







摘要
【应用背景】针对自然语言处理中的情感分析任务,目前的深度学习方法还是通过大量的数据训练来逐步提升效果,并没有充分利用文本中的情感词信息。【方法】本文提出了一种集成了情感词典和注意力机制的双通道文本情感分析模型。基于自注意力机制的通道负责提取语义特征,基于情感注意力的通道负责提取情感特征,两个通道分别提取的特征融合后获得文本最终的向量表达。同时引入一种注意力软约束来平衡两个通道中的注意力。【结果】实验结果表明,双通道的结构能够分别关注文本的不同特征,语义特征和情感特征结合起来有效提升了模型的分类性能。由于集成了情感词典,模型还具有较好的可解释性。【结论】本文提出的情感分析模型与相关模型相比拥有较好的性能和可解释性。
关键词: 深度学习; 情感词典; 文本情感分析; 双通道; 注意力
引言
随着社交网络和电子商务的兴起,互联网上产生了越来越多包含用户情感倾向的文本数据。对这些信息进行精准的情感分析可以帮助政府了解大众舆情以及商家提升服务质量,对于社会具有广泛的现实意义,因此需要情感分析技术对这些数据进行处理和分析。句子级别的文本情感分析,就是对带有情感倾向的主观性文本进行情感倾向判别和分类[1]。
目前,针对情感分析问题的方法主要包括利用句法依存关系等规则的方法、基于传统机器学习的方法和基于深度学习建立神经网络的方法[2]。
基于规则的方法大多是利用情感词典和分析句法依存关系进行情感分析。情感词典是一种会对词语的情感极性、强度以及词性等属性进行标注的数据库。这种方法一般是先通过情感词典对文本中的词语进行情感词查询和句法语义分析,然后再依据词语在情感词典查询得到的情感值进一步判断文本的情感倾向[3]。这种方法实现起来比较方便,但是因为语言的句法复杂,同一个词放在不同的语境中表达的含义可能天差地别[4],所以存在准确度不高且泛化能力差的缺点。
基于机器学习的方法一般是将文本的词性、情感词、否定词等人工标注的特征映射为高维向量,然后通过支持向量机等分类算法通过有监督训练得到一个模型。这种方法的分类性能严重依赖于人工标注的准确性,并且不能对文本的上下文语义进行建模,因此也存在较大的局限性[5]。
基于深度学习的方法不依赖于人工标注,近年来得到长足的发展并取得较好的成果。例如Perikos等[6]使用集成学习的方法来进行文本情感的识别和分析;Kiritchenko等[7]使用神经网络从数据中学习判别特征;LiuJie等[8]使用多层级的双向门控循环网络(Bidirectional Gate Recurrent Unit, Bi-GRU)来处理顾客评论信息;Sun等[9]使用深度神经网络 (Deep Neural Network, DNN)模型来处理微博评论中的情感分类问题;Chen等[10]利用双通道卷积神经网络(Convolutional Neural Network, CNN)模型和字符嵌入在微博情感分类上取得了较好的成绩;Zhai等[11]使用集成注意力机制的Bi-GRU在方面级别的情感分析任务上取得了良好的性能;范涛等[12]使用图卷积网络(Graph Convolutional Network, GCN)和句法依存图对网民的评论文本进行情感分析。
情感词在以情感词典基础的传统情感分类算法中起到重要的作用,但是在深度学习模型中并没有得到充分的考虑和应用。受到文献[13]的启发,本文将情感词与深度学习网络结合起来提出一种基于情感词典和注意力的双通道模型(Lexicon Based Daul Channels with Attention, LDCA)。模型中基于Self-attention的语义信息提取通道(Semantic Extraction Channel, SEC)负责提取语义特征,基于情感注意力的情感信息提取通道(Emotion Extraction Channel, EEC)负责提取情感特征,两个通道分别关注不同维度的信息,然后将其分别提取的特征进行融合从而获得文本最终的向量表达。本文模型将情感词资源和深度学习相结合从而提高了模型整体性能。同时,情感词典的集成还帮助提升了模型的可解释性。
1 相关工作
1.1 情感词典
情感词典一般是通过规则方法、统计学方法、机器学习等方法构建而成。情感词典通常包含形容词、连词、副词等。这些词大概率能够对文本的情感倾向产生影响[14]。因此,在文本情感分析中,能够充分利用情感词典的信息对提高模型的性能具有积极意义。
本文使用的情感词典是SenticNet5[15]。Sent-icNet5并不是仅仅依赖关键词以及关键词的共现模式来构建,而是充分利用了关联常识概念的隐含语义信息。因此,这种建模方式能够较大程度上挖掘出词的情感倾向。
虽然目前使用情感词典的方法比较朴素,在性能上一般不如深度学习的方法,但是情感词典方法的一个比较突出的优点是其可解释性较高。基于情感词典的情感分析方法的可解释性属于结合认知和因果推理方式的可解释性。本文将人们的认知(情感词典)融入到模型中帮助人们理解模型对文本做出情感分类预测的原因,并且模型对语句注意力权重的分配进行可视化,从而验证模型在可解释性方面上的提升[16]。
1.2 词嵌入工具
Word2Vec[17]是一种词的分布式向量表示方法,能够把学习到的语义知识嵌入到词的向量表达中,但是Word2vec得到的是词的固定表征,无法解决一词多义等问题。
GloVe模型在2014年被Pennington等[18]提出,它是一种既使用了语料库的全局统计特征,也使用了局部的上下文特征的词向量方法。其在诸多情感分析模型[19-20]中被广泛应用,并且仍在不断发展和改进[21-22]。
1.3 Bi-GRU
门控循环网络(Gate Recurrent Unit, GRU)是循环神经网络(Recurrent Neural Network, RNN)的一个变种,和RNN相比它能够在保留长期序列信息的同时,减少梯度消失的问题。GRU与长短期记忆网络(Long short-term memory, LSTM)相比,内部结构更加简单,对计算能力的要求不高,同时收敛速度更快。GRU神经网络的更新方式如下:
rt=σ(wr⋅[ht−1,xt])rt=σ(wr⋅[ht−1,xt])
(1)
zt=σ(wz⋅[ht−1,xt])zt=σ(wz⋅[ht−1,xt])
(2)
ht¯=tanh(w⋅[rt∗ht−1,xt])ht¯=tanh(w⋅[rt∗ht−1,xt])
(3)
ht=(1−zt)∗ht−1+zt∗htht=(1−zt)∗ht−1+zt∗ht
(4)
GRU的运算是从前到后推进的,这种方式容易导致文本序列前面的信息没有后面的信息重要的问题。Bi-GRU增加了一个从后往前的隐藏层,能够更加充分地利用全文的信息,从而克服了这一缺陷。Bi-GRU的模型结构如图1所示,其中前向隐藏层的输出为 h⃗ th→t,后向隐藏层的输出为 h←th←t, Bi-GRU隐藏层的输出 HtHt可以表示为公式(5)。
图1
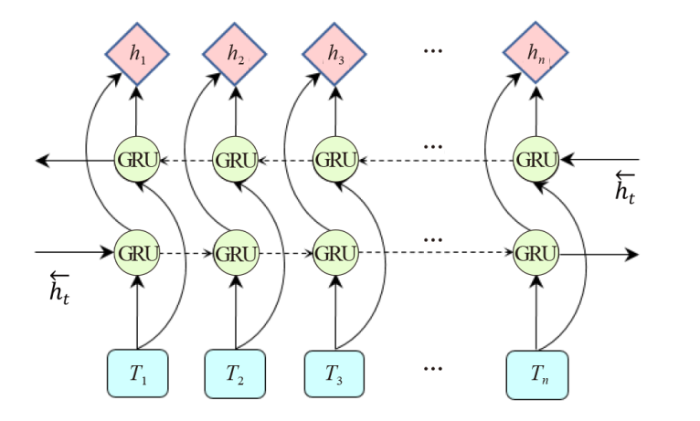
图1 Bi-GRU模型
Fig.1 Bi-GRU model structure
Ht=[h⃗ t,h←t]Ht=[h→t,h←t]
(5)
1.4 注意力机制
注意力机制首先在计算机视觉领域被提出,Bahdanau等[23]首次在机器翻译任务中使用注意力机制并取得良好的效果。通过引入注意力机制,深度学习模型能够关注文本序列中对当前任务目标更加重要的信息,从而达到模型优化的目的。其权重计算的本质可以描述为一个查询(Query)到一系列键值对(Key-Value)的映射。将Query和每个Key进行相似度计算得到权重,然后使用 softmaxsoftmax函数对这些权重进行归一化,最后将权重和相应的键值Value进行加权求和得到最后的注意力向量。自注意力(S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











