






Z分数异常检测
z 分数异常检测是一种基于标准化的异常值检测方法,它不受数据分布假设的限制,可以广泛应用于各种类型的数据集。
检测步骤:
1.计算数据集的均值(μ)和标准差(σ)。
2.计算每个数据点的z分数:z = (x - μ) / σ
其中x是原始数据点(它的值)。
3.定义异常值的阈值。通常情况下,当|z| > 3时,该数据点被认为是异常值。
代码实现:
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟数据集
np.random.seed(42)
data = np.random.randint(500, 1000, 95)
# 添加一些异常值
data[10] = 2
data[20] = 8
data[30] = 5500
data[40] = 5200
data[50] = 5100
# 计算均值和标准差
mean = np.mean(data)
std_dev = np.std(data)
# 计算z分数
z_scores = (data - mean) / std_dev
# 定义异常值阈值
z_threshold = 3
# 标记异常值
outliers = data[np.abs(z_scores) > z_threshold]
normal_data = data[np.abs(z_scores) <= z_threshold]
# 可视化结果
plt.figure(figsize=(12, 6))
plt.plot(data, label='Data', color='b', marker='o')
plt.axhline(y=mean, color='g', linestyle='-', label='Mean')
plt.axhline(y=mean - z_threshold * std_dev, color='r', linestyle='--', label='Lower Bound (z=3)')
plt.axhline(y=mean + z_threshold * std_dev, color='r', linestyle='--', label='Upper Bound (z=3)')
plt.scatter(np.where(np.abs(z_scores) > z_threshold), outliers, color='r', marker='x', s=100, label='Outliers')
plt.legend()
plt.title('Outlier Detection using Z-Score')
plt.xlabel('Index')
plt.ylabel('Data Values')
plt.show()
结果解读:
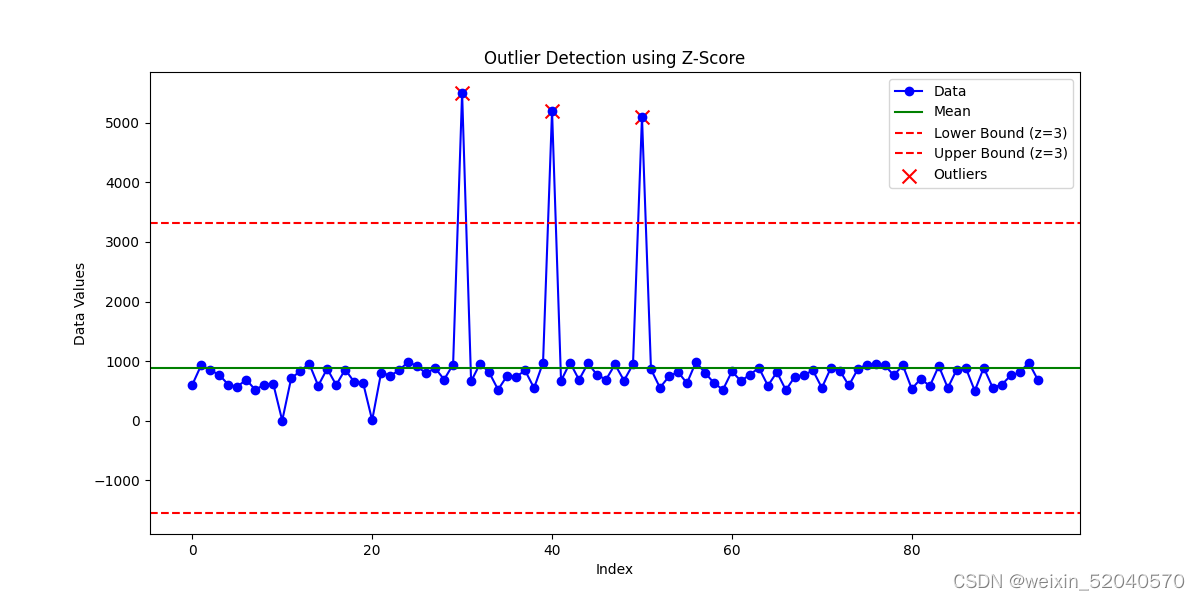
蓝色实线:表示数据的分布情况。
绿色实线:表示数据的均值(μ)。
红色虚线:表示异常值的上下界限(lower bound 和 upper bound),分别使用Z>3和Z<-3计算得出。
异常值——红色 "x" 标记:表示检测到的异常值。
与3σ关系
眼尖的小伙伴一下就看出来了:怎么和刚才的3σ检测一样呢?
这两种方法在数学上是相同的,因为Z分数方法实际上是3σ方法的标准化形式。具体来说:
在Z分数方法中,Z分数为3的点对应的实际值是μ+3 *σ,Z分数为-3的点对应的实际值是μ+3 *σ。
在3σ方法中,直接使用μ+3 *σ和μ+3 *σ作为异常值的边界。
当把Z=3作为阈值去剔除异常点时,便相当于3sigma法则了。
Grubbs假设检验
这种方法假设数据服从正态分布。
实现步骤:
计算Grubbs统计量:
1.计算数据集的样本平均值 μ
2.计算数据集的样本标准差 σ
3.对于每个数据点 x_i,计算标准化残差 |x_i -μ | / σ
4.从所有标准化残差中找出最大值,这就是 Grubbs 统计量 g_stat
计算临界值:
根据显著性水平α和样本大小 n,从 Grubbs 统计量临界值表中找到临界值 g_crit
进行假设检验:
原假设 H0: 数据集中不存在异常值
备择假设 H1: 数据集中存在异常值
如果计算得到的 g_stat > g_crit,则拒绝原假设,认为存在异常值
识别异常值:
如果存在异常值,则将导致 g_stat 最大的数据点保存为异常值
可以重复上述步骤,直到 g_stat <= g_crit
要点——如何使用表呢?
这有一个表的文件链接(百度搜也一样):Grubbs格拉布斯检验临界值表.xlsx-原创力文档
它的大概形式是这样的:

使用 Grubbs' test 临界值表的步骤如下:
1.确定显著性水平 α (通常使用0.1和0.05),取值越低,意味着检测出异常值的标准越严格。
2.根据样本大小 n,在表中找到对应的临界值g_crit。
3.将计算得到的 Grubbs 统计量 g_stat 与 g_crit 进行比较:
如果 g_stat > g_crit,则拒绝原假设,认为存在异常值。
如果 g_stat ≤ g_crit,则无法拒绝原假设,认为不存在异常值。
例如,对于一个样本量为 20 的数据集,当显著性水平 α = 0.05 时,临界值 g_crit = 2.581。
如果计算得到 g_stat = 3.045,由于 g_stat > g_crit,我们可以认为存在异常值。
代码实现:
import numpy as np
def grubbs_test(data, alpha=0.05):
"""
使用 Grubbs' test 检测和删除数据集中的异常值
参数:
data (numpy.ndarray): 待检测的数据集
alpha (float): 显著性水平, 默认为 0.05
返回值:
clean_data (numpy.ndarray): 处理后的数据集
num_outliers (int): 被删除的异常值个数
outlier_indices (list): 被删除的异常值的索引列表
"""
clean_data = np.copy(data)
num_outliers = 0
outlier_indices = []
while True:
n = len(clean_data)
mean = np.mean(clean_data)
std_dev = np.std(clean_data)
# 计算 Grubbs 统计量
g_stat = np.max(np.abs(clean_data - mean) / std_dev)
# 从表中查找临界值
z_crit_table = [1.155, 1.492, 1.749, 1.944, 2.097, 2.22, 2.323, 2.41, 2.485, 2.55, 2.607, 2.659, 2.705, 2.747,
2.785, 2.821, 2.854, 2.884, 3.001]
if n >= 3 and n <= 20:
g_crit = z_crit_table[n - 3]
else:
raise ValueError("样本量超出表格范围")
# 进行假设检验
if g_stat > g_crit:
# 存在异常值,找出异常值的索引,并从数据集中删除
outlier_index = np.argmax(np.abs(clean_data - mean) / std_dev)
clean_data = np.delete(clean_data, outlier_index)
num_outliers += 1
outlier_indices.append(outlier_index)
else:
# 不存在异常值,返回处理后的数据集
return clean_data, num_outliers, outlier_indices
# 使用示例数据进行检测和处理
data = np.random.randint(500, 1000, 20)
data[10] = 8000
data[19]= 10011
clean_data, num_outliers, outlier_indices = grubbs_test(data)
print("处理后的数据集:", clean_data)
print("被删除的异常值个数:", num_outliers)
print("被删除的异常值的索引:", outlier_indices)运行结果:

代码具体解释
首先,代码会创建一份数据集的副本 clean_data,用于后续的异常值检测和删除操作。
进入循环检查部分:
计算数据集的样本量 n、均值 mean 和标准差 std_dev。
计算 Grubbs 统计量 g_stat(上面的公式)。
从预先准备好的临界值表格中查找临界值 g_crit,根据样本量 n 从表中找到对应的值。
进行假设检验:
如果 g_stat 大于 g_crit,则说明数据集中存在异常值。
找出异常值的索引 outlier_index,该索引对应于 clean_data 中绝对值偏离平均值最大的元素。
从 clean_data 中删除该异常值,更新 clean_data。
与其他算法不同的是,程序需要通过不断的迭代,每次删除一个,删除后再次进行检验......依次删除这些异常值。
要点,适用:
Grubbs检验是一种基于标准正态分布的假设检验方法,用于检测单个异常值。它假设数据服从正态分布,并判断最大偏差是否超过临界值,从而确定是否存在异常值。
当数据中存在一个或少数几个异常值时效果较好。如果数据中存在多个异常值,或者数据不服从正态分布,Grubbs检验的效果可能不太理想,此时可以考虑使用其他异常值检测方法。















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









