







2 拉普拉斯矩阵
2.1 Laplacian matrix的定义
拉普拉斯矩阵(Laplacian matrix)),也称为基尔霍夫矩阵, 是表示图的一种矩阵。给定一个有n个顶点的图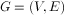
其中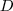
举个例子。给定一个简单的图,如下:
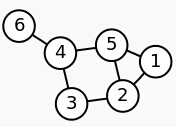
把此“图”转换为邻接矩阵的形式,记为

把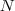


根据拉普拉斯矩阵的定义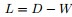

2.2 拉普拉斯矩阵的性质
介绍 拉普拉斯矩阵的性质之前,首先定义两个概念,如下:
①对于邻接矩阵,定义图中A子图与B子图之间所有边的权值之和如下:
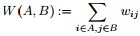
其中,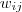

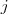
②与某结点邻接的所有边的权值和定义为该顶点的度d,多个d 形成一个度矩阵
拉普拉斯矩阵
,即
。证明:
和非零向量
满足
,则
为
的一个特征向量,
是其对应的特征值)。
- 且对于任何一个属于实向量
,有以下式子成立
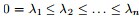
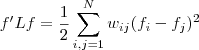
其中,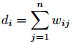
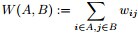
下面,来证明下上述结论,如下:
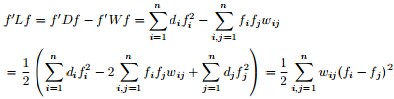
3 谱聚类
所谓聚类(Clustering),就是要把一堆样本合理地分成两份或者K份。从图论的角度来说,聚类的问题就相当于一个图的分割问题。即给定一个图G = (V, E),顶点集V表示各个样本,带权的边表示各个样本之间的相似度,谱聚类的目的便是要找到一种合理的分割图的方法,使得分割后形成若干个子图,连接不同子图的边的权重(相似度)尽可能低,同子图内的边的权重(相似度)尽可能高。物以类聚,人以群分,相似的在一块儿,不相似的彼此远离。
至于如何把图的顶点集分割/切割为不相交的子图有多种办法,如
- cut/Ratio Cut
- Normalized Cut
- 不基于图,而是转换成SVD能解的问题
目的是为了要让被割掉各边的权值和最小,因为被砍掉的边的权值和越小,代表被它们连接的子图之间的相似度越小,隔得越远,而相似度低的子图正好可以从中一刀切断。
本文重点阐述上述的第一种方法,简单提一下第二种,第三种本文不做解释,有兴趣的可以参考文末的参考文献条目13。
3.1 相关定义
为了更好的把谱聚类问题转换为图论问题,定义如下概念(有些概念之前已定义,权当回顾下):
- 无向图
- 与某结点邻接的所有边的权值和定义为该顶点的度d,多个d 形成一个度矩阵
- 邻接矩阵
其中,
- 相似度矩阵的定义。相似度矩阵由权值矩阵得到,实践中一般用高斯核函数(也称径向基函数核)计算相似度,距离越大,代表其相似度越小。
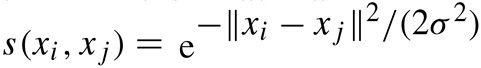
- 子图A的指示向量如下:
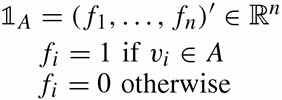
3.2 目标函数
因此,如何切割图则成为问题的关键。换言之,如何切割才能得到最优的结果呢?
举个例子,如果用一张图片中的所有像素来组成一个图 ,并把(比如,颜色和位置上)相似的节点连接起来,边上的权值表示相似程度,现在要把图片分割为几个区域(或若干个组),要求是分割所得的 Cut 值最小,相当于那些被切断的边的权值之和最小,而权重比较大的边没有被切断。因为只有这样,才能让比较相似的点被保留在了同一个子图中,而彼此之间联系不大的点则被分割了开来。
设
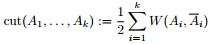
其中k表示分成k个组,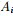
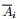
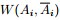
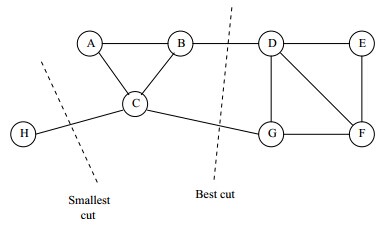
为了让被切断边的权值之和最小,便是要让上述目标函数最小化。但很多时候,最小化cut 通常会导致不好的分割。以分成2类为例,这个式子通常会将图分成了一个点和其余的n-1个点。如下图所示,很明显,最小化的smallest cut不是最好的cut,反而把{A、B、C、H}分为一边,{D、E、F、G}分为一边很可能就是最好的cut:
为了让每个类都有合理的大小,目标函数尽量让A1,A2...Ak 足够大。改进后的目标函数为:
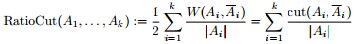
其中|A|表示A组中包含的顶点数目。
或:
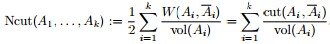
其中,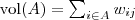
3.3 最小化RatioCut 与最小化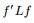 等价
等价
下面,咱们来重点研究下RatioCut 函数。
目标函数:
定义向量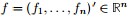
根据之前得到的拉普拉斯矩阵矩阵的性质,已知
现在把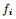
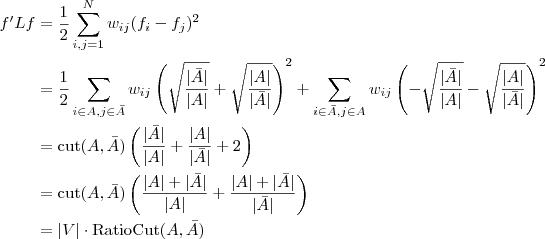
是的,我们竟然从
同时,因单位向量
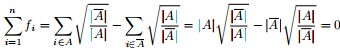
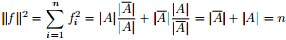
最终我们新的目标函数可以由之前的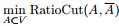
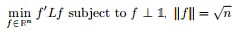
其中,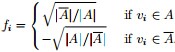
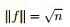
继续推导前,再次提醒特征向量和特征值的定义:
- 若数字
假定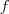
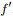
但到了这关键的最后一步,咱们却遇到了一个比较棘手的问题,即由之前得到的拉普拉斯矩阵的性质“

更进一步,由于实际中,特征向量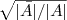

而所要求的这前K个特征向量就是拉普拉斯矩阵的特征向量(计算拉普拉斯矩阵的特征值,特征值按照从小到大顺序排序,特征值对应的特征向量也按照特征值递增的顺序排列,取前K个特征向量,便是我们所要求的前K个特征向量)!
所以,问题就转换成了:求拉普拉斯矩阵的前K个特征值,再对前K个特征值对应的特征向量进行 K-means 聚类。而两类的问题也很容易推广到 k 类的问题,即求特征值并取前 K 个最小的,将对应的特征向量排列起来,再进行 K-means聚类。两类分类和多类分类的问题,如出一辙。
就这样,因为离散求解
3.4 谱聚类算法过程
综上可得谱聚类的算法过程如下:
-
根据数据构造一个Graph,Graph的每一个节点对应一个数据点,将各个点连接起来(随后将那些已经被连接起来但并不怎么相似的点,通过cut/RatioCut/NCut 的方式剪开),并且边的权重用于表示数据之间的相似度。把这个Graph用邻接矩阵的形式表示出来,记为
-
把
。
-
求出
的前
个特征值(前
,以及对应的特征向量
。
-
把这
的矩阵,将其中每一行看作
或许你已经看出来,谱聚类的基本思想便是利用样本数据之间的相似矩阵(拉普拉斯矩阵)进行特征分解( 通过Laplacian Eigenmap 的降维方式降维),然后将得到的特征向量进行 K-means聚类。
此外,谱聚类和传统的聚类方法(例如 K-means)相比,谱聚类只需要数据之间的相似度矩阵就可以了,而不必像K-means那样要求数据必须是 N 维欧氏空间中的向量。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









