







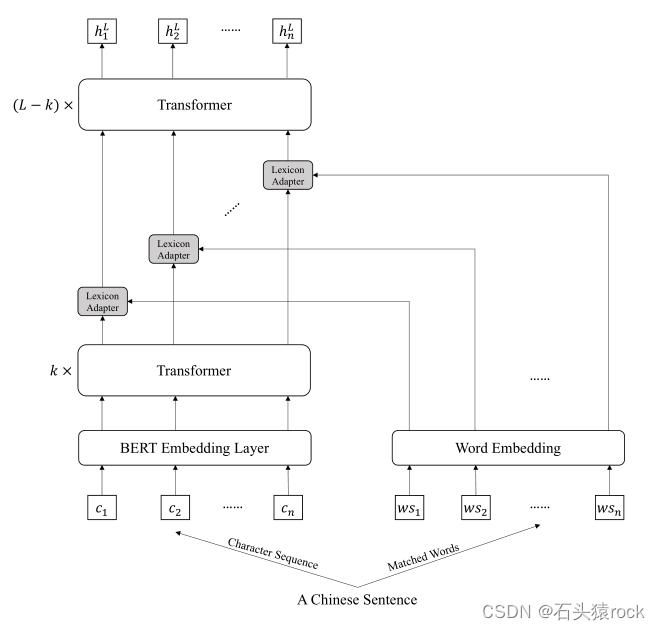
LEBERT中引入词汇信息的方式可以有效提高模型对实体边界和类型的识别性能。LEBERT方法在BERT底层注入词汇信息,可以高效地进行词增强
LEbert在bert的基础上有两点改进:
输入:对于序列中的每一个字符
c
i
c_i
ci都会寻找若干个词
w
i
,
j
w_{i,j}
wi,j,来构成char-word对
通过lexicon adapter来将词汇信息加入到bert的某一层
模型结构
char-words pair:
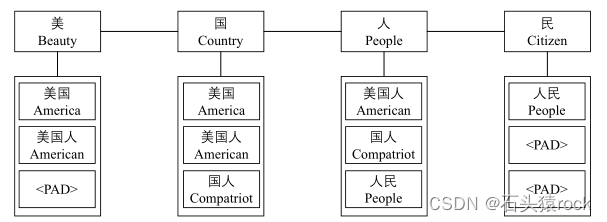
Lexcion Adapter:
将char输出到bert经过几层transformer变换之后,shape将会变为(batch,seq,dim_c)。然后对于每一个char,对其对应的若干个word进行词嵌入,所有的word的shape是:(batch,seq,N,dim_w),N是每个char对应word的数量
接下来对word进行非线性变换:将word向量和char向量进行对其
word向量和char向量维度一致后,通过注意力机制加权各个不同的word向量,加权后word向量的shape为(batch,seq,dim_c),最后把char向量和word向量相加得到新的向量表示,输入到transformer
















 5453
5453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











