








 https://github.com/yangjianxin1/LEBERT-NER-Chinese
https://github.com/yangjianxin1/LEBERT-NER-Chinese2、论文:https://arxiv.org/abs/2105.07148
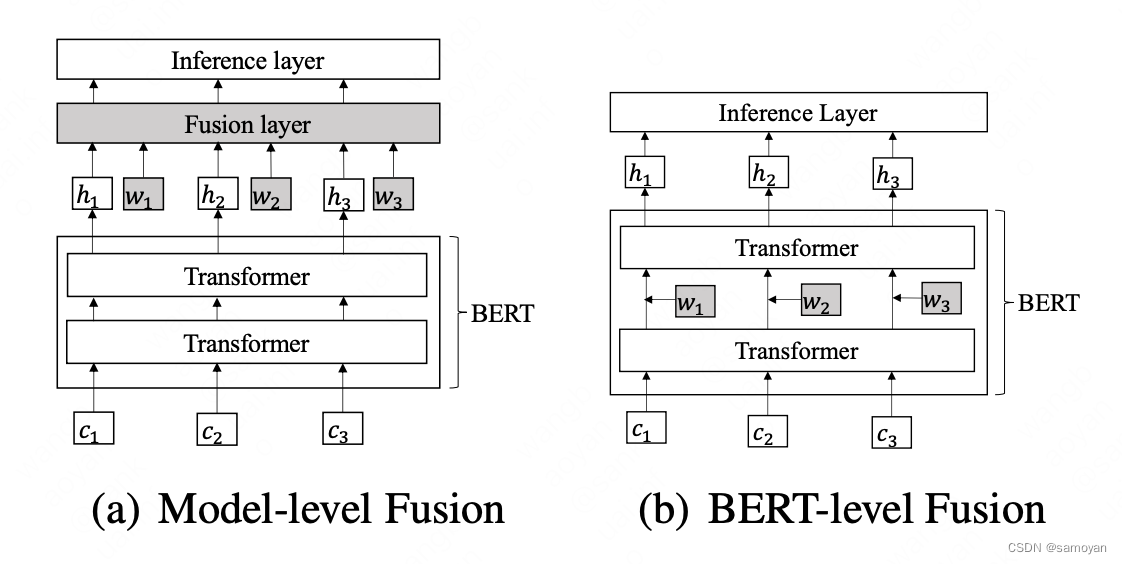
由于词汇信息和预训练模型(如BERT)各自的优势,大家已经结合起来探索中文序列标注任务。然而,现有的方法仅仅通过一个浅层和随机初始化的序列层来融合词典特征,而没有将它们集成到底层的。本文提出了一种用于中文序列标注的词典增强型BERT(LEBERT),它通过一个词典适配器层将外部词典知识直接集成到BERT层。与现有的方法相比,该模型有助于在BERT的底层进行深层词汇知识融合。
以前融合词汇的ner方法主要思想是将BERT和词典特征的上下文表示集成到神经序列标记模型中(如图1(a)所示)。然而,这些方法没有充分利用BERT的表示能力,因为外部特征没有集成到底层。其主要思想是将BERT和词典特征的上下文表示集成到神经序列标记模型中(如图1(a)所示)。然而,这些方法没有充分利用BERT的表示能力,因为外部特征没有集成到底层。受关于BERT适配器的研究(Houlsby等人,2019年;Bapna和Firat,2019年;Wang等人,2020年)的启发,他们提出了词典增强型BERT(LEBERT)来直接集成BERT转换器层之间的词典信息。具体来说,通过将句子与现有词典进行匹配,将汉语句子转换为字符词对序列。词典适配器使用字符到单词的双线性注意机制为每个字符动态提取最相关的匹配单词。词典适配器应用于BERT中的相邻变压器之间(如图1(b)所示),以便词典特征和BERT表示通过BERT中的多层编码器充分交互。我们在训练期间对BERT和词典适配器进行微调,以充分利用单词信息,这与BERT适配器有很大不同(它固定了BERT参数)。
在使用的时候,我们主要是使用领域数据训练了领域词向量,然后使用了lebert 融合领域词典能力,在我们具体的项目当中提升了0.5个百分点。
| 方案 | P | R | F1 |
|---|---|---|---|
| 通用词向量+lebert | 90.97 | 87.91 | 89.41 |
| 领域词向量+lebert | 91.54 | 88.43 | 89.96 |
但是也随之增加了计算量,具体落地需要模型压缩了~
















 7440
7440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











