







目录

智谱ChatGLM3本地私有化部署
1环境配置和检查
要进行智谱ChatGLM3本地私有化部署,你需要进行以下环境配置和检查:
硬件要求: 确保你的服务器或计算机满足智谱ChatGLM3的硬件要求,包括处理器、内存和存储等方面。
操作系统: 智谱ChatGLM3支持多种操作系统,如Linux、Windows和macOS等。选择适合你的操作系统,并确保它符合智谱ChatGLM3的要求。
Python环境: 安装Python并配置相关环境。智谱ChatGLM3通常需要Python 3.10或更高版本。
GPU支持: 如果你计划使用GPU进行模型训练和推理,你需要安装相应的GPU驱动和CUDA工具包,并确保你的GPU与智谱ChatGLM3兼容。
依赖库安装: 智谱ChatGLM3依赖于一些Python库,如TensorFlow、NumPy等。使用pip或conda等包管理工具,安装所需的依赖库。
模型下载: 下载智谱ChatGLM3的模型文件,这些文件包含了预训练好的模型参数和配置信息。
配置文件: 根据你的需求,修改智谱ChatGLM3的配置文件,包括模型路径、输入输出设置等。
测试和验证: 确保你的环境配置正确无误后,进行简单的测试和验证,确保智谱ChatGLM3可以正常运行。
请注意,智谱ChatGLM3的部署和配置可能会因个人需求和环境而有所差异。建议参考智谱ChatGLM3的官方文档或开发者指南,获取详细的部署步骤和配置说明。
1.1操作系统
ChatGLM3-6B理论上可以在任何主流的操作系统中运行。ChatGLM开发组已经为主流操作系统做了一定的适配。
但是,我们更推荐开发者在 Linux环境下运行我们的代码,以下说明也主要针对Linux系统。
1.2硬件环境
最低要求:
为了能够流畅运行 Int4 版本的 ChatGLM3-6B,我们在这里给出了最低的配置要求:
内存:>= 8GB
显存: >= 5GB(1060 6GB,2060 6GB)
为了能够流畅运行 FP16 版本的,ChatGLM3-6B,我们在这里给出了最低的配置要求:
内存:>= 16GB
显存: >= 13GB(4080 16GB)
Mac开发者无需关注GPU的限制。对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM3-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
如果使用CPU加载,可以忽略显存的要求,但是速度非常慢
1.3软件环境
1.3.1Python环境&检查环境命令
请开发者按照仓库中的requirements.txt来安装对应的依赖,并需要注意:
python 版本推荐3.10.12
transformers 库版本推荐为 4.30.2
torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能
例如检查python环境:
- Python:python3.10 --version 或者 python3.10 -V
- Pip:pip3.10 --version 或者pip3.10 -V
- python与pip版本一致:python3.10 -m pip --version
正确如图:
错误如图:




2快速使用(推理部署)
2.1源码安装与运行
上述两种方案的目的是让更多的用户能够体验到我们的模型,但无法进行二次开发,如果您准备深度使用我们的模型,我们建议按照以下方式安装。
2.2克隆代码和模型
下载源码
模型基础运行代码已经上传到 github 和 SwanHub 两个平台,两个平台的信息同步。开发者通过以下方式下载模型代码。
从 github 下载源码
git clone https://github.com/THUDM/ChatGLM3.git从 SwanHub 下载源码
git clone https://swanhub.co/ZhipuAI/ChatGLM3.git开发者可以通过以下方式下载模型文件
下载模型
下载模型文件前请先确保`git lfs`命令已安装,安装教程请参考这里。
模型文件已上传至 Huggingface, Modelsope , SwanHub 三个平台,用户可以快速安装模型。
若使用 Huggingface 下载模型
(1)windows安装命令:git lfs install
(2)Linux安装命令:
为您的系统配置 packagecloud 存储库后,您可以安装 Git LFS:
| apt/deb:sudo apt-get install git-lfs 百胜/转数:sudo yum install git-lfs 查看版本:git lfs version |
若使用 Modelscope 下载模型
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git若使用 SwanHub 下载模型
git lfs install
git clone https://swanhub.co/ZhipuAI/chatglm3-6b.git2.3检查文件的完整性
- 用户在下载完模型后请检查每个文件的完整性,以下是模型文件的sha256校验码。
# sha256 checksums for chatglm3-6b
4d5567466e89625dbd10e51c69a02982f233a10108cf232a379defdbb065ae0b pytorch_model-00001-of-00007.bin
4ad41534016ac4a2431fa2d4b08efbe28f963744135ec52b2ea13cc86730fa2a pytorch_model-00002-of-00007.bin
a2be9b17c332a8345e787953d4879caee4747ad4b263f013aa3c4654c94c3d24 pytorch_model-00003-of-00007.bin
b5526891e1b4c8edd2e3688df5156aa107e2140fe7e3f9d0d54f9cbe3b6ee3b5 pytorch_model-00004-of-00007.bin
84bb18a476f74beaf4d941733bd1c475791eba799b228f78d0165de989cb7a40 pytorch_model-00005-of-00007.bin
1181875a2dc30fba968d72d0fc4628b9a60d3866bf680eb14b9822b5b504830f pytorch_model-00006-of-00007.bin
1271b638dc0a88206d1c7a51bcaa862410eb56f3e59fd0068a96e96cb5e3f4f0 pytorch_model-00007-of-00007.bin
e7dc4c393423b76e4373e5157ddc34803a0189ba96b21ddbb40269d31468a6f2 tokenizer.model
# sha256 checksums for chatglm3-6b-32k
39aeddd81596b2d66d657687a7328ebc7f8850e8ea83fa74080da59f7d2f7afc pytorch_model-00001-of-00007.bin
2525475ea2d483ecc15a15ad4e016ee0155e628ac66f15cd54daa6c811193e92 pytorch_model-00002-of-00007.bin
faa1d884168a125af5105c4ee4c59fdac79f847b35a7389e0122a562995d34db pytorch_model-00003-of-00007.bin
66492c02ed13189202c7e46a121e308cf0ebbcf8141ecf3d551141aecfac7120 pytorch_model-00004-of-00007.bin
870bb2bb4a289b8ab37cce88f56e93381ff428063b3d0065994a3dd2e830cb32 pytorch_model-00005-of-00007.bin
a5f39ca17ba89e47e484d3b20d4ff78f4fb9b1b24bd3dfb314eff91ff6e37230 pytorch_model-00006-of-00007.bin
7c8a8f3e881202ac3a9ab2638ce30147f67d4bd799624c24af66406a6ba22db2 pytorch_model-00007-of-00007.bin
e7dc4c393423b76e4373e5157ddc34803a0189ba96b21ddbb40269d31468a6f2 tokenizer.model
# sha256 checksums for chatglm3-6b-base
b6a6388dae55b598efe76c704e7f017bd84e6f6213466b7686a8f8326f78ab05 pytorch_model-00001-of-00007.bin
2f96bef324acb5c3fe06b7a80f84272fe064d0327cbf14eddfae7af0d665a6ac pytorch_model-00002-of-00007.bin
2400101255213250d9df716f778b7d2325f2fa4a8acaedee788338fceee5b27e pytorch_model-00003-of-00007.bin
472567c1b0e448a19171fbb5b3dab5670426d0a5dfdfd2c3a87a60bb1f96037d pytorch_model-00004-of-00007.bin
ef2aea78fa386168958e5ba42ecf09cbb567ed3e77ce2be990d556b84081e2b9 pytorch_model-00005-of-00007.bin
35191adf21a1ab632c2b175fcbb6c27601150026cb1ed5d602938d825954526f pytorch_model-00006-of-00007.bin
b7cdaa9b8ed183284905c49d19bf42360037fdf2f95acb3093039d3c3a459261 pytorch_model-00007-of-00007.bin
e7dc4c393423b76e4373e5157ddc34803a0189ba96b21ddbb40269d31468a6f2 tokenizer.model
2.4安装依赖
pip 安装基本依赖
cd ChatGLM3
pip install -r requirements.txt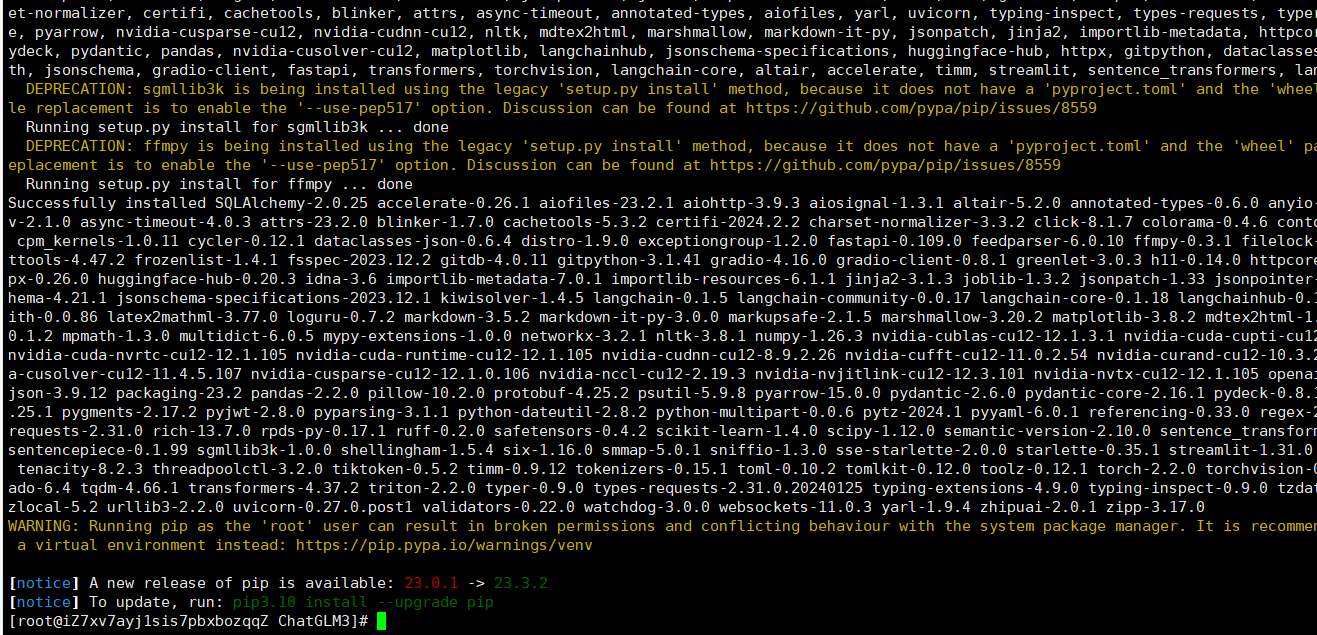
如果你担心你的配置不满足最低配置,你可以访问环境配置和检查获取更多信息。
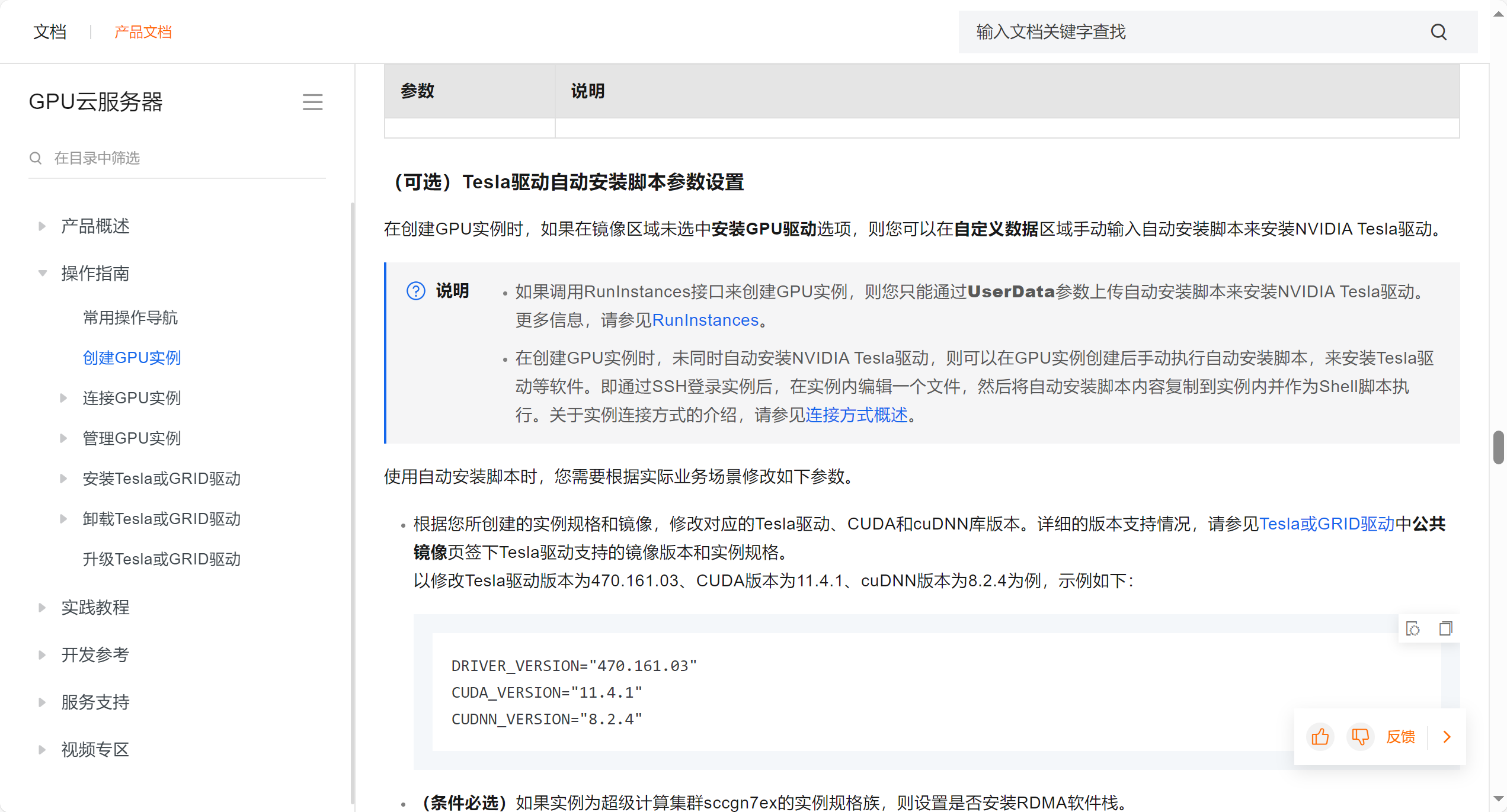
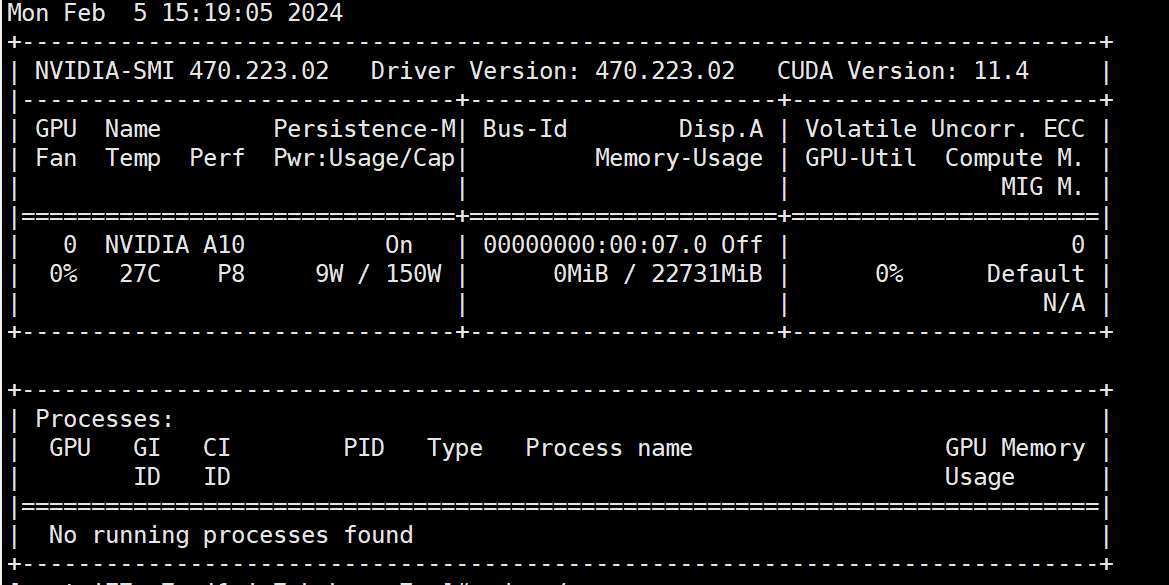
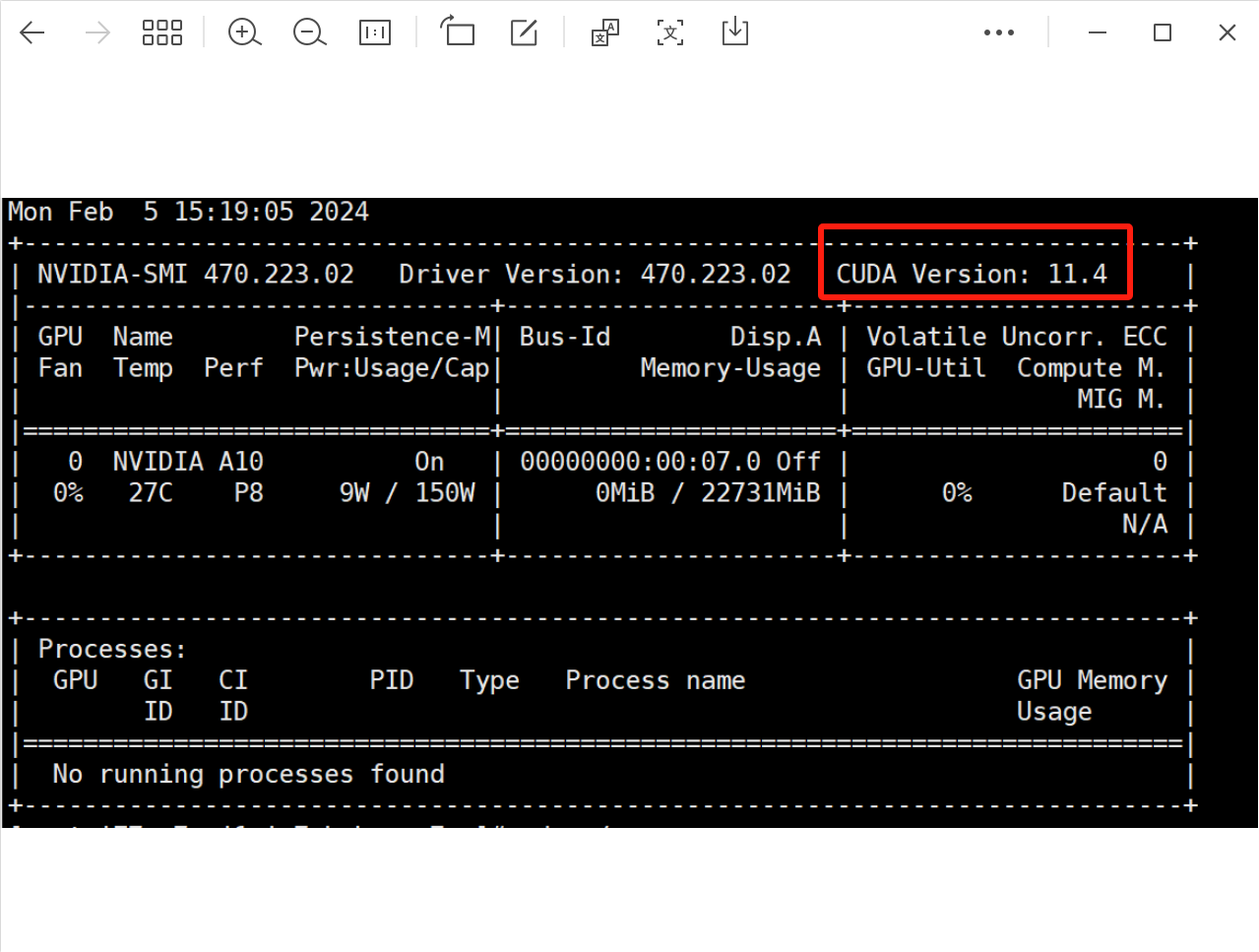
Linux 环境安装cuda
问题描述:显卡的驱动环境没有
问题分析:购买GPU实例及安装驱动_GPU云服务器(EGS)-阿里云帮助中心
解决方案:升级gpu版本(已安装就卸载掉重新安装)
安装方法:
安装Tesla驱动(Linux)_GPU云服务器(EGS)-阿里云帮助中心
2.5运行openai_api_demo目录
启动API接口
(1)激活环境:conda activate xnenv
(2)进入目录:cd /home/chatglm/ChatGLM3/openai_api_demo
(3)启动应用:nohup python api_server.py > openai_api_demo.out &
主要有4个接口能用:
接口1-检查服务健康状态(get):http://127.0.0.1:8000/health
接口2-列出可用模型列表(get):http://127.0.0.1:8000/v1/models/
接口3-处理聊天完整请求(post):http://127.0.0.1:8000/v1/chat/completions
接口4-处理文本输入列表嵌入请求(get):http://192.168.0.129:8000/v1/chat/embeddings
总结:上面只是个人搭建的过程,更多请查看官方文档(
Docs
https://zhipu-ai.feishu.cn/wiki/WvQbwIJ9tiPAxGk8ywDck6yfnof
)


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











