






1.Why ML Strategy?
当我们要优化一个模型的时候,我们可以通过许多种方法:

而如何选择的方法也是多种多样,有一个快速,有效选择的策略对于我们而言非常重要.
2.Orthogonalization
正交化
调节电视图像的时候,要使电视图像到正立中间,我们可以对于图像的水平方向,垂直方向,旋转角度分开调节,各设一个按钮,不让其相互影响
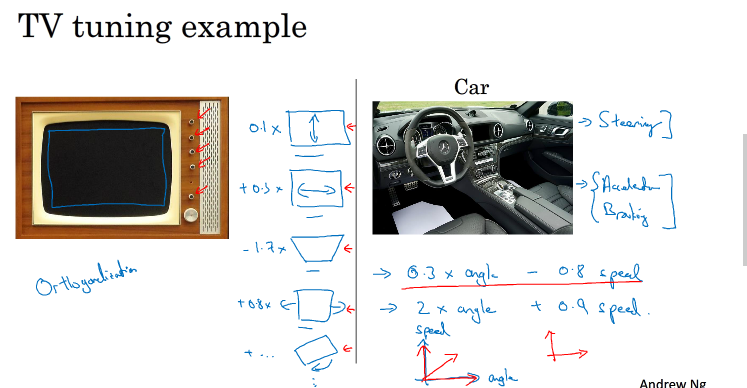
这其实就是正交化,即在调节一个参数的时候,保持另外的参数不变,各个参数相互正交,不互相影响.

在机器学习中要解决如上左的四个问题,我们可以分别设置四个解决措施,如上右
第一条优化训练集可以通过使用更复杂NN,使用Adam等优化算法来实现;第二条优化验证集可以通过正则化,采用更多训练样本来实现;第三条优化测试集可以通过使用更多的验证集样本来实现;第四条提升实际应用模型可以通过更换验证集,使用新的cost function来实现。概括来说,每一种“功能”对应不同的调节方法。而这些调节方法(旋钮)只会对应一个“功能”,是正交的
3.Single number evaluation metric
机器学习中,我们往往是先有自己的想法,在写代码实现,在进行实验,实验后有新的想法,在改变代码,在实现,一直迭代这个过程
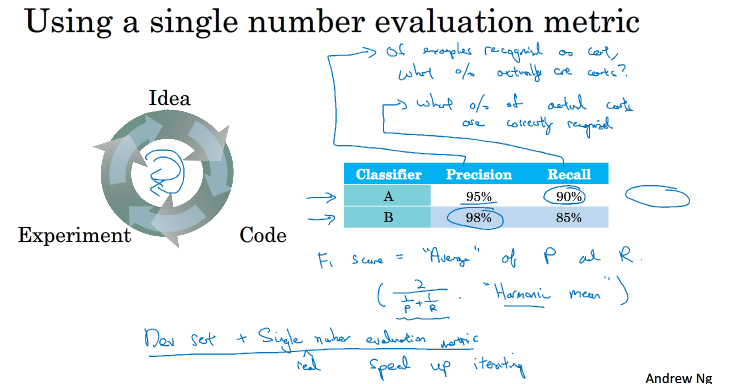
有一个单一数字评估指标能够帮助我们区分模型的好坏,选择较好的模型,加速这一过程的进展
假设我们有两个分类器A,B,现在有两个评估指标,其中precision为识别的猫中有多少是真的猫的百分比,recall为真正的猫中有多少被正确的识别的百分比
那该如何对A,B两个分类器进行一个选择,可以只设置一个评估指标:
F1 score,具体公式如上图,我们可以根据这个指标对分类器进行一个选择.
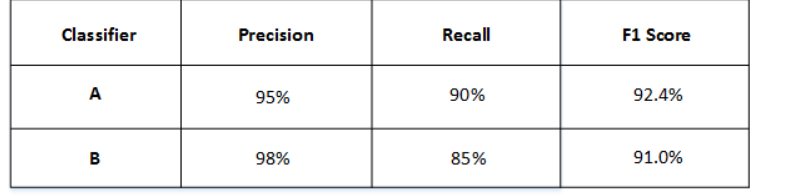
除了F1 score 外,还可以将平均值作为一个单一评估指标,如下:
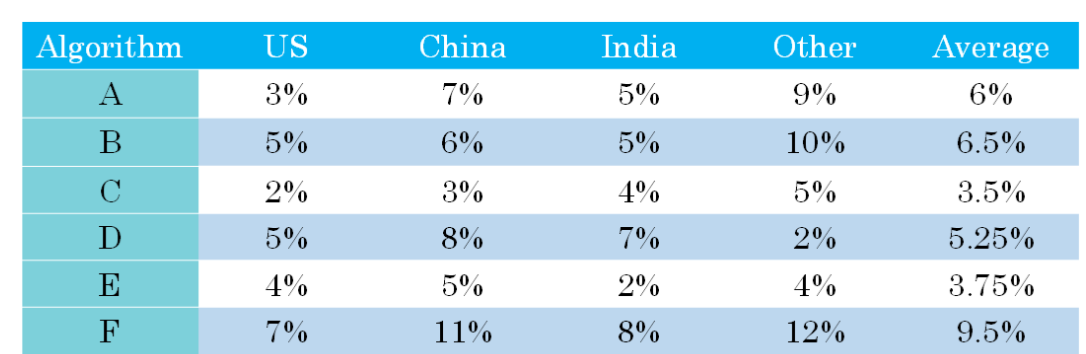
我们可以选择平均值最小的.
4.Satisficing and optimizing metrics
对不同的评估指标,如果无法综合成一个单一指标,那么我们可以设计satisficing metric 和optimizing metric

如图,我们要对A,B,C三个分类器进行一个选择,我们可以设两个指标,一个satisficing metic,一个optimizing metric ,
假设satificing metic:Running time<=100ms;
optimizing metric:Accuary越大越好
则选择B.
5.Train/dev/test distributions
dev set和test set 往往需要来自于同一分布
如果dev sets和test sets不来自同一分布,那么我们从dev sets上选择的“最佳”模型往往不能够在test sets上表现得很好。这就好比我们在dev sets上找到最接近一个靶的靶心的箭,但是我们test sets提供的靶心却远远偏离dev sets上的靶心,结果这支肯定无法射中test sets上的靶心位置。
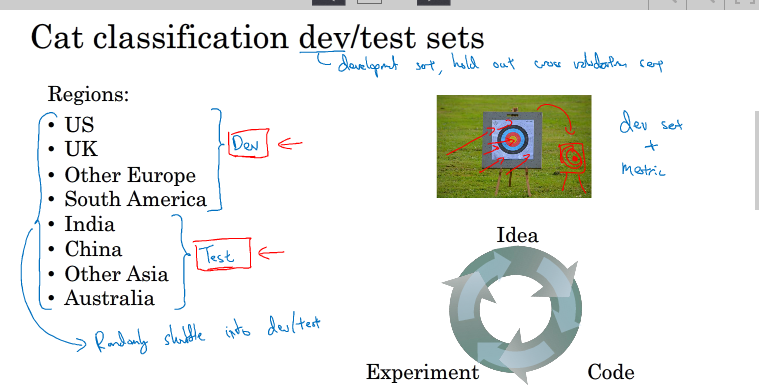
除此之外,dev set 和 test set的选择,往往选择我们之后所希望的得到重要的数据

6.size of dev and test sets
对于dev set 和test sets的size大小,之前已经讲过....
dev sets的大小选择原则,是能够检测不同算法/模型 的不同,从而选择最好的模型

test sets 的大小选择原则:能够反映模型在实际中的表现情况
实际应用中,可能只有train/dev sets,而没有test sets。这种情况也是允许的,只要算法模型没有对dev sets过拟合。但是,条件允许的话,最好是有test sets,实现无偏估计。
7.when to change dev/test sets and metric

假设有关于猫的分类器A,B,其中A的错误为3%,但会将一些色情图片也会识别为猫的图片,而B有5%的错误,但不会发生A中的情况
假设在实际应用中会将识别为猫的图片推送给用户,显然,用户是不愿意收到色情图片的推送的
这种情况下我们可以改变cost function,增加色情图片的权重:
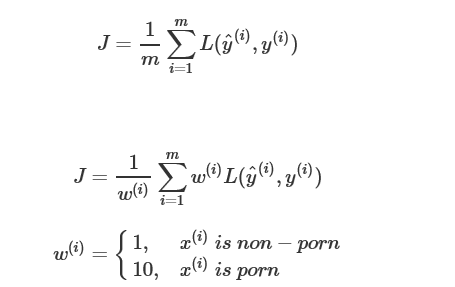
如果dev/test sets和实际中使用的不同,需要调整dev/test sets

机器学习过程可分为两个过程:1.找准靶心 2.击中靶心

但在训练的过程中可能会根据实际情况改变算法模型的评价标准,进行动态调整。
8.why human-level performance
随着训练时间的增加,机器学习的准确率在初期的时候会增加的比较快,但是在超过人类之后,准确率就会增加的比较慢,最终接近bayes optimized error,任何模型都不会超越bayes optimized error
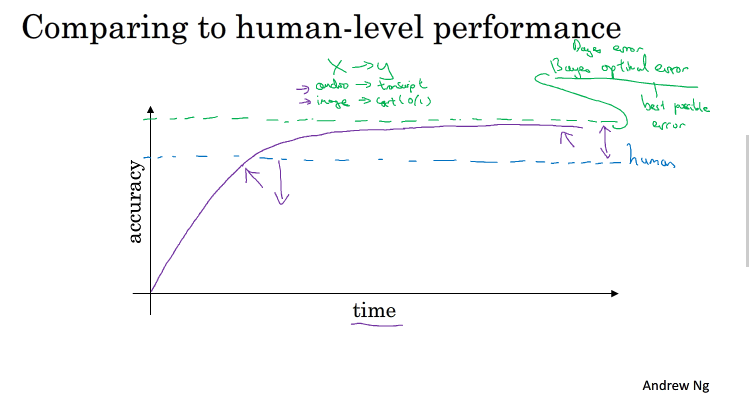
为什么和人比较:
人类在许多领域中都有着很好的表现,让机器学习靠近人类的表现很重要,为了让ML表现更好,你能:

9.avoidable bias
avoidable bias等于bayes optimized 与 traning set error之差
实际问题中,往往把人的误差作为贝叶斯最优误差

实际问题中,根据avoidable bias 与variance判断欠拟合还是过拟合
10.understand human-level performance
人的误差可以作为一个beyes optimized error
下面举一个例子:

human-level error为0.5%,当然根据实际的需要,我们可能会选择不同的human-level error
而用不同的human-level error可以计算得到不同的avoidable bias,根据bias与variance的比较,我们可以对我们的模型进行一个调整

当training error接近human-level error的时候,我们的ML 进展速度下降,难以对模型优化,因为这个时候human-level error不好选取,得到的bias 与varience不好比较,我们难以确定接下来的方向是降低bias还是varience.如上右图
11.surpassing human-level performance
ML中还是有许多已经超过human-level performance

12.Improving your model performance
提高模型性能两个方法:减下bias 和varience

具体方法如下:
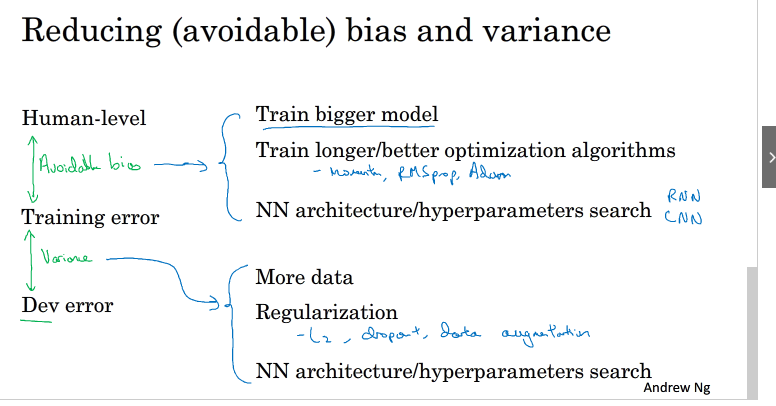














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









