






异常值是指那些显著偏离其他观测值的数据点,这些值可能由于错误、偏差或自然变异而产生,当然也可能本身在业务上就是合理的。异常值也被称为离群点,它们可能会扭曲统计分析的结果,导致错误的结论和决策。
一、异常值检测的重要性
数据质量保障:异常值可能源于数据采集、传输或存储中的错误,检测并处理这些异常值有助于提升数据质量,确保分析结果的准确性。
提升模型性能:异常值会影响机器学习模型的训练效果,导致模型偏差或过拟合。通过检测并处理异常值,可以提高模型的泛化能力。
发现潜在机会:异常值有时反映了数据中的特殊现象或潜在机会,如金融欺诈、设备故障等,及时检测有助于抓住这些机会或规避风险。
优化决策:异常值可能导致错误的业务决策,检测并处理这些值有助于做出更合理的决策。
二、异常值检测方法
统计方法:
Z-Score:通过计算数据点与均值的标准差倍数来识别异常值,通常Z-Score绝对值大于3的数据点被视为异常。
IQR(四分位距):利用数据的四分位数计算IQR,超出1.5倍IQR范围的数据点被视为异常。
机器学习方法:
孤立森林(Isolation Forest):通过构建树结构隔离数据点,异常值因容易被隔离而被识别。
One-Class SVM:适用于无标签数据,通过构建一个超平面将正常数据与异常数据分离。
聚类方法:
DBSCAN:基于密度的聚类算法,将低密度区域的数据点识别为异常值。
K-Means:通过计算数据点到聚类中心的距离,距离过大的点被视为异常。
深度学习方法:
自编码器(Autoencoder):通过重建误差识别异常值,重建误差大的数据点被视为异常。
GAN(生成对抗网络):通过生成器和判别器的对抗训练,识别不符合正常数据分布的异常值。
时间序列方法:
移动平均:通过计算移动平均值和标准差,识别偏离较大的数据点。
STL分解:将时间序列分解为趋势、季节性和残差部分,残差异常大的点被视为异常。
三、异常值处理
删除:直接删除异常值,适用于异常值较少且对整体分析影响较小的情况。
替换:用均值、中位数等替代异常值,适用于异常值较多但不适合删除的情况。
修正:根据业务逻辑修正异常值,适用于异常值由数据错误引起的情况。
保留:在异常值反映重要信息时保留,适用于异常值具有特殊意义的情况。
本文的目的只是为了基于工具包和常用的方法来进行异常值检测,并非为了研究,当然具体算法我也未必看的懂。
第一段代码是导入相关包、设置图表中文显示、设置pandas表格标准化展示、定义了四个函数
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from scipy import special
from sklearn.neighbors import LocalOutlierFactor
from sklearn.cluster import DBSCAN
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
from sklearn.decomposition import PCA
from scipy import stats
from sklearn.mixture import GaussianMixture
from sklearn.preprocessing import StandardScaler
# 设置matplotlib正常显示中文和负号
matplotlib.rcParams['font.family'] = 'SimHei' # 设置字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
# ---------------------------------------对pandas显示进行格式化-----------------------------------------
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 不换行显示
pd.set_option('display.width', 1000)
# 行列对齐显示,显示不混乱
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 显示精度
pd.set_option('display.precision', 4)
# 显示小数位数
pd.get_option("display.precision")
# ---------------------------------------查看pandas缺失情况-----------------------------------------
def pandasnullinfo(df):
missing = df.isna().sum()
missing = pd.DataFrame(data={'feature_name': missing.index, 'null_value_num': missing.values})
# 通过~取反,选取不包含数字0的行
missing = missing[~missing['null_value_num'].isin([0])]
# 缺失比例
missing['null_value_ratio'] = missing['null_value_num'] / df.shape[0]
return missing
# 可视化函数
def plot_data(X, outliers, title):
plt.figure(figsize=(10, 6))
plt.scatter(range(len(X)), X, edgecolor='k', s=20, label='Data')
plt.scatter(outliers, X[outliers], color='red', edgecolor='k', s=50, label='Outliers')
plt.title(title)
plt.legend()
plt.show()
# 3个西格玛以外的值为异常值,为Z-score的特例
def detect_outliers_std(X):
mean = np.mean(X)
std = np.std(X)
outliers = np.where((X > mean + 3 * std) | (X < mean - 3 * std))
return outliers
# -Zscore是统计学中用于标准化数据的一种方法,它衡量一个数据点与数据集均值的偏差程度,以标准差为单位表示。
# 设定阈值:通常设定±3作为阈值。即如果某个数据点的Z-score绝对值大于3,通常认为它是一个异常值。
def Zscore(X:np.ndarray,N=3):
mean, std = np.mean(X), np.std(X)
lower, upper = mean-N*std, mean+N*std
mask = (lower <= X) & (X<= upper)
return mask第二段代码是基于numpy构建数据和异常值数据集,并通过已定义的函数,实现快速图形化展示。
np.random.seed(21)
X_normal = np.random.normal(loc=0, scale=3, size=100) # 生成指定均值和标准差的正态分布随机数;
X_uniform = np.random.uniform(low=-5, high=5, size=100) # 生成均匀分布随机数;
# 添加异常值
X_normal_with_outliers = np.append(X_normal, [10, 15, -10, -15])
X_uniform_with_outliers = np.append(X_uniform, [10, 15, -10, -15])
outliers_std_normal = detect_outliers_std(X_normal_with_outliers)
outliers_std_uniform = detect_outliers_std(X_uniform_with_outliers)
plot_data(X_normal_with_outliers, outliers_std_normal[0], 'Standard Deviation Method -正态分布+异常值')
plot_data(X_uniform_with_outliers, outliers_std_uniform[0], 'Standard Deviation Method -非正态分布+异常值')可视化显示结果如下:
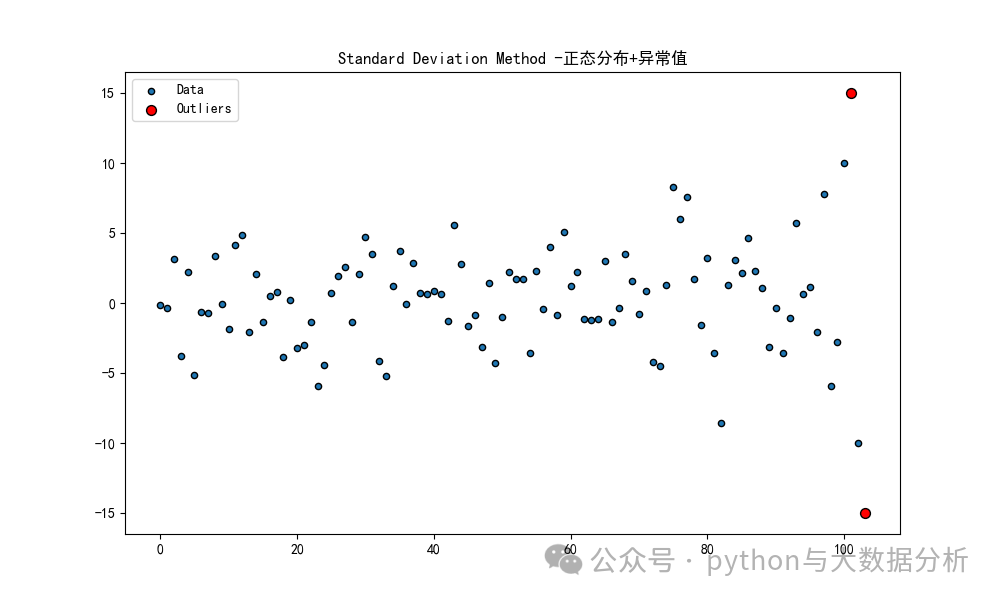
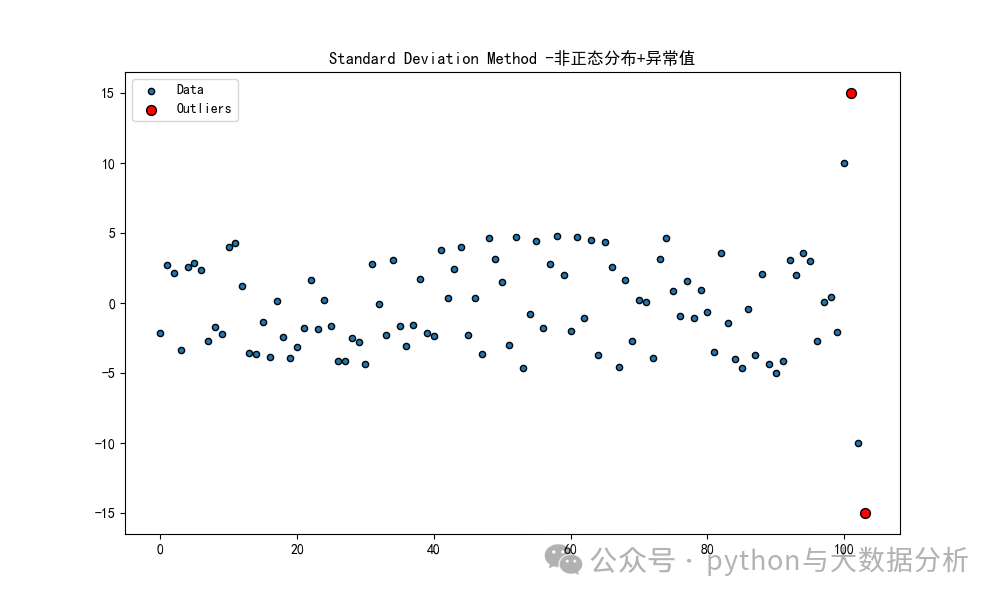
第三段代码是导入自行车加速度计数的数据集,快速实现数据可视化和基于线箱图的数据分布。
# 在本节中,使用Python代码介绍了检测数据集中异常值的不同方法,本文使用了包含加速度计数据(在自行车活动期间捕获)的数据集。
# 所有CSV文件都包含索引、时间戳以及X、Y和Z轴的加速度。
# 因为所有自行车都有不同的悬架,因此加速度的幅度也不同,尽可能使用一致的记录设置,以确保数据具有可比性。
data_path = r'E:\JetBrains\PythonProject\DeepLearning\Accelerometer_Data.csv'
data = pd.read_csv(data_path, index_col=0)
data.describe()
# time x y z
# count 6500.00006500.00006500.00006500.0000
# mean 32.4955 0.0547 0.3972 -0.7299
# std 18.7653 1.8074 2.6213 2.8407
# min 0.0005 -6.8461 -7.7641 -15.7191
# 25% 16.2480 -1.0901 -1.3537 -2.6711
# 50% 32.4955 -0.0212 0.3727 -0.9098
# 75% 48.7430 1.0592 2.0862 1.0700
# max 64.9905 22.1790 17.6766 20.2469
pandasnullinfo(data)
# Empty DataFrame
# 折线图(Line-plot):如实反映数据的真实状况,尤其是时间序列
# 箱形图(Box-plot):# 又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。
# 它能显示出一组数据的最大值、最小值、中位数及上下四分位数
fig, axs = plt.subplots(6, figsize=(16, 8))
fig.suptitle('Visual Inspection of the Data', size=20)
sns.lineplot(data=data, x='time', y='x', ax=axs[0])
axs[0].set(title='Lineplot over Time')
sns.boxplot(data['x'], orient='h', ax=axs[1])
axs[1].set(title='Boxplot of X-Axis')
fig.suptitle('Visual Inspection of the Data', size=20)
sns.lineplot(data=data, x='time', y='y', ax=axs[2])
axs[2].set(title='Lineplot over Time')
sns.boxplot(data['y'], orient='h', ax=axs[3])
axs[3].set(title='Boxplot of Y-Axis')
fig.suptitle('Visual Inspection of the Data', size=20)
sns.lineplot(data=data, x='time', y='z', ax=axs[4])
axs[4].set(title='Lineplot over Time')
sns.boxplot(data['z'], orient='h', ax=axs[5])
axs[5].set(title='Boxplot of Z-Axis')
plt.tight_layout()
plt.show()可视化展示如下
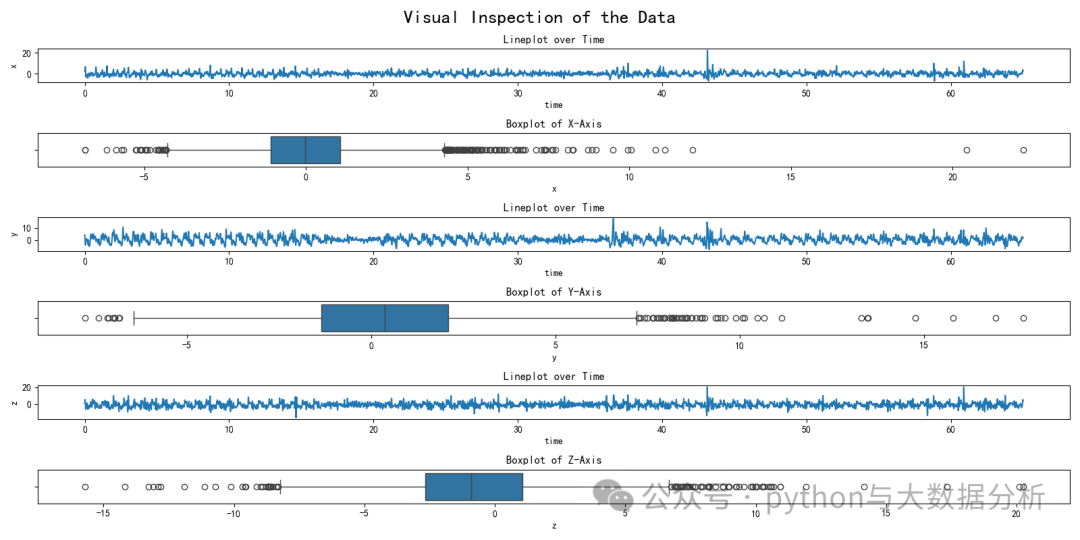
第四段代码是是基于指定分位数的异常值检测,主要使用pandas.quantile函数。
# ----------通过设定数据集的指定分位数判断异常值------------
# quantile函数用于计算数据集的指定分位数,这里设定上限2%和下限2%的数据为异常值
# 当然这里只能设定单一列
lower_q, upper_q = 0.02, 0.98## determine the qyartule thresholds.
lower_value = data['z'].quantile(lower_q)## apply the lower threshold to dataset.
upper_value = data['z'].quantile(upper_q)## apply the upper threshold to dataset.
# 为正常值和异常值创建一个掩码numpy
mask = (lower_value <= data.z) & (data.z <= upper_value)#
# 绘制数据散点图
fig, ax = plt.subplots(figsize=(16, 6))## create a plot
fig.suptitle('Quantile-Based Outlier Detection', size=20) ## create title
sns.scatterplot(data=data, x='time', y='z', hue=np.where(mask, 'No Outlier', 'Outlier'), ax=ax) ## apply color to outlier/no outlier
plt.tight_layout() ##makes sure that all variables and axes are readable
plt.show()可视化展示结果如下:
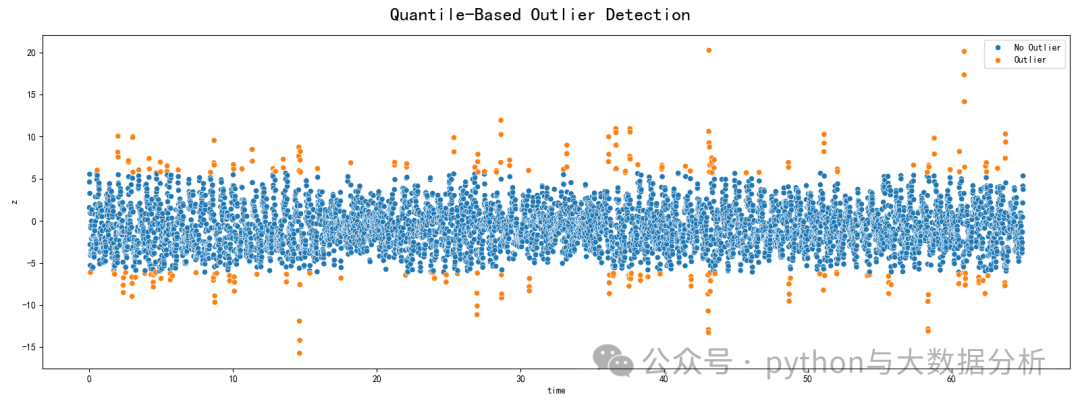
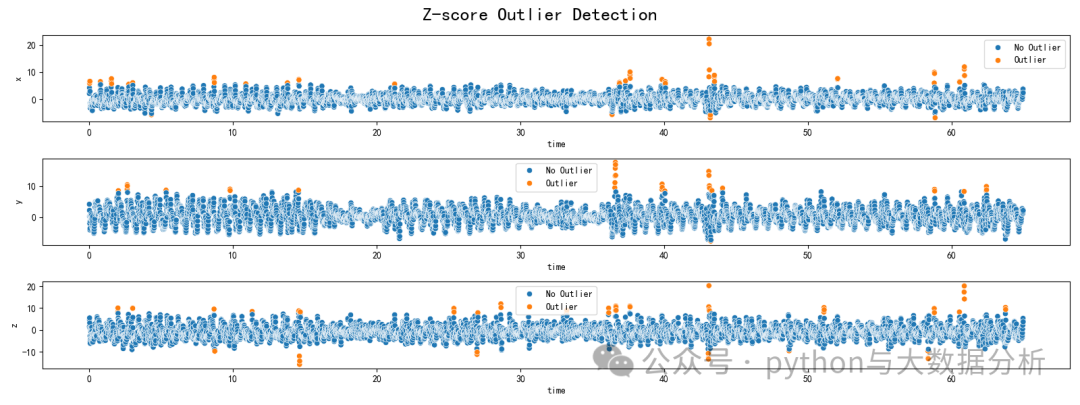
第五段代码是基于Z-score的异常值检测
# ----------通过Z-score方法判断异常值,这里为3,实际上是三个西格玛------------
fig, axs = plt.subplots(3,figsize=(16, 6))## create a plot
fig.suptitle('Quantile-Based Outlier Detection', size=20) ## create title
sns.scatterplot(data=data, x='time', y='x', hue=np.where(Zscore(data['x']), 'No Outlier', 'Outlier'), ax=axs[0]) ## apply color to outlier/no outlier
sns.scatterplot(data=data, x='time', y='y', hue=np.where(Zscore(data['y']), 'No Outlier', 'Outlier'), ax=axs[1]) ## apply color to outlier/no outlier
sns.scatterplot(data=data, x='time', y='z', hue=np.where(Zscore(data['z']), 'No Outlier', 'Outlier'), ax=axs[2]) ## apply color to outlier/no outlier
plt.tight_layout()
plt.show()可视化展示如下:
接下来是基于DBSCAN和LocalOutlierFactor、IsolationForest的异常值检测,大家可以看看这几种方法的相同点和异常点,在这里不多做介绍了。
DBSCAN和LocalOutlierFactor、IsolationForest
相同点:
目的相同:这三种方法都是用于异常值检测,旨在从数据集中识别出那些与其他数据点显著不同的点。
非监督学习:它们都采用了非监督学习的策略,不需要事先知道数据的标签。
不同点:
DBSCAN(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚类算法,通过将具有足够高密度的区域划分为簇,而将密度不足的点标记为噪声(异常值)。
LocalOutlierFactor(LOF):基于局部异常因子,通过比较给定点的局部密度与周围点的局部密度来识别异常值。如果一个点的局部密度显著低于其邻居,则该点被认为是异常值。
IsolationForest:通过构建多个孤立树(孤立树是一种决策树,用于隔离数据点),如果一个数据点的孤立树路径较短,说明它与其他数据点相比是较孤立的,因此被认为是异常值。
性能和适用场景:
DBSCAN:适用于大规模数据集,但参数选择(如ε和minPts)较为敏感。
LocalOutlierFactor:计算成本较高,但对参数不敏感,适用于中等大小的数据集。
IsolationForest:计算效率高,适用于大规模数据集,但对极端异常值不敏感。
参数调整:
DBSCAN需要调整ε(邻域半径)和minPts(形成密集区域所需的最小点数)。
LocalOutlierFactor主要调整n_neighbors(考虑的邻居数量)和contamination(预计的异常值比例)。
IsolationForest主要调整n_estimators(森林中的树的数量)和contamination。
第六段代码是基于局部异常因子的离群点检测方法
# ----------基于局部异常因子的离群点检测方法------------
# 基于密度的离群点检测方法的关键步骤在于给每个数据点都分配一个离散度,
# 其主要思想是:针对给定的数据集,对其中的任意一个数据点,如果在其局部邻域内的点都很密集,那么认为此数据点为正常数据点;
# 而离群点则是距离正常数据点最近邻的点都比较远的数据点。通常有阈值进行界定距离的远近。
# 在这里,我们用x,y,z三个变量的组合
fig, axs = plt.subplots(nrows=3, figsize=(16, 6))## create plot with three sub-plots
fig.suptitle('LocalOutlierFactor Outlier Detection', size=20)
lof = LocalOutlierFactor(n_neighbors=5)
mask = lof.fit_predict(data[['x', 'z']])
sns.scatterplot(data=data, x='x', y='z', hue=np.where(mask==1, 'No Outlier', 'Outlier'), ax=axs[0])
axs[0].set(title=f'Neighbors = with x,z Outliers')
lof = LocalOutlierFactor(n_neighbors=5)
mask = lof.fit_predict(data[['y', 'z']])
sns.scatterplot(data=data, x='y', y='z', hue=np.where(mask==1, 'No Outlier', 'Outlier'), ax=axs[1])
axs[0].set(title=f'Neighbors = with y,z Outliers')
lof = LocalOutlierFactor(n_neighbors=5)
mask = lof.fit_predict(data[['x', 'y']])
sns.scatterplot(data=data, x='x', y='y', hue=np.where(mask==1, 'No Outlier', 'Outlier'), ax=axs[2])
axs[0].set(title=f'Neighbors = with y,z Outliers')
plt.tight_layout()
plt.show()可视化展示结果如下:
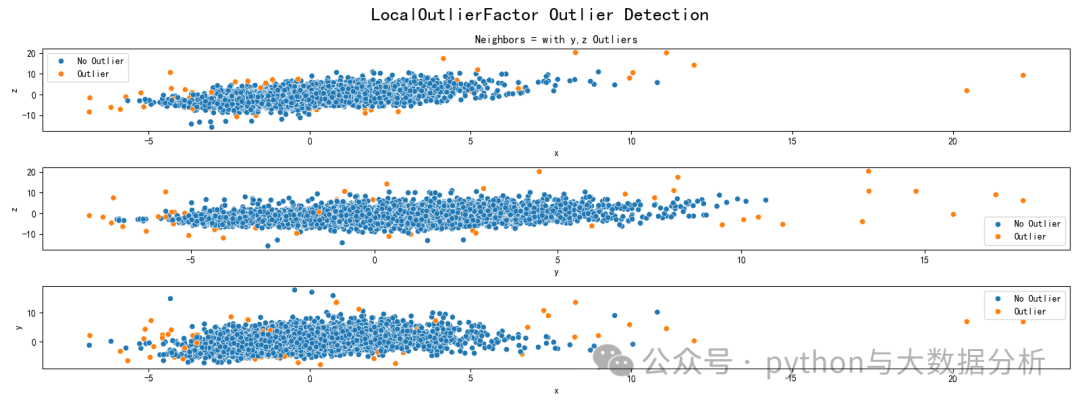
第六段代码是基于密度的聚类算法(DBSCAN)的离群点检测方法
# ----------基于密度的聚类算法的离群点检测方法------------
# dbscan算法是一种基于密度的聚类方法,它能够把具有相似特征的数据点聚成一类,并识别出离群点
# DBSCAN的核心思想是通过找到数据空间中的高密度区域,将这些区域作为簇,同时将孤立点(密度低的点)归为噪声
scaler = StandardScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(data), columns=data.columns)
dbscan = DBSCAN(eps=1.5, min_samples=3) # eps是邻域的大小,min_samples是最小样本数以形成一个核心点
labels = dbscan.fit_predict(df_scaled)
data['cluster'] = labels
anomalies = data[data['cluster'] == -1]
fig, axs = plt.subplots(nrows=3, figsize=(16, 12))## create plot with three sub-plots
fig.suptitle('DBSCAN Cluster Outlier Detection', size=20)
scatter = sns.scatterplot(data=data, x='x', y='z', hue='cluster', palette='husl', ax=axs[0], legend=True)
# axs[0].set(title=f'Neighbors = with x,z Outliers')
scatter = sns.scatterplot(data=data, x='y', y='z', hue='cluster', palette='husl', ax=axs[1], legend=True)
# axs[0].set(title=f'Neighbors = with y,z Outliers')
scatter = sns.scatterplot(data=data, x='x', y='y', hue='cluster', palette='husl', ax=axs[2], legend=True)
# axs[0].set(title=f'Neighbors = with y,z Outliers')
plt.tight_layout()
plt.show()可视化展示结果如下:
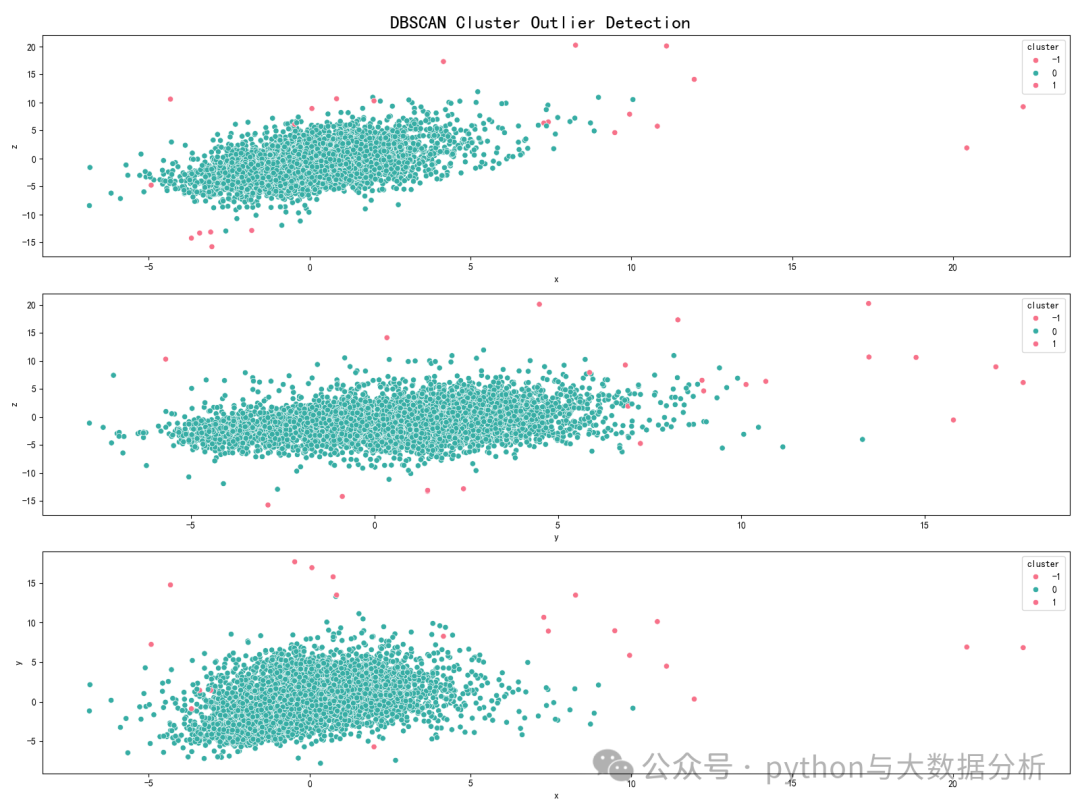
第七段代码是基于孤立树算法(IsolationForest)的离群点检测方法
# ----------基于孤立树的离群点检测方法------------
# 通过构建多个孤立树(孤立树是一种决策树,用于隔离数据点),如果一个数据点的孤立树路径较短,说明它与其他数据点相比是较孤立的,因此被认为是异常值。
model = IsolationForest(contamination=0.005, random_state=42) # 假设异常值占5%
model.fit(data)
data['cluster'] = model.predict(data)
fig, axs = plt.subplots(nrows=3, figsize=(16, 12))## create plot with three sub-plots
fig.suptitle('IsolationForestOutlier Detection', size=20)
scatter = sns.scatterplot(data=data, x='x', y='z', hue='cluster', palette=['red','blue'], ax=axs[0], legend=True)
# axs[0].set(title=f'Neighbors = with x,z Outliers')
scatter = sns.scatterplot(data=data, x='y', y='z', hue='cluster', palette=['red','blue'], ax=axs[1], legend=True)
# axs[0].set(title=f'Neighbors = with y,z Outliers')
scatter = sns.scatterplot(data=data, x='x', y='y', hue='cluster', palette=['red','blue'], ax=axs[2], legend=True)
# axs[0].set(title=f'Neighbors = with y,z Outliers')
plt.tight_layout()
plt.show()可视化展示结果如下:
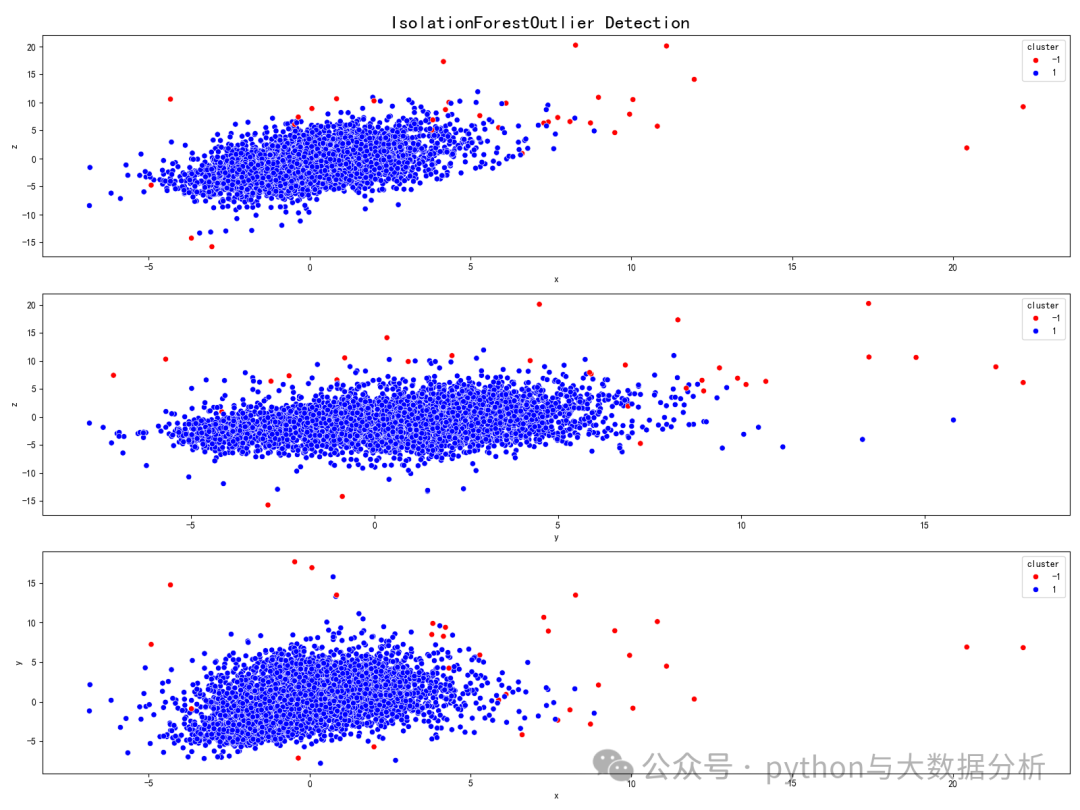
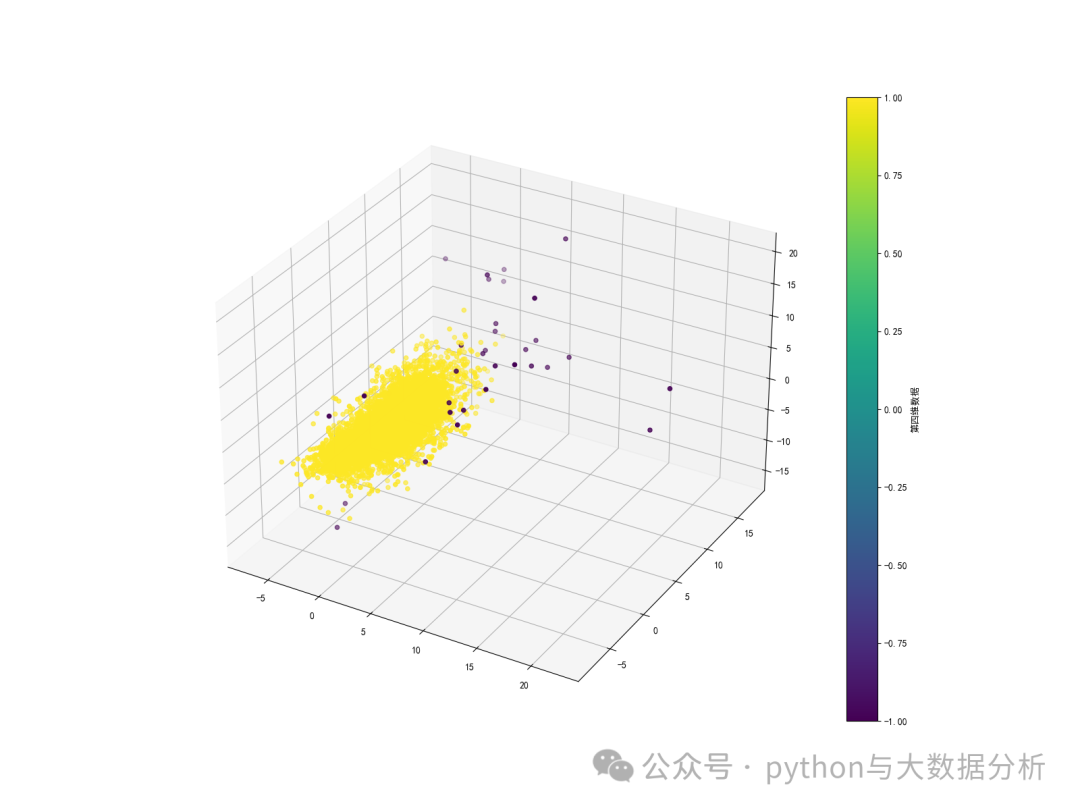
第八段代码是基于孤立树算法(IsolationForest)的3D可视化展示
# 3D显示孤立树的离散点
fig = plt.figure(figsize=(16, 12))
ax = fig.add_subplot(111, projection='3d')
sc = ax.scatter(data['x'], data['y'], data['z'], c=data['cluster'], cmap='viridis')
cbar = fig.colorbar(sc)
cbar.set_label('第四维数据')
plt.show()可视化展示结果如下:
后续会继续介绍新的工具来实现异常值快速检测。
最后欢迎关注公众号:python与大数据分析



















 2624
2624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











