人造晶状体代替人眼晶状体,这是由于衰老而经常需要的干预。整个手术是在显微镜下进行的,但共同安装的摄像机可以记录和存档手术过程。目前,录制的视频以术后方式用于记录和培训。录制白内障视频的另一个好处是,它们能够进行视频分析(即手动和/或自动视频内容分析),以调查与医学相关的研究问题(例如,并发症的原因)。然而,这需要一个医疗多媒体信息系统,该系统根据现有数据进行训练和评估,而这些数据目前尚未公开。在这项工作中,我们提供了一个公共视频数据集,其中包含 101 例白内障手术,这些手术由四位不同的外科医生在 9 个月内进行。这些外科医生分为中等经验和经验丰富的外科医生(助理医生与高级医生),为基于经验的视频分析提供了基础。所有视频均由高级眼科医生用准标准化操作阶段进行注释。
1.1.白内障-101:数据集文件结构
1.1.1.视频文件
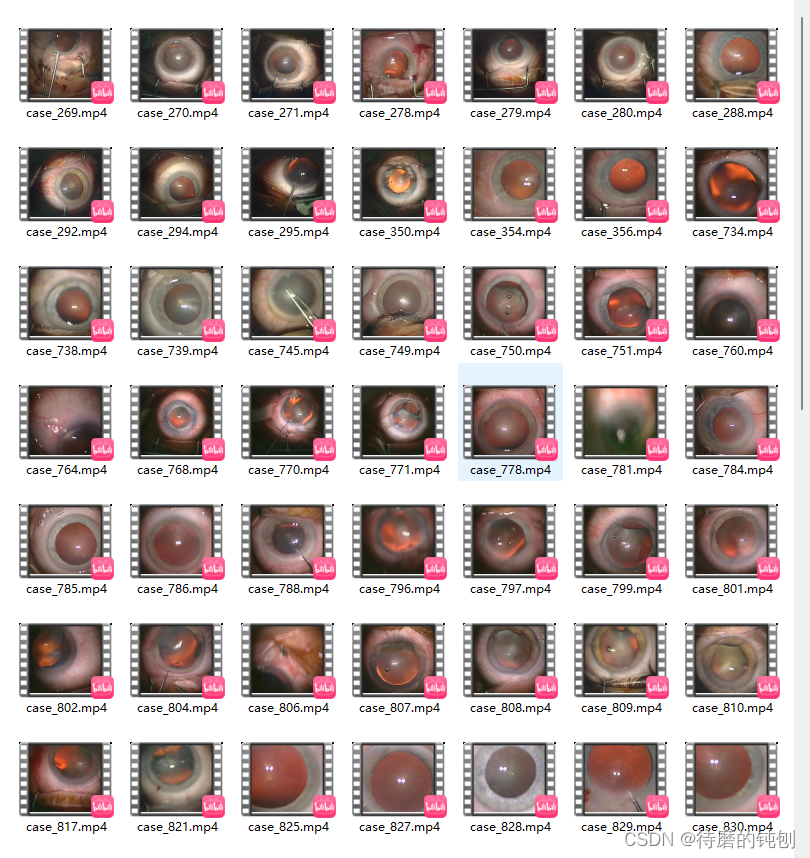
视频文件存储在 videos 子目录中,文件名遵循以下模式:
case_videoID.mp4
例如,视频 269 的文件名为 case_269.mp4。
视频文件使用 H.264/AVC 编解码器编码,帧率为 25 帧每秒,分辨率为 720x540 像素。提供的视频的平均持续时间约为 12500 帧(8.3 分钟)。
1.1.2.注释文件
注释以三个以分号分隔的值文件提供,每个文件都包含描述字段的标题行。
(1)videos.csv
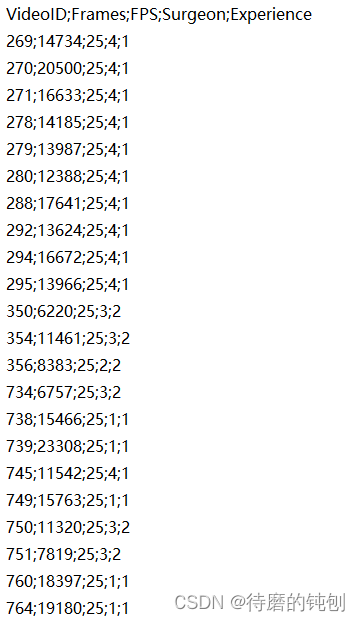
包含有关整个视频文件的元数据,包括所有整数字段:
- 视频 ID
- 视频帧数
- 帧率(25)
- 手术医生 ID(1-4)
- 手术医生的经验水平(1 = 低,2 = 高)
下表显示了每位手术医生的视频分布以及每个经验水平的视频数量。
| 手术医生 ID | 视频 |
|---|---|
| 1 | 25 |
| 2 | 24 |
| 3 | 32 |
| 4 | 20 |
| 经验水平 | 视频 |
|---|---|
| 1(低) | 45 |
| 2(高) | 56 |
(2) phases.csv

描述白内障手术的十个准标准操作阶段(更多信息请参阅上述引用的论文)。这两个字段是:
- 阶段 ID(1-10 的整数)
- 阶段名称(字符串)
(3)annotations.csv
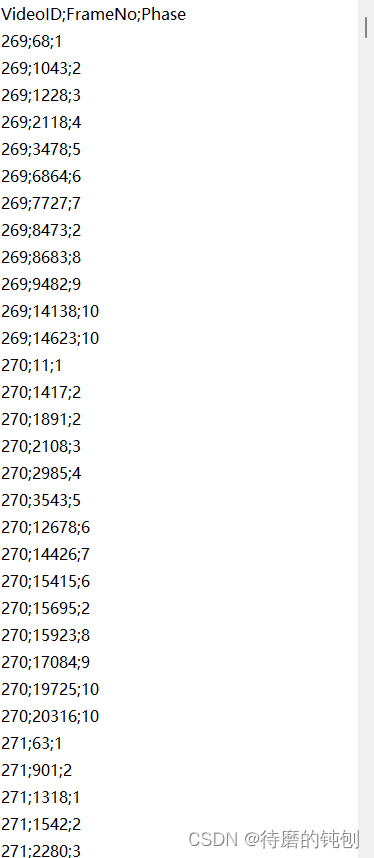
包含所有提供视频的操作阶段边界的专家注释。由于注释工具的使用,仅注释了操作阶段的起始点,手动选择时间点的准确性不超过 +/- 1 秒(+/- 25 帧)。尽管如此,注释以帧分辨率提供,以便使用该数据集进行基于帧的评估时进行比较。
CSV 文件的每一行(除了标题行)描述了一个操作阶段注释的起始点,具有以下所有整数字段:
- 视频 ID(与 videos.csv 中的 ID 匹配)
- 表示操作阶段起始点的帧编号(从零开始),该帧延伸到下一个注释或同一视频的结束
- 阶段 ID(与 phases.csv 中的 ID 匹配)
CSV 文件中的行按(视频 ID,帧编号)的词典顺序排序。
请注意所选择的注释过程的以下后果:
- 给定视频的第一个注释(第一个操作阶段的开始)之前的视频段实际上未被注释,即未分配给任何操作阶段。
- 给定视频的最后一个注释开始的视频段实际上延伸到视频的结束,尽管注释的操作阶段实际上可能会提前结束。然而,视频获取过程表明,手术末期的这段“超出阶段”的时间通常只有几秒钟。
- 同一视频中可能会连续出现相同操作阶段的注释,因为同一阶段可能会重复或分成也由医学专家注释的子阶段。事后已整合子阶段以符合 phases.csv 中描述的准标准阶段。
最后,请注意,phases.csv 中定义的操作阶段的线性顺序通常在手术中不严格遵循,主要有两个原因:
- 第2阶段(注入粘性剂)通常在每次白内障手术中发生两次,并且两个视频片段与相同的阶段 ID 进行了注释,因为从视觉角度通常无法区分它们。
- 手术医生(特别是经验较少的医生)有时可能不得不重复某些阶段或阶段序列。
1.2. 数据处理
1.2.1.抽帧脚本全部代码(每行都有注释)
-
对101例白内障手术的视频数据集视频进行处理,根据提供的标签CSV文件中的分类信息,从每个视频中抽取帧,并将这些帧按照YOLO分类任务的不同类别进行分类。每个类别将被放置在不同的文件夹中,并且每个帧的文件名将包含相关信息。
-
鉴于从视频中每秒抽取25帧会导致数据重复过多,并且产生的数据量超过一百万张图片,因此决定调整抽帧策略,每秒仅抽取2帧。这样既可以有效减少数据量,也有助于降低重复数据的比例。
-
抽帧结果示例:
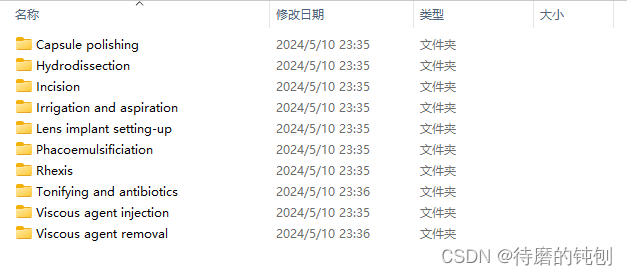
脚本名Script.py
import os
import cv2
import pandas as pd
# 设置 CSV 文件路径和视频文件目录
annotations_csv_path = 'annotations.csv' # 您的 CSV 文件路径
phases_csv_path = 'phases.csv' # phases.csv 文件路径
video_dir = 'videos' # 视频文件所在的目录
# 设置输出文件夹路径
output_dir = 'output_frames10'
# 如果输出文件夹不存在,创建它
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 读取 phases.csv 文件,创建阶段 ID 到含义的字典
phases_df = pd.read_csv(phases_csv_path, sep=';')
phases_dict = dict(zip(phases_df['Phase'], phases_df['Meaning']))
# 读取 annotations.csv 文件
df = pd.read_csv(annotations_csv_path, sep=';')
# 遍历 annotations.csv 文件中的每一行
for index, row in df.iterrows():
video_id = row['VideoID']
start_frame_no = row['FrameNo']
phase_id = row['Phase']
phase_meaning = phases_dict.get(phase_id, f'Phase_{phase_id}')
print(phase_meaning)
# 查找下一个阶段的帧编号
if index + 1 < len(df) and df.iloc[index + 1]['VideoID'] == video_id:
end_frame_no = df.iloc[index + 1]['FrameNo']
else:
# 如果没有下一个阶段,则将结束帧设置为视频的最后一帧
video_cap = cv2.VideoCapture(os.path.join(video_dir, f'case_{video_id}.mp4'))
end_frame_no = int(video_cap.get(cv2.CAP_PROP_FRAME_COUNT))
video_cap.release()
# 构建视频文件路径
video_file_path = os.path.join(video_dir, f'case_{video_id}.mp4')
# 检查视频文件是否存在
if not os.path.exists(video_file_path):
print(f'Video file not found: {video_file_path}')
continue
# 打开视频文件
video_cap = cv2.VideoCapture(video_file_path)
# 从起始帧到结束帧的范围读取帧
for current_frame_no in range(int(start_frame_no), int(end_frame_no),12):
# 设置视频的位置到指定的帧编号
video_cap.set(cv2.CAP_PROP_POS_FRAMES, current_frame_no)
# 读取帧
success, frame = video_cap.read()
# 如果读取成功
if success:
# 创建输出文件夹,按 phase_meaning 创建子目录
phase_folder = os.path.join(output_dir, phase_meaning)
# video_folder = os.path.join(phase_folder, f'video_{video_id}')
if not os.path.exists(phase_folder):
os.makedirs(phase_folder)
# 构建输出文件路径
output_file_path = os.path.join(phase_folder, f'case_{video_id}_frame_{current_frame_no}_phase_{phase_meaning}.jpg')
# 保存帧到输出文件
cv2.imwrite(output_file_path, frame)
print(f'Saved frame: {output_file_path}')
else:
print(f'Failed to read frame: {current_frame_no} from video: {video_file_path}')
# 关闭视频文件
video_cap.release()
print('Finished extracting frames.')
1.2.2.分类任务划分数据集脚本
脚本名:cla_split.py
import os
import random
import shutil
from shutil import copy2
def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.1, test_scale=0.1):
#读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_folder)
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print("{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
if __name__ == '__main__':
src_data_folder = "/home/hadoop/output_frames10/"
target_data_folder = "/home/hadoop/splitData_frames10/"
data_set_split(src_data_folder, target_data_folder)
划分结果示例:


2.yolov8分类任务训练
2.1.配环境
就不赘述了。

2.2.训练命令:
yolo classify train data="splitData_frames10" model=yolov8s-cls.pt epochs=100 device=0,1,2,3 batch = 128
开始训练
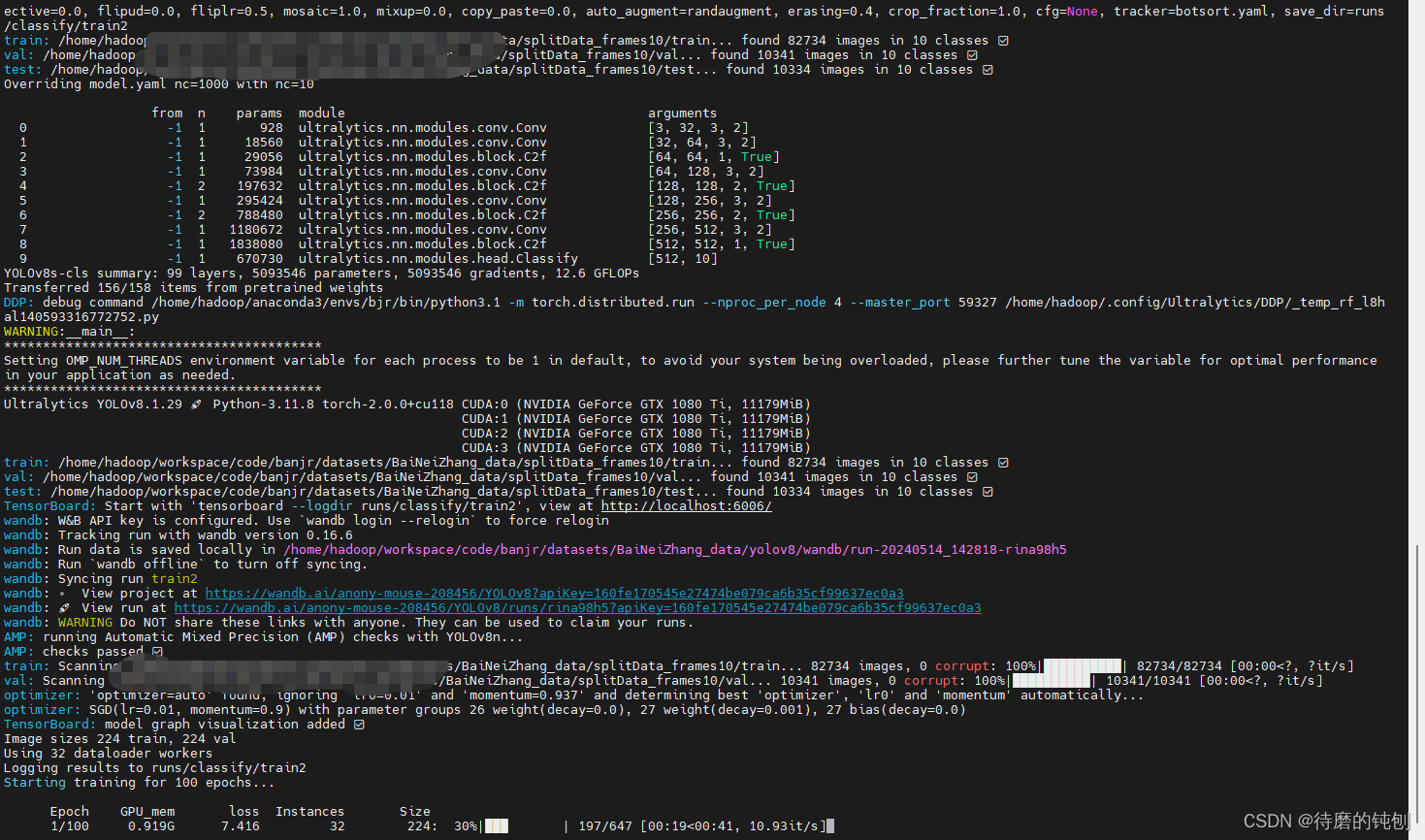
2.3.训练结果
示例图:
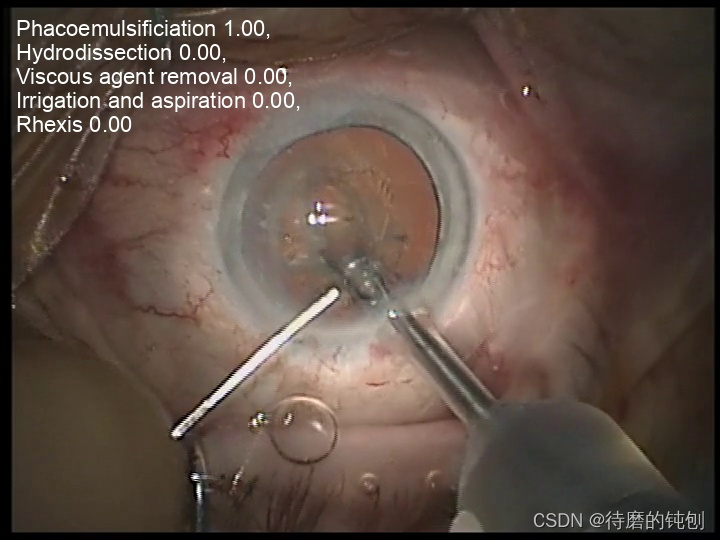
推理示例图:


















 2613
2613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









