







决策树算法
决策树的基本思想与人自身的决策机制很相似,都是基于树结构进行决策,即对于任何问题,我们都先抽出其中的几个主要特征,然后对这些特征一个一个的去考察,从而决定这个问题应该属于的类别。例如我们要去商场买电脑,我们一般要通过考察电脑的CPU,内存,硬盘,显存等这些特征来判断这台电脑是好电脑还是一般电脑,当我们做判断的时候,我们都是首先看这个电脑的CPU怎么样,是i3?i5?还是i7?如果是i7我们就有更大概率倾向于认为这台电脑是好电脑,然后我们再依次考察内存,硬盘,显存等,最终根据这些特征决定其性能的好坏。这样我们就可以构建出一颗决策树来:
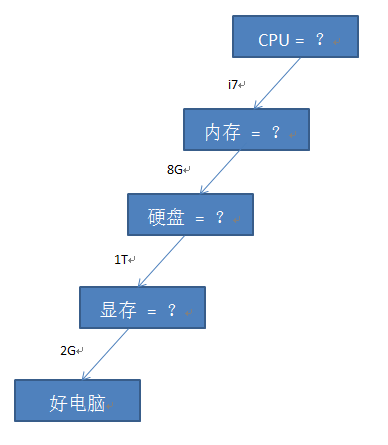
当然,对于不同的人,需求不同,所以对于特征考量的重要性也不同,例如经常玩儿游戏的人会更在乎显存,而经常看电影的则会更加在乎硬盘的大小,这时候由于其需求的不同,对于好电脑的定位也可能会不同,也会构建不同的树。因此决策树算法的核心在于如何选择特征从而构建出我们要想要的决策树从而能够更加通用的去进行分类。为了能够构建决策树,需要介绍特征选择算法,为了能够让构建的决策树更加通用,也就是泛化能力更强,需要介绍剪枝算法
变量定义:
D
——— 样本集合
Y
——— 样本类别集合
特征选择算法
熵与信息增益
在维基百科中,对熵的定义是这样的“entropy (more specifically, Shannon entropy) is the expected value (average) of the information contained in each message.”。我们可以知道熵是用来定义一条消息中所包含的的信息量的,即熵越大,信息量越大,熵越小,信息量越小。那么我们可以知道,如果一个消息中的信息大部分都属于同一个类别,即消息中的信息纯度很高,信息的确定性很大,信息不混乱的时候,信息量是很小的,这时候熵也是很小的;而如果一个消息中包含所有信息且这些信息是均匀分布的,即并没有那个信息占有主导,那么这时候我们可以认为消息中的信息的纯度是很低的,信息的不确定性很大,信息量也很大,因为其包含所有可能的信息,这时候熵应该是最大的。即信息的纯度越高,熵越大,纯度越低,熵越小。
集合
条件熵
信息增益(互信息)
信息增益率
特征选择
ID3 & C4.5
我们在选择特征的时候,都希望所选择的特征能够使得数据的纯度提升最大,不确定性降低最多,最好能够通过该特征的选择使得数据完成分类。通过上面对熵和信息增益的描述我们可以知道,这种描述与信息增益的功效正好相符。因此我们每次选择特征的时候,都希望选择信息增益最大的特征。这种利用信息增益进行选择的算法就是ID3算法。
但是我们可以发现,当使用信息增益进行特征选择的时候,其倾向于选择取值数目多的属性。假设数据集
D
为10台电脑,分别标ID号为
CART算法
CART是Classfication and Regression Tree的简称,其即可以用于分类也可以用于回归,该算法使用的是基尼指数来进行特征的选择
基尼值
基尼值的定义为
基尼指数
对于属性 A ,其基尼指数定义为
剪枝算法
在构建决策树的时候,有时候为了更好的学习训练样本,可能会学过头,使得决策树分支过多,以至于将训练数据自身的一些特征作为了所有数据的一般特征从而导致学习过拟合。因此我们需要一些方法来去掉一些分支从而降低过拟合的风险。
剪枝算法有两种,预剪枝和后剪枝。预剪枝是指在构建决策树的过程中,对每个节点在划分之前进行估计,如果划分无法带来决策树泛化性能的提升,则放弃这次划分,将该节点标记为叶子节点。而后剪枝则是先通过训练集生成一个决策树,然后再自底向上的对非叶子节点进行考察,如果将该节点对应的子树转化为一个叶子节点不会降低泛化性能,则将该子树替换为叶子节点。我们可以看到预剪枝的基本思想是贪心算法,其基于贪心策略防止这些分支的展开,这可能会导致所生成的欠拟合的问题。而后剪枝由于一般会保留比预剪枝更多的分支,因此欠拟合的风险要小很多,泛化性能通常优于预剪枝。但是后剪枝过程是在生成决策树之后,需要从底向上对树中所有非叶子节点都考察一遍,因此其训练时间要比预剪枝和不剪枝都要打很多。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









