







新手村:异常值检测-Z-score与IQR方法
(聚焦Z-score与IQR方法)

一、前置条件
| 知识领域 | 要求 |
|---|---|
| 编程基础 | Python基础(变量、循环、函数)、Jupyter Notebook或PyCharm使用。 |
| 统计学基础 | 理解均值、中位数、标准差、四分位数、正态分布、Z-score等概念。 |
| 数据预处理 | 数据清洗、特征缩放(标准化/归一化)、数据可视化(Matplotlib/Seaborn)。 |
二、渐进式学习计划
| 阶段 | 学习目标 | 核心内容 | 时间分配 | 难度评分(1-5) |
|---|---|---|---|---|
| 1. 统计基础 | 掌握均值、中位数、标准差、四分位数等统计量计算。 | 数据分布中心与离散程度的度量。 | 2小时 | 1.0 |
| 2. Z-score方法 | 理解Z-score定义及其在异常检测中的应用。 | Z-score公式、正态分布假设、阈值选择(如±3σ)。 | 3小时 | 2.0 |
| 3. IQR方法 | 掌握IQR的计算及箱线图可视化。 | 四分位数、IQR定义、上下界计算、非正态分布适用性。 | 3小时 | 2.0 |
| 4. 实战对比 | 对比Z-score与IQR在不同数据集中的表现。 | 数据分布类型选择方法、可视化结果分析。 | 4小时 | 3.0 |
| 5. 缺失值处理 | 学习异常值处理策略(删除、填充、转换)。 | 根据业务场景选择处理方式,避免数据偏差。 | 2小时 | 2.5 |
一、Z-score方法详解
核心知识点
| 知识点 | 理论表达 | 通俗解释 | 重要性评分(1-5) |
|---|---|---|---|
| Z-score公式 | Z = X − μ σ Z = \frac{X - \mu}{\sigma} Z=σX−μ X X X:数据点; μ \mu μ:均值; σ \sigma σ:标准差。 |
数据点距离均值有多少个标准差。Z值越大,数据点越异常。 | 5 |
| 正态分布假设 | Z-score方法假设数据服从正态分布(钟形曲线)。 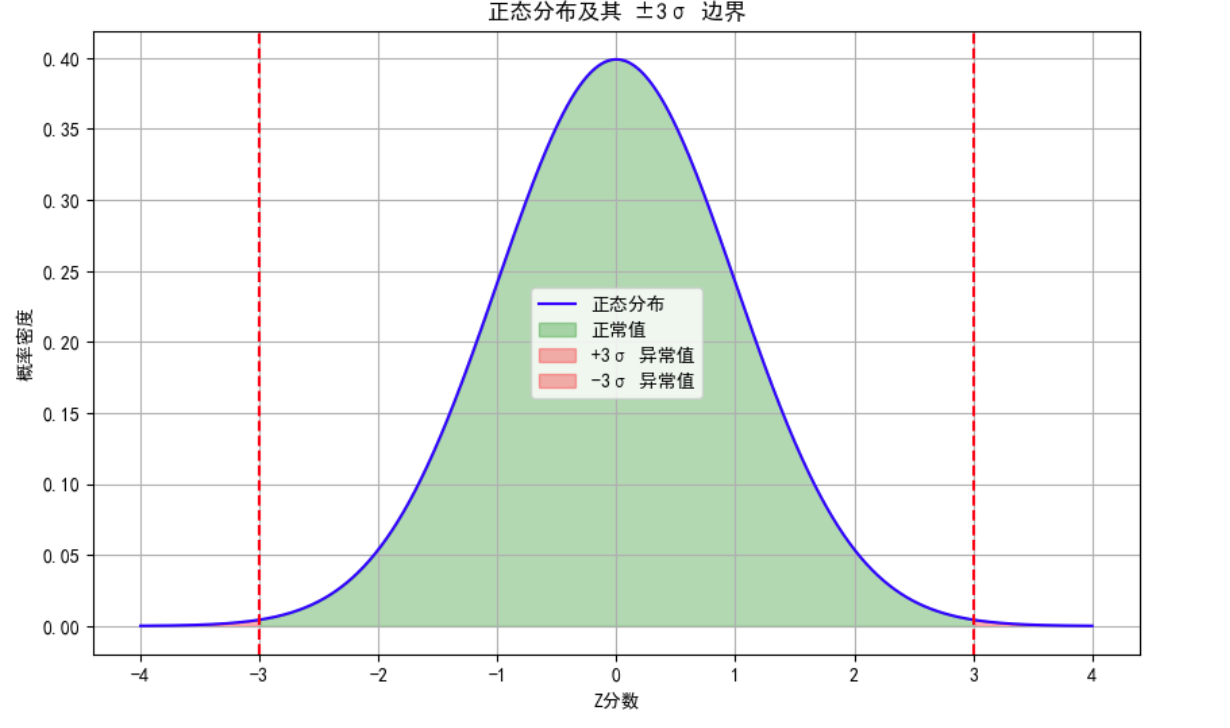 |
若数据分布偏斜或非正态,Z-score可能误判异常值。 | 5 |
| 阈值选择 | 常用阈值为±3σ(对应Z值±3),即99.7%数据在均值±3σ范围内。 |
超过阈值的点被标记为异常值。例如,Z=3.33的点会被视为异常。 | 5 |
计算步骤
-
计算均值(μ)和标准差(σ):
mu = np.mean(data) sigma = np.std(data) -
计算每个数据点的Z-score:
z_scores = (data - mu) / sigma -
设定阈值并筛选异常值:
threshold = 3 outliers = data[abs(z_scores) > threshold]
示例
它绘制数据的直方图和理论上对应的正态分布曲线,并在图中标记出异常值
data = [100, 105, 110, 150, 95, 200, 80, 300, 120, 130]
代码演示
import numpy as np
import matplotlib.pyplot as plt
# 销售数据
data = [100, 105, 110, 150, 95, 200, 80, 300, 120, 130]
# 计算均值和标准差
mean = np.mean(data)
std_dev = np.std(data)
# 计算Z-score
z_scores = [(x - mean) / std_dev for x in data]
# 定义阈值
threshold = 2
# 标记异常值
outliers = [x for i, x in enumerate(data) if abs(z_scores[i]) > threshold * std_dev] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











