







论文地址: https://arxiv.org/pdf/2406.07522
SAMBA(Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling)是一种新型的基于Transformer的语言模型,旨在解决传统大语言模型在处理长文本时遇到的限制。下面详细解析SAMBA的核心特点以及它是如何改善长文本处理的。
1. 长文本处理的挑战
- 上下文窗口限制:传统的Transformer模型,如BERT或GPT系列,通常有固定的上下文窗口(例如512个token),超出这个范围的文本不能被模型有效处理。
- 注意力稀释和远程衰减:在长序列中,注意力机制可能变得不够集中,导致模型难以捕捉到关键信息,特别是序列两端的信息。
- 计算复杂度:Transformer的计算复杂度随序列长度平方增长,这使得处理长文本变得计算资源消耗巨大。
2. SAMBA模型的核心特点
SAMBA模型通过以下几个关键技术改进来解决上述问题:
- 无限上下文窗口:SAMBA设计了一种能够处理无限长文本的机制,这意味着理论上它可以考虑任意长度文本中的所有上下文信息。
- 状态空间模型:通过引入状态空间模型(State Space Models, SSM),SAMBA可以更高效地处理序列数据。状态空间模型在信号处理和控制理论中广泛使用,其能够在维持较低计算复杂度的同时,有效地捕捉时间序列数据中的动态变化。
- 混合注意力机制:结合了局部和全局注意力机制。局部注意力保持对近邻信息的敏感性,而全局注意力则允许模型捕捉长距离的依赖关系。
- 简化的训练和推理过程:通过优化模型架构和计算流程,SAMBA降低了对计算资源的需求,使得在实际应用中更加高效。
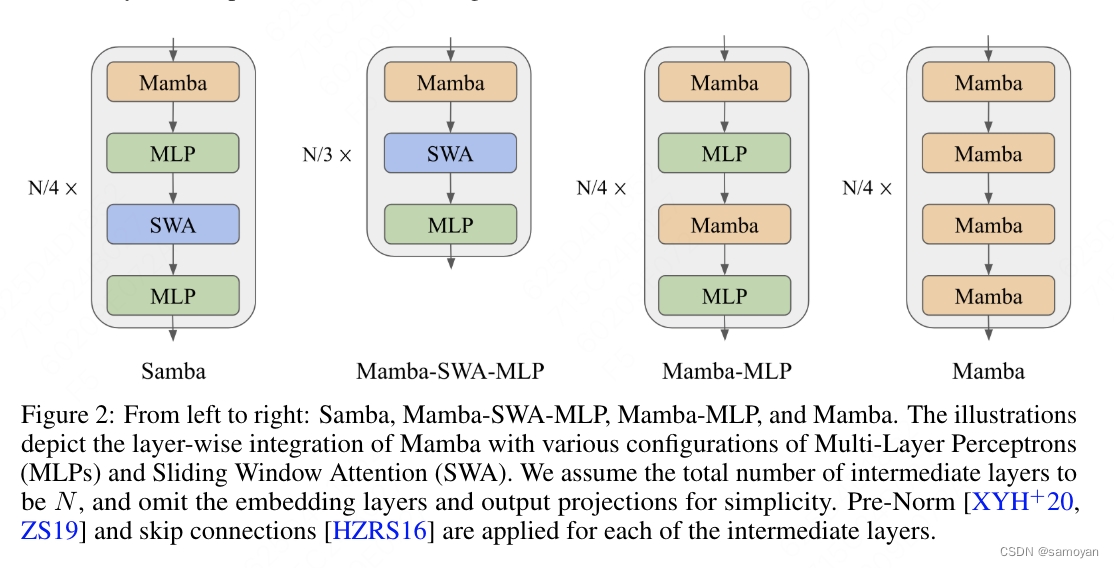
3. 结构
1、Mamba层
Mamba [GD23] 是一种最近提出的基于状态空间模型(SSM)的模型,具有选择性状态空间。它能够对循环状态和输入表示进行输入依赖的门控,从而软选择输入序列元素。给定一个输入序列表示 X ∈ R^n×dm,其中 n 是序列的长度,dm 是隐藏大小,Mamba 首先将输入扩展到更高的维度 de,即: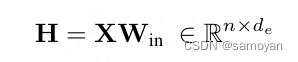 其中 Win ∈ R^dm×de 是一个可学习的投影矩阵。然后应用一个短卷积(SC)操作符来平滑输入信号,
其中 Win ∈ R^dm×de 是一个可学习的投影矩阵。然后应用一个短卷积(SC)操作符来平滑输入信号,
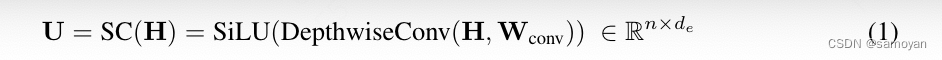
(1) 其中 Wconv ∈ R^k×de,核大小 k 设置为 4,以实现硬件效率。在序列维度上应用深度卷积 [HQW+19],随后是 SiLU [EUD17] 激活函数。然后通过低秩投影和 Softplus [ZYL+15] 计算选择性门控,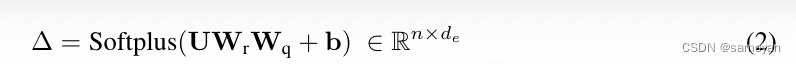 (2) 其中 Wr ∈ R^de×dr,Wq ∈ R^dr×de,dr 是低秩维度。b ∈ R^de 被谨慎初始化,以便在初始化阶段后 ∆ ∈ [∆min, ∆max]。我们设置 [∆min, ∆max] = [0.001, 0.1],并发现这些值对语言建模性能在困惑度指标下不敏感。输入依赖性也引入了 SSM 的参数 B 和 C,
(2) 其中 Wr ∈ R^de×dr,Wq ∈ R^dr×de,dr 是低秩维度。b ∈ R^de 被谨慎初始化,以便在初始化阶段后 ∆ ∈ [∆min, ∆max]。我们设置 [∆min, ∆max] = [0.001, 0.1],并发现这些值对语言建模性能在困惑度指标下不敏感。输入依赖性也引入了 SSM 的参数 B 和 C, 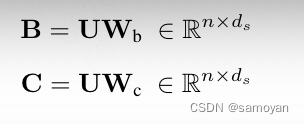 其中 ds 是状态维度。对于每个时间步 1 ≤ t ≤ n,选择性 SSM (S6) 在扩展的状态空间 Zt ∈ R^de×ds 中进行循环推断,即:
其中 ds 是状态维度。对于每个时间步 1 ≤ t ≤ n,选择性 SSM (S6) 在扩展的状态空间 Zt ∈ R^de×ds 中进行循环推断,即: 其中 Z0 = 0,⊙ 表示点乘,⊗ 表示外积,exp 表示点乘自然指数函数。D ∈ R^de 是一个可学习的向量,初始化为 Di = 1,A ∈ R^de×ds 是一个可学习的矩阵,初始化为 Aij = log(j),1 ≤ j ≤ ds,遵循 S4D-Real 初始化。在实践中,Mamba 实现了一个硬件感知的并行扫描算法,用于高效的可并行训练。最终输出通过类似于门控线性单元的门控机制获得,
其中 Z0 = 0,⊙ 表示点乘,⊗ 表示外积,exp 表示点乘自然指数函数。D ∈ R^de 是一个可学习的向量,初始化为 Di = 1,A ∈ R^de×ds 是一个可学习的矩阵,初始化为 Aij = log(j),1 ≤ j ≤ ds,遵循 S4D-Real 初始化。在实践中,Mamba 实现了一个硬件感知的并行扫描算法,用于高效的可并行训练。最终输出通过类似于门控线性单元的门控机制获得,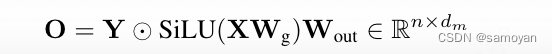 其中 Wg ∈ R^dm×de 和 Wout ∈ R^de×dm 是可学习的参数。在这项工作中,设置 de = 2dm,dr = dm/16,ds = 16。SAMBA 中的 Mamba 层预期能够通过其循环结构捕获输入序列的时间依赖语义。Mamba 层中的输入选择机制使模型能够专注于相关输入,从而使模型能够长期记忆重要信息。
其中 Wg ∈ R^dm×de 和 Wout ∈ R^de×dm 是可学习的参数。在这项工作中,设置 de = 2dm,dr = dm/16,ds = 16。SAMBA 中的 Mamba 层预期能够通过其循环结构捕获输入序列的时间依赖语义。Mamba 层中的输入选择机制使模型能够专注于相关输入,从而使模型能够长期记忆重要信息。
2、滑动窗口注意力(SWA)层
滑动窗口注意力 [BPC20] 层旨在解决 Mamba 层在捕获序列中的非马尔可夫依赖性方面的局限。我们的 SWA 层操作的窗口大小为 w = 2048,该窗口在输入序列上滑动,确保计算复杂度与序列长度呈线性关系。在滑动窗口内应用了 RoPE [SLP+21] 相对位置。通过直接访问上下文窗口中的内容进行注意力处理,SWA 层能够从中到短期历史中检索高清信号,这些信号无法被 Mamba 的循环状态清晰捕获。在这项工作中,我们使用 FlashAttention 2 [Dao23] 来高效实现自注意力。我们还选择了 2048 的滑动窗口大小以考虑效率;根据 [GD23] 中的测量,FlashAttention 2 在 2048 序列长度上的训练速度与 Mamba 的选择性并行扫描相同。
3、多层感知机(MLP)层
SAMBA 中的 MLP 层作为架构的主要非线性变换和事实知识回忆机制 [DDH+22]。我们在本文中训练的所有模型都使用 SwiGLU [Sha20],并将其中间隐藏大小表示为 dp。Samba 对 Mamba 和 SWA 层捕获的不同类型信息应用了独立的多层感知机(MLP)。
4. 优势
- 效率:通过状态空间模型的引入,SAMBA能够在保持低计算复杂度的同时处理长序列数据。
- 灵活性:无限上下文窗口的设计使得SAMBA可以灵活应对各种长度的文本,特别是在需要处理大量上下文信息的复杂任务(如代码理解、多文档问答等)中表现出色。
- 减少注意力稀释:混合注意力机制减少了注意力的稀释,使得模型即使在长文本中也能保持对关键信息的关注。
5. 应用前景
SAMBA模型的设计为处理长文本提供了新的可能性,尤其适合于那些需要大量上下文信息处理的领域,如法律文档分析、编程语言处理、历史数据分析等。此外,它的高效性也使得它有望在移动设备和边缘计算中得到应用。
总之,SAMBA提供了一种创新的方法来解决传统Transformer模型在处理长文本时遇到的问题,其独特的设计和优化使其成为未来语言模型发展的一个重要方向。


















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











